Deep Learning 学习笔记3:《深度学习》线性代数部分
标量:一个标量就是一个单独的数
向量:一个向量是一列数,这些数是有序排列的,比如: ,如果每个元素都属于实数R,且有n个元素,则记为:
,如果每个元素都属于实数R,且有n个元素,则记为: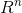 。向量可以看做n维空间的点。
。向量可以看做n维空间的点。
矩阵:二维数组,如果一个矩阵A高度为m,宽度为n,且每个元素都属于实数,则记为:A∈![]()
张量:一组数组中的元素分布在多个坐标中,称其为张量
转置:矩阵转置是以对角线为轴的镜像,从左上角到右下角的对角线称为主对角线。矩阵A的转置记为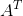 。
。![]()
矩阵和向量相乘:C=AB。矩阵A的形状为m×n,矩阵B的形状为n×p,矩阵C的形状为m×p。
![]()
单位矩阵与逆矩阵:任意向量和单位矩阵相乘,都不会改变。将保持n维向量不变的单位矩阵记作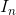 ,
,![]() 。单位矩阵对角线元素为1,其余为0.
。单位矩阵对角线元素为1,其余为0.
A的矩阵逆记作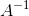 ,定义为:
,定义为:![]()
矩阵A的列向量的所有线性组合叫做A的值域。如果矩阵A中的任意一个向量都不能表示成其他向量的线性组合,则这组向量线性无关。如果一个矩阵的值域包含整个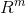 ,则该矩阵中至少包含一组m个线性无关的向量。要想使矩阵可逆,必须保证矩阵至多有m个列向量,即m=n。这意味着该矩阵是一个方阵,并且所有列向量都是线性无关的。一个列向量线性相关的方阵被称为奇异矩阵。
,则该矩阵中至少包含一组m个线性无关的向量。要想使矩阵可逆,必须保证矩阵至多有m个列向量,即m=n。这意味着该矩阵是一个方阵,并且所有列向量都是线性无关的。一个列向量线性相关的方阵被称为奇异矩阵。
范数:将向量映射到非负值的函数。向量x的范数是衡量从原点到x的距离。

当p=2时, 被称为欧几里得范数。表示从原点出发到向量X确定的点的欧几里得距离。
被称为欧几里得范数。表示从原点出发到向量X确定的点的欧几里得距离。
Frobenius范数:形容矩阵的大小,如下:

对角矩阵:主对角线上含有非零元素,其他位置都是零。即对于所有的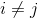 ,有
,有![]() 。
。
用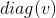 表示一个对角元素由向量v中元素给定的对角方阵。计算乘法
表示一个对角元素由向量v中元素给定的对角方阵。计算乘法![]() ,只需要将x中每个元素
,只需要将x中每个元素 放大
放大 倍。对角矩阵不一定是方阵。
倍。对角矩阵不一定是方阵。
对称矩阵:转置后和自己相等的矩阵。
在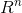 中,如果有n个向量互相正交,且范数都为1,则称他们为标准正交。正交矩阵是指行向量和列向量都是标准正交的方阵。
中,如果有n个向量互相正交,且范数都为1,则称他们为标准正交。正交矩阵是指行向量和列向量都是标准正交的方阵。
![]()
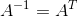
特征分解:将矩阵分解成一组特征向量和特征值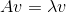 方阵A的特征向量是指与A相乘后相当于对该向量进行缩放的非零向量v:
方阵A的特征向量是指与A相乘后相当于对该向量进行缩放的非零向量v:
标量 被称为这个特征向量对应的特征值。
被称为这个特征向量对应的特征值。
假设矩阵A有n个线性无关的特征向量![]() ,对应着特征值
,对应着特征值 ![]() ,我们将特征向量连接一个矩阵,使得每一列是一个特征向量,则V=
,我们将特征向量连接一个矩阵,使得每一列是一个特征向量,则V=![]() 。同时将特征值连接成一个向量
。同时将特征值连接成一个向量 ![]() 。因此A的特征分解可以表示为:
。因此A的特征分解可以表示为:
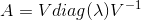
所有特征值都是正数的矩阵被称为正定,所有特征值都是非负数的矩阵被称为半正定(positive semidefinite)。同样地,所有特征值都是负数的矩阵被称为负定(negative definite);所有特征值都是非正数的矩阵被称为半负定(negative semidefinite).
奇异值分解(SVD):将矩阵分解为奇异向量和奇异值。每个实数矩阵都有一个奇异值分解,但不一定有特征分解。非方阵的矩阵没有特征分解,但可以使用奇异值分解。奇异值分解公式如下:

假设A是一个m×n的矩阵,那么U是一个m×m的矩阵,D是一个m×n的矩阵,V是一个n×n的矩阵。矩阵U和V都是正交矩阵,D是对角矩阵,但不一定是方阵。对角矩阵D 对角线上的元素被称为矩阵A 的奇异值。矩阵U 的列向量被称为左奇异向量(left singular vector),矩阵V 的列向量被称右奇异向量(right singular vector)。
A的左奇异向量是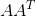 的特征向量。A的右奇异向量是
的特征向量。A的右奇异向量是 的特征向量。A的非零奇异值是特征值的平方根,同时也是特征值的平方根。
的特征向量。A的非零奇异值是特征值的平方根,同时也是特征值的平方根。
求解![]() ,如果A是非方阵矩阵,逆矩阵没有定义。只能通过伪逆的方式求解。
,如果A是非方阵矩阵,逆矩阵没有定义。只能通过伪逆的方式求解。![]()
矩阵A的伪逆定义为:
![]()
或者定义如下:
![]()
对角矩阵D的伪逆是其非零元素取倒数后再转置得到的。
迹运算:迹运算返回的是矩阵对角元素之和:
![]()
将矩阵中最后一个挪到最前面之后乘积的迹是相同的。前提是挪动之后矩阵定义依然良好:

行列式:行列式,记作det(A),是一个将方阵A 映射到实数的函数。行列式等于矩阵特征值的乘积。行列式的绝对值可以用来衡量矩阵相乘后空间扩大或者缩小了多少。如果行列式是0, 那么空间至少沿着某一维完全收缩了,使其失去了所有的体积。如果行列式是1, 那么矩阵相乘没有改变空间体积。