spark core试题
(第八题后续补上)
-
spark任务程序,将任务提交集群运行。(参数指定)(10)
spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ ./examples/jars/spark-examples_2.11-2.1.1.jar \ 100 -
写出下列代码的打印结果。(5分)
def joinRdd(sc:SparkContext) { val name= Array((1,"spark"),(2,"flink"),(3,"hadoop")**,(4,”java”))** val score= Array((1,100),(2,90),(3,80)**,(5,90))** val namerdd=sc.parallelize(name); val scorerdd=sc.parallelize(score); val result = namerdd.join(scorerdd); result.collect.foreach(println); } //答案:(spark,100),(flink,90),(hadoop,80) -
写出触发shuffle的算子(至少五个)(5分)
def distinct() ef reduceByKey def groupByKey def groupBy sortByKey def join -
RDD的概念和特性(10分)
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据抽象。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
官网解释:
1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
4)一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
5)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
总结特点:
弹性
存储的弹性:内存与磁盘的自动切换;
容错的弹性:数据丢失可以自动恢复;
计算的弹性:计算出错重试机制;
分片的弹性:可根据需要重新分片。
分区
RDD 逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个 compute 函数得到每个分区的数据。如果 RDD 是通过已有的文件系统构建,则 compute 函数是读取指定文件系统中的数据,如果 RDD 是通过其他 RDD 转换而来,则 compute 函数是执行转换逻辑将其他RDD 的数据进行转换。
只读
RDD 是只读的,要想改变RDD 中的数据,只能在现有的RDD 基础上创建新的 RDD。
由一个 RDD 转换到另一个 RDD,可以通过丰富的操作算子实现,不再像 MapReduce
那样只能写map 和 reduce 了。
依赖
RDDs 通过操作算子进行转换,转换得到的新 RDD 包含了从其他 RDDs 衍生所必需的信息,RDDs 之间维护着这种血缘关系,也称之为依赖。如下图所示,依赖包括两种,一种是窄依赖,RDDs 之间分区是一一对应的,另一种是宽依赖,下游 RDD 的每个分区与上游
RDD(也称之为父 RDD)的每个分区都有关,是多对多的关系。
缓存
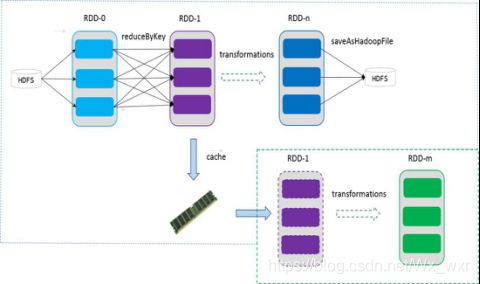
如果在应用程序中多次使用同一个RDD,可以将该RDD 缓存起来,该 RDD 只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该RDD 的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。如下图所示,RDD-
1 经过一系列的转换后得到 RDD-n 并保存到 hdfs,RDD-1 在这一过程中会有个中间结果, 如果将其缓存到内存,那么在随后的 RDD-1 转换到 RDD-m 这一过程中,就不会计算其之前的RDD-0 了。
CheckPoint
虽然 RDD 的血缘关系天然地可以实现容错,当 RDD 的某个分区数据失败或丢失,可以通过血缘关系重建。但是对于长时间迭代型应用来说,随着迭代的进行,RDDs 之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD 支持 checkpoint 将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为checkpoint 后的RDD 不需要知道它的父RDDs 了,它可以从checkpoint 处拿到数据。
- 写出spark集群的启动程序步骤(从配置开始到启动)(10分)
解压spark到节点上,打开conf目录,修改spark-env.sh(根据自己的节点的配置和版本还有路径修改)
export JAVA_HOME=/usr/java/jdk1.8.0_141
export SCALA_HOME=/usr/scala-2.12.8
export HADOOP_HOME=/usr/local/hadoop-2.7.2
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.2/etc/hadoop
export SPARK_MASTER_IP=SparkMaster
export SPARK_WORKER_MEMORY=4g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
修改 conf/slaves 添加节点名(映射)
最后在spark目录start-all.sh (集群已启动)
- 写出Transformtion算子和Action算子的区别(举例说明)(10分)
1,transformation是得到一个新的RDD,方式很多,比如从数据源生成一个新的RDD,从RDD生成一个新的RDD
2,action是得到一个值,或者一个结果(直接将RDDcache到内存中)所有的transformation都是采用的懒策略,就是如果只是将transformation提交是不会执行计算的,计算只有在action被提交的时候才被触发。
- 画图讲解spark提交任务的底层原理(10分)

- 统计下面语句中,Spark的出现次数,哪个单词出现的次数最多。(10分)
Get Spark from the downloads page of the project website This documentation is for Spark version Spark uses Hadoop s client libraries for HDFS and YARN.Downloads are pre packaged for a handful of popular Hadoop versions Users can also download a Hadoop free binary and run Spark with any Hadoop version by augmenting Spark s classpath Scala and Java users can include Spark in their projects using its Maven coordinates and in the future Python users can also install Spark from PyPI
- 有如下数据
Val list = List((“jack”,100),(“jack”,80),(“tom”,88),(“jack”,56),(“tom”,66),(“tom”,78),(“tom”,99))
需求:进行分组取Top2(手写代码实现)(10分)
object top2 {
def main(args: Array[String]): Unit = {
val list = List(("jack",100),("jack",80),("tom",88),("jack",56),("tom",66),("tom",78),("tom",99))
val maps = list.groupBy(_._1)
val top = maps.map( t => {
val key = t._1
val values = t._2.toList.sorted.reverse.take(2)
(key,values)
})
top.foreach(println)
}
}
- Spark有几种Shuffle,并说明其原理实现(10分)
HashShuffle
HashShuffle 1.6版本之前的一个shuffle操作,在1.6以后就退出历史舞台
HashShuffle的两大死穴:第一:Shuffle前会产生海量的小文件于磁盘之上,此时会产生大量耗时低效的IO操作;第二:内存不共用!!!
由于内存中需要保存海量的文件操作句柄和临时缓存信息,如果数据处理规模比较庞大的话,内存不可承受,出现OOM等问题!
SortShuffle
SortShuffle 1.6版本以后,默认的shuffle
把小文件合并,此时Shuffle时文件产生的数量为cores*R,对于ShuffleMapTask的数量明显多于同时可用的并行Cores的数量的情况下,
Shuffle产生的文件会大幅度减少,会极大降低OOM的可能
钨丝Shuffle
钨丝Shuffle 2.0以后版本才推出的新版shuffle,这个shuffle和spark的内存模型有关系。
优化点主要在三个方面:
直接在serialized binary data上sort而不是java objects,减少了memory的开销和GC的overhead。
提供cache-efficient sorter,使用一个8bytes的指针,把排序转化成了一个指针数组的排序。
spill的merge过程也无需反序列化即可完成
这些优化的实现导致引入了一个新的内存管理模型,类似OS的Page,对应的实际数据结构为MemoryBlock,支持off-heap 以及 in-heap 两种模式。为了能够对Record 在这些MemoryBlock进行定位,引入了Pointer(指针)的概念
- 谈谈你对广播变的理解和它的使用场景(10分)
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个 Spark 操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,甚至是机器学习算法中的一个很大的特征向量,广播变量用起来都很顺手。 在多个并行操作中使用同一个变量,但是 Spark 会为每个任务分别发送。
广播变量广播的值,必须是只读的。如我当我们程序有外部变量的时候,就用广播方式广播出去就行了,这样可以提高性能
广播变量的取值方式 .value
这样理解, 一个worker中的executor,有5个task运行,假如5个task都需要这从份共享数据,就需要向5个task都传递这一份数据,那就十分浪费网络资源和内存资源了。使用了广播变量后,只需要向该worker传递一次就可以了。
val genderMapBC:Broadcast[Map[String, String]] = sc.broadcast(genderMap)