Spark 中的累加器及广播变量
一、累加器
1、原理
累加器用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在 Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后,传回 Driver 端进行 merge。
2、系统累加器
package spark.core.accumulator
import org.apache.spark.{SparkConf, SparkContext}
/**
* 系统自带累加器
*/
object Spark_OS_Accumulator_Study1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().
setMaster("local[*]").
set("spark.driver.host", "localhost").
setAppName("rdd")
val sc = new SparkContext(sparkConf)
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5))
// 声明累加器
// 使用累加器,可以避免 shuffle 操作,提高效率。
val sum = sc.longAccumulator("sum");
rdd.foreach(
num => {
// 使用累加器
sum.add(num)
}
)
// 获取累加器的值
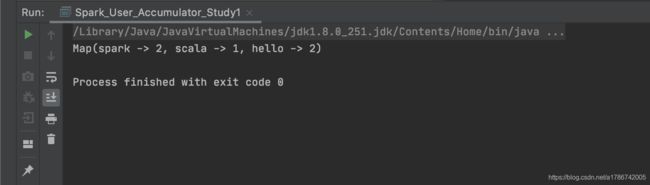
println("sum = " + sum.value)
}
}
运行结果:
3、自定义累加器
package spark.core.accumulator
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
/**
* 自定义累加器
* 1、创建累加器
* 2、注册累加器
*/
object Spark_User_Accumulator_Study1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().
setMaster("local[*]").
set("spark.driver.host", "localhost").
setAppName("rdd")
val sc = new SparkContext(sparkConf)
// 累加器:wordcount 的实现
val rdd: RDD[String] = sc.makeRDD(List("hello spark", "scala", "spark", "hello"))
// 1、创建累加器
val acc = new WordCountAccumulator
// 2、注册累加器
sc.register(acc)
// 3、使用累加器
rdd.flatMap(_.split(" ")).foreach(
word => {
acc.add(word)
}
)
// 4、获取累加器的值
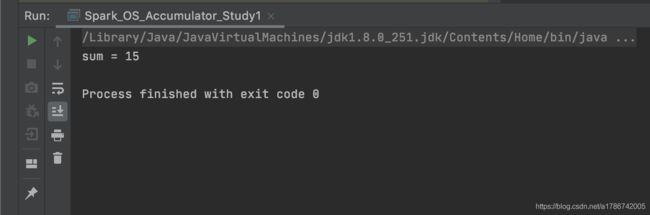
println(acc.value)
}
class WordCountAccumulator extends AccumulatorV2[String, mutable.Map[String,Long]] {
var map: mutable.Map[String, Long] = mutable.Map()
// 累加器是否为初始状态
override def isZero: Boolean = {
map.isEmpty
}
// 复制累加器
override def copy(): AccumulatorV2[String, mutable.Map[String,Long]] = {
new WordCountAccumulator
}
// 重置累加器
override def reset(): Unit = {
map.clear()
}
// 向累加器中增加数据(In)
override def add(word : String): Unit = {
// 查询 map 中是否有相同的单词
// 如果有相同的单词,那么单词的个数加 1
// 如果没有相同的单词,那么在 map 中增加这个单词
map(word) = map.getOrElse(word, 0L) + 1L
}
// 合并累加器
override def merge(other: AccumulatorV2[String, mutable.Map[String,Long]]): Unit = {
val map1 = map
val map2 = other.value
// 两个 Map 的合并
map = map1.foldLeft(map2)(
(innerMap,kv) => {
innerMap(kv._1) = innerMap.getOrElse(kv._1, 0L) + kv._2
innerMap
}
)
}
// 返回累加器的结果(Out)
override def value: mutable.Map[String,Long] = map
}
}
二、广播变量
1、原理
广播变量用来高效分发较大的对象,向所有工作节点发送一个较大的只读值,以供一个或多个 Spark 操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量用起来都很顺手。在多个并行操作中使用同一个变量,但是 Spark 会为每个任务分别发送。
2、代码
package spark.core.accumulator
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
/**
* 自定义累加器
* 1、创建累加器
* 2、注册累加器
*/
object Spark_User_Accumulator_Study1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().
setMaster("local[*]").
set("spark.driver.host", "localhost").
setAppName("rdd")
val sc = new SparkContext(sparkConf)
// 累加器:wordcount 的实现
val rdd: RDD[String] = sc.makeRDD(List("hello spark", "scala", "spark", "hello"))
// 1、创建累加器
val acc = new WordCountAccumulator
// 2、注册累加器
sc.register(acc)
// 3、使用累加器
rdd.flatMap(_.split(" ")).foreach(
word => {
acc.add(word)
}
)
// 4、获取累加器的值
println(acc.value)
}
class WordCountAccumulator extends AccumulatorV2[String, mutable.Map[String,Long]] {
var map: mutable.Map[String, Long] = mutable.Map()
// 累加器是否为初始状态
override def isZero: Boolean = {
map.isEmpty
}
// 复制累加器
override def copy(): AccumulatorV2[String, mutable.Map[String,Long]] = {
new WordCountAccumulator
}
// 重置累加器
override def reset(): Unit = {
map.clear()
}
// 向累加器中增加数据(In)
override def add(word : String): Unit = {
// 查询 map 中是否有相同的单词
// 如果有相同的单词,那么单词的个数加 1
// 如果没有相同的单词,那么在 map 中增加这个单词
map(word) = map.getOrElse(word, 0L) + 1L
}
// 合并累加器
override def merge(other: AccumulatorV2[String, mutable.Map[String,Long]]): Unit = {
val map1 = map
val map2 = other.value
// 两个 Map 的合并
map = map1.foldLeft(map2)(
(innerMap,kv) => {
innerMap(kv._1) = innerMap.getOrElse(kv._1, 0L) + kv._2
innerMap
}
)
}
// 返回累加器的结果(Out)
override def value: mutable.Map[String,Long] = map
}
}
运行结果: