Elasticsearch(八)elasticsearch数据输入和输出
Elastcisearch 是分布式的 文档 存储。它能存储和检索复杂的数据结构–序列化成为JSON文档–以 实时 的方式。 换句话说,一旦一个文档被存储在 Elasticsearch 中,它就是可以被集群中的任意节点检索到。
在 Elasticsearch 中, 每个字段的所有数据 都是 默认被索引的 。 即每个字段都有为了快速检索设置的专用倒排索引。而且,不像其他多数的数据库,它能在 相同的查询中 使用所有这些倒排索引,并以惊人的速度返回结果。
文档
不同于传统数据库,为了完美表现对象的灵活性,elasticsearch使用JSON这种标准格式,以一种人可读的文本表示对象。
在大多数应用中,多数实体或对象可以被序列化为包含键值对的 JSON 对象。 一个 键 可以是一个字段或字段的名称,一个 值 可以是一个字符串,一个数字,一个布尔值, 另一个对象,一些数组值,或一些其它特殊类型诸如表示日期的字符串,或代表一个地理位置的对象:
{
"name": "John Smith",
"age": 42,
"confirmed": true,
"join_date": "2014-06-01",
"home": {
"lat": 51.5,
"lon": 0.1
},
"accounts": [
{
"type": "facebook",
"id": "johnsmith"
},
{
"type": "twitter",
"id": "johnsmith"
}
]
}
在 Elasticsearch 中,术语 文档 有着特定的含义。它是指最顶层或者根对象, 这个根对象被序列化成 JSON 并存储到 Elasticsearch 中,指定了唯一 ID。
字段的名字可以是任何合法的字符串,但不可以包含时间段
文档元数据
一个文档不仅仅包含它的数据 ,也包含 元数据 —— 有关 文档的信息。 三个必须的元数据元素如下:
_index 文档在哪存放 _type 文档表示的对象类别 _id 文档唯一标识
索引
这是一种逻辑上的命名,实际文档存储在分片中,一个索引中包含多个分片。这种命名是为了我们更好的理解,它表示一类共性事务的集合。比如说产品一类都放入一个索引,索引为product。
类型
也是为了更好的理解,在同一个索引下(同一类事务下),不同种类的数据的逻辑区分。例如一个product产品索引下,有玩具类型(type = toy)的产品,也可以有食品类型的(type=food)的产品,他们在同一索引下,因为他们是同一类事务下有共性特征的产品,比如他们都有价格,都有成本,都有生产日期等。
id
标识。和索引,类型组合就可以唯一确定当前的产品了。
索引文档
在创建一个新的文档的时候,你可以选择自定义id或是让elasticsearch为你自动生成一个文档id
自定义id
在put语法后增加自定义的id
PUT /{index}/{type}/{id}
{
"field": "value",
...
}
Head插件示例
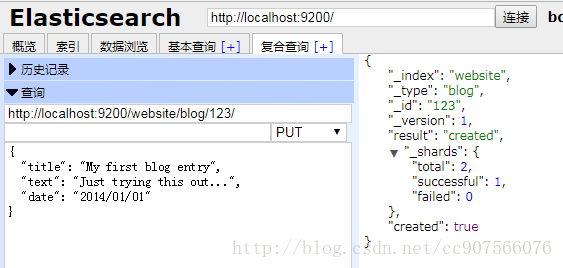
会发现自动增加了索引和类型,也就是自动成功索引了:
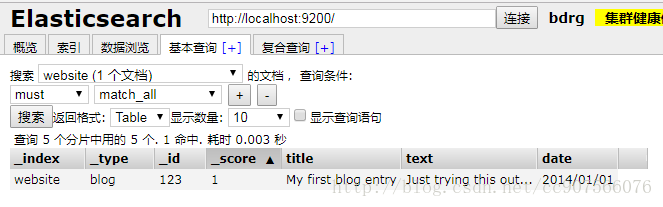
Client程序演示
客户端示例之前介绍过:
client.prepareIndex("website","blog","123")//index type id(表特定雇员)
.setSource(XContentFactory.jsonBuilder()
.startObject()
.field("title","My first blog entry")
.field("text","Just trying this out")
.field("date","2014/01/01")
.endObject()).get();
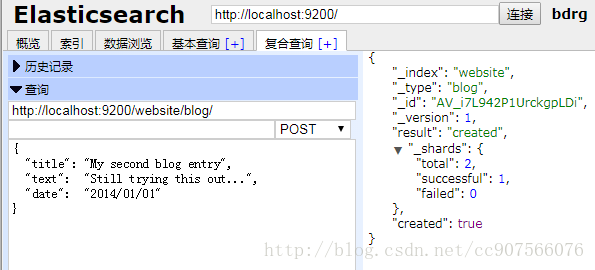
自动生成id
在post后不增加自定义id
POST /{index}/{type}/
{
"field": "value",
...
}自动生成的 ID 是 URL-safe、 基于 Base64 编码且长度为20个字符的 GUID 字符串。 这些 GUID 字符串由可修改的 FlakeID 模式生成,这种模式允许多个节点并行生成唯一 ID ,且互相之间的冲突概率几乎为零,大概长这样:AVFgSgVHUP18jI2wRx0w
创建文档操作会响应一个新的_version元素,在 Elasticsearch 中每个文档都有一个版本号。当每次对文档进行修改时(包括删除), _version 的值会递增。
Head插件示例
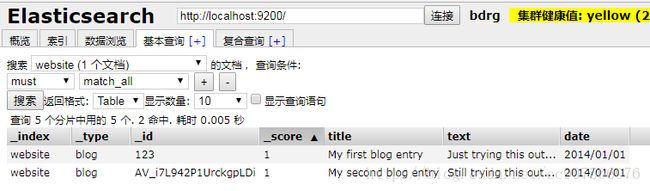
Client程序演示
Client示例:不写id即可,其他相同
client.prepareIndex("website1","blog1")//index type (表特定雇员)
.setSource(XContentFactory.jsonBuilder()
.startObject()
.field("title","My first blog entry")
.field("text","Just trying this out")
.field("date","2014/01/01")
.endObject()).get();
创建新文档
当我们索引一个文档, 怎么确认我们正在创建一个完全新的文档,而不是覆盖现有的呢?
1.确保创建一个新文档的最简单办法是,使用索引请求的 POST 形式让 Elasticsearch 自动生成唯一 _id
2.然而,如果已经有自己的 _id ,那么我们必须告诉 Elasticsearch ,只有在相同的 _index 、 _type 和 _id 不存在时才接受我们的索引请求。这里有两种方式,他们做的实际是相同的事情。使用哪种,取决于哪种使用起来更方便。
第一种方法使用 op_type 查询 -字符串参数:
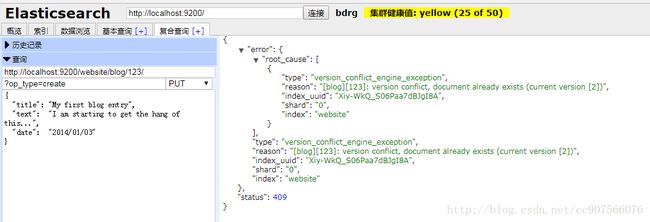
PUT /website/blog/123?op_type=create
{ … }
第二种方法是在 URL 末端使用 /_create :
PUT /website/blog/123/_create
{ … }
如果创建新文档的请求成功执行,Elasticsearch 会返回元数据和一个 201 Created 的 HTTP 响应码。
另一方面,如果具有相同的 _index 、 _type 和 _id 的文档已经存在,Elasticsearch 将会返回 409 Conflict 响应码,以及如下的错误信息:
{
“error”: {
“root_cause”: [
{
“type”: “document_already_exists_exception”,
“reason”: “[blog][123]: document already exists”,
“shard”: “0”,
“index”: “website”
}
],
“type”: “document_already_exists_exception”,
“reason”: “[blog][123]: document already exists”,
“shard”: “0”,
“index”: “website”
},
“status”: 409
}
Head插件示例
第一种方法:
第二种方法:

Client程序演示
增加新方法:
// 确认ID不存在才索引 设置OpType为CREATE
private static void insertBlogConfirmID(Client client) throws IOException {
IndexResponse response = client.prepareIndex("website1","blog1","1")//index type id(表特定雇员)
.setSource(XContentFactory.jsonBuilder()
.startObject()
.field("title","My first blog entry")
.field("text","Just trying this out")
.field("date","2014/01/01")
.endObject())
.setOpType(OpType.CREATE).get();
System.out.println(response);
}
调用:
// 5.确认ID不存在才索引
insertBlogConfirmID(client);结果显示:
客户端操作错误:[blog1][1]: version conflict, document already exists (current version [1])
搜索一个文档
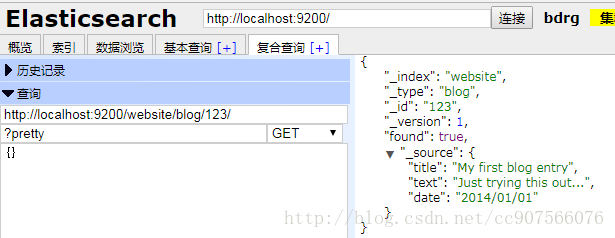
get语法后加上元数据索引
GET /{index}/{type}/{id}响应会在_source中表现出我们索引的文档,GET 请求的响应体包括 {“found”: true} ,这证实了文档已经被找到。 如果我们请求一个不存在的文档,我们仍旧会得到一个 JSON 响应体,但是 found 将会是 false 。 此外, HTTP 响应码将会是 404 Not Found ,而不是 200 OK 。
Head插件示例
Client程序演示
Client示例之前学习过:
GetResponse response3 = client.prepareGet(index, type, id).execute().actionGet();
System.out.println(response3.getSourceAsString());//这是_source部分
一部分文档返回
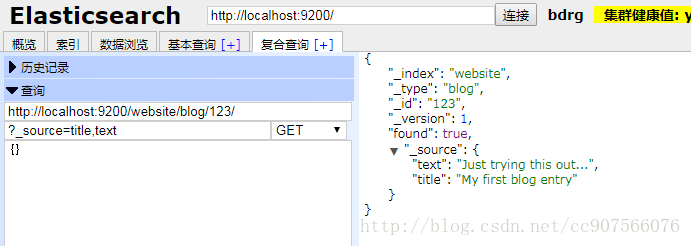
默认情况下, GET 请求 会返回整个文档,这个文档正如存储在 _source 字段中的一样。但是也许你只对其中的 title 字段感兴趣。单个字段能用 _source 参数请求得到,多个字段也能使用逗号分隔的列表来指定。
GET /website/blog/123?_source=title,text
该 _source 字段现在包含的只是我们请求的那些字段,并且已经将 date 字段过滤掉了。
{
“_index” : “website”,
“_type” : “blog”,
“_id” : “123”,
“_version” : 1,
“found” : true,
“_source” : {
“title”: “My first blog entry” ,
“text”: “Just trying this out…”
}
}
Head插件示例
或者,如果你只想得到 _source 字段,不需要任何元数据,你能使用 _source 端点:
GET /website/blog/123/_source
View in Sense
那么返回的的内容如下所示:
{
“title”: “My first blog entry”,
“text”: “Just trying this out…”,
“date”: “2014/01/01”
}
Client程序演示
增加一个方法:
/**
* 检索部分文档 在客户端中使用_source返回指定的字段
* SearchRequestBuilder.setFetchSource(inludes,excludes);可指示显示返回和不返回的字段
* @param client
* @param index
* @param type
* @param id
*/
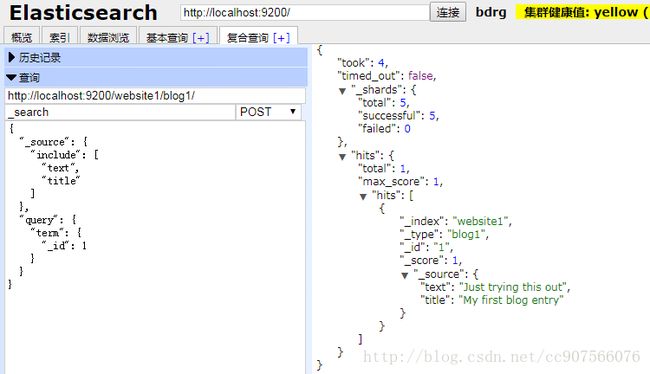
private static void getPartBlogByPK(Client client, String index, String type, String id) {
SearchRequestBuilder srb = new SearchRequestBuilder(client,SearchAction.INSTANCE);
srb.setIndices(index);
srb.setTypes(type);
srb.setQuery(QueryBuilders.termQuery("_id", id));
srb.setFetchSource(new String[] {"title","text"}, null);
SearchResponse response = srb.get();
System.out.println(response);
}
Main方法增加调用:
// 4.检索部分文档
getPartBlogByPK(client,"website1","blog1","1");
结果显示:
{“took”:3,”timed_out”:false,”_shards”:{“total”:5,”successful”:5,”failed”:0},”hits”:{“total”:1,”max_score”:1.0,”hits”:[{“_index”:”website1”,”_type”:”blog1”,”_id”:”1”,”_score”:1.0,”_source”:{“text”:”Just trying this out”,”title”:”My first blog entry”}}]}}
可看到_source只返回text和tile字段
检查文档是否存在
如果只想检查一个文档是否存在 –根本不想关心内容–那么用 HEAD 方法来代替 GET 方法。 HEAD 请求没有返回体,只返回一个 HTTP 请求报头:
curl -i -XHEAD http://localhost:9200/website/blog/123
如果文档存在, Elasticsearch 将返回一个 200 ok 的状态码:
HTTP/1.1 200 OK
Content-Type: text/plain; charset=UTF-8
Content-Length: 0
若文档不存在, Elasticsearch 将返回一个 404 Not Found 的状态码:
curl -i -XHEAD http://localhost:9200/website/blog/124
HTTP/1.1 404 Not Found
Content-Type: text/plain; charset=UTF-8
Content-Length: 0
当然,一个文档仅仅是在检查的时候不存在,并不意味着一毫秒之后它也不存在:也许同时正好另一个进程就创建了该文档。
更新整个文档
在 Elasticsearch 中文档是 不可改变 的,不能修改它们。 相反,如果想要更新现有的文档,需要 重建索引 或者进行替换
只需put语法后id参数是已有的,那么传递过去的文档将会将就文档替换掉
PUT /website/blog/123
{
“title”: “My first blog entry”,
“text”: “I am starting to get the hang of this…”,
“date”: “2014/01/02”
}
在响应体中,我们能看到 Elasticsearch 已经增加了 _version 字段值:
{
“_index” : “website”,
“_type” : “blog”,
“_id” : “123”,
“_version” : 2,
“created”: false
}

created 标志设置成 false ,是因为相同的索引、类型和 ID 的文档已经存在。
在内部,Elasticsearch 已将旧文档标记为已删除,并增加一个全新的文档。 尽管你不能再对旧版本的文档进行访问,但它并不会立即消失。当继续索引更多的数据,Elasticsearch 会在后台清理这些已删除文档。
文档的部分更新
它其实可以表面理解为一种合并文档的操作(结果来看),
然而在内部, update API 简单使用与之前描述相同的 检索-修改-重建索引 的处理过程。 区别在于这个过程发生在分片内部,这样就避免了多次请求的网络开销。通过减少检索和重建索引步骤之间的时间,我们也减少了其他进程的变更带来冲突的可能性。
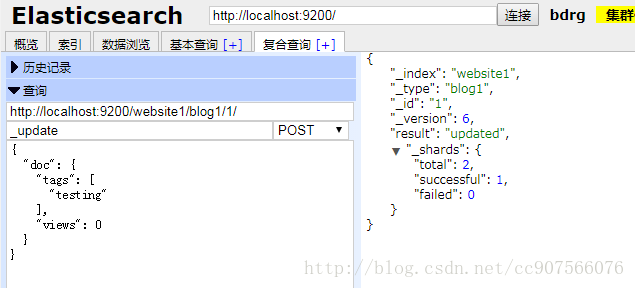
POST /website/blog/1/_update
{
"doc" : {
"tags" : [ "testing" ],
"views": 0
}
}
在 更新整个文档 , 我们已经介绍过 更新一个文档的方法是检索并修改它,然后重新索引整个文档,这的确如此。然而,使用 update API 我们还可以部分更新文档,例如在某个请求时对计数器进行累加。
我们也介绍过文档是不可变的:他们不能被修改,只能被替换。 update API 必须遵循同样的规则。 从外部来看,我们在一个文档的某个位置进行部分更新。然而在内部, update API 简单使用与之前描述相同的 检索-修改-重建索引 的处理过程。 区别在于这个过程发生在分片内部,这样就避免了多次请求的网络开销。通过减少检索和重建索引步骤之间的时间,我们也减少了其他进程的变更带来冲突的可能性。
update 请求最简单的一种形式是接收文档的一部分作为 doc 的参数, 它只是与现有的文档进行合并。对象被合并到一起,覆盖现有的字段,增加新的字段。 例如,我们增加字段 tags 和 views 到我们的博客文章,如下所示:
POST /website/blog/1/_update
{
“doc” : {
“tags” : [ “testing” ],
“views”: 0
}
}
如果请求成功,我们看到类似于 index 请求的响应:
{
“_index” : “website”,
“_id” : “1”,
“_type” : “blog”,
“_version” : 3
}
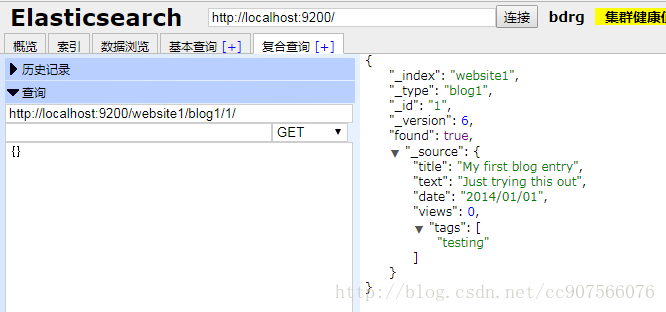
检索文档显示了更新后的 _source 字段:
{
“_index”: “website”,
“_type”: “blog”,
“_id”: “1”,
“_version”: 3,
“found”: true,
“_source”: {
“title”: “My first blog entry”,
“text”: “Starting to get the hang of this…”,
“tags”: [ “testing” ],
“views”: 0
}
}
可参考https://www.cnblogs.com/xing901022/p/5330778.html
Client程序演示
/*
* 更新部分文档doc
* 我们知道两次索引(put操作--add),第一次执行的是create第二次的结果其实就相当于update整个文档
*/
private static void updateBlogByDoc(Client client, String index, String type, String id) throws IOException, InterruptedException, ExecutionException {
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.index(index);
updateRequest.type(type);
updateRequest.id(id);
updateRequest.doc(XContentFactory.jsonBuilder()
.startObject()
.field("views","0")
.array("tags", "testing")
.endObject());
client.update(updateRequest).get();
}
调用:
updateBlogByDoc(client,"website1","blog1","1");
getBlogByPK(client,"website1","blog1","1");
结果显示:
{“title”:”My first blog entry”,”text”:”Just trying this out”,”date”:”2014/01/01”,”views”:”0”,”tags”:[“testing”]}
Head插件演示
使用脚本部分更新
你可以在 scripting reference documentation 获取更多关于脚本的资料。
我们也可以通过使用脚本给 tags 数组添加一个新的标签。在这个例子中,我们指定新的标签作为参数,而不是硬编码到脚本内部。 这使得 Elasticsearch 可以重用这个脚本,而不是每次我们想添加标签时都要对新脚本重新编译:
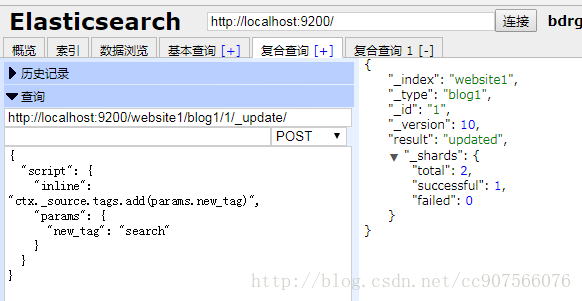
POST /website/blog/1/_update
{
“script” : “ctx._source.tags+=new_tag”,
“params” : {
“new_tag” : “search”
}
}
View in Sense
获取文档并显示最后两次请求的效果:
{
“_index”: “website”,
“_type”: “blog”,
“_id”: “1”,
“_version”: 5,
“found”: true,
“_source”: {
“title”: “My first blog entry”,
“text”: “Starting to get the hang of this…”,
“tags”: [“testing”, “search”],
“views”: 1
}
}
search 标签已追加到 tags 数组中。
Client程序演示
/*
* 更新部分文档script
* 我们知道两次索引(put操作--add),第一次执行的是create第二次的结果其实就相当于update整个文档
* inline script默认是被禁止的,但是可以使用file script的模式
* 如果有多个node, 必须在每个node的elasticsearch.yml中, 都加入上述配置, 否则, script不能使用。
* 要打开, 需要在config/elasticsearch.yml中添加如下配置:
script.inline:true
script.indexed:true
*/
private static void updateBlogByScript(Client client, String index, String type, String id) throws InterruptedException, ExecutionException {
Map<String,Object> map = new HashMap<String,Object>();
map.put("new_tag", "search");
UpdateRequest updateRequest = new UpdateRequest(index, type, id)
.script("ctx._source.tags.add(params.new_tag)", ScriptType.INLINE, map);
client.update(updateRequest).get();
System.out.println(updateRequest.scriptString());
}
调用:
updateBlogByScript(client,"website1","blog1","1");
getBlogByPK(client,"website1","blog1","1");
结果显示:
ctx._source.tags.add(params.new_tag)
{“title”:”My first blog entry”,”text”:”Just trying this out”,”date”:”2014/01/01”,”views”:0,”tags”:[“testing”,”search”]}
Head插件示例
我们甚至可以选择通过设置 ctx.op 为 delete 来删除基于其内容的文档:
POST /website/blog/1/_update
{
“script” : “ctx.op = ctx._source.views == count ? ‘delete’ : ‘none’”,
“params” : {
“count”: 1
}
}
更新的文档可能尚不存在
脚本可以在 update API中用来改变 _source 的字段内容, 它在更新脚本中称为 ctx._source 。 例如,我们可以使用脚本来增加博客文章中 views 的数量:
POST /website/blog/1/_update
{
“script” : “ctx._source.views+=1”
}
用 Groovy 脚本编程
对于那些 API 不能满足需求的情况,Elasticsearch 允许你使用脚本编写自定义的逻辑。 许多API都支持脚本的使用,包括搜索、排序、聚合和文档更新。 脚本可以作为请求的一部分被传递,从特殊的 .scripts 索引中检索,或者从磁盘加载脚本。
默认的脚本语言 是 Groovy,一种快速表达的脚本语言,在语法上与 JavaScript 类似。 它在 Elasticsearch V1.3.0 版本首次引入并运行在 沙盒 中,然而 Groovy 脚本引擎存在漏洞, 允许攻击者通过构建 Groovy 脚本,在 Elasticsearch Java VM 运行时脱离沙盒并执行 shell 命令。
因此,在版本 v1.3.8 、 1.4.3 和 V1.5.0 及更高的版本中,它已经被默认禁用。 此外,您可以通过设置集群中的所有节点的 config/elasticsearch.yml 文件来禁用动态 Groovy 脚本:
script.groovy.sandbox.enabled: false
这将关闭 Groovy 沙盒,从而防止动态 Groovy 脚本作为请求的一部分被接受, 或者从特殊的 .scripts 索引中被检索。当然,你仍然可以使用存储在每个节点的 config/scripts/ 目录下的 Groovy 脚本。
如果你的架构和安全性不需要担心漏洞攻击,例如你的 Elasticsearch 终端仅暴露和提供给可信赖的应用, 当它是你的应用需要的特性时,你可以选择重新启用动态脚本。
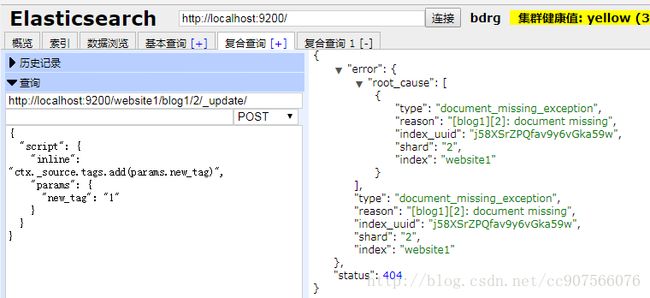
假设我们需要 在 Elasticsearch 中存储一个页面访问量计数器。 每当有用户浏览网页,我们对该页面的计数器进行累加。但是,如果它是一个新网页,我们不能确定计数器已经存在。 如果我们尝试更新一个不存在的文档,那么更新操作将会失败。
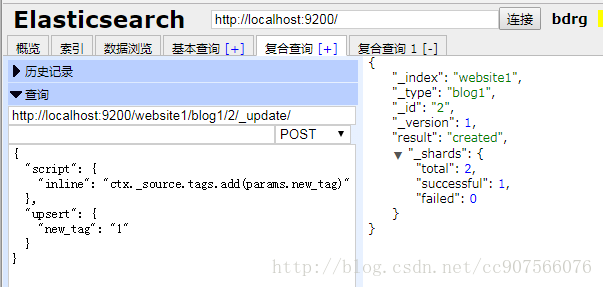
在这样的情况下,我们可以使用 upsert 参数,指定如果文档不存在就应该先创建它:
POST /website/pageviews/1/_update
{
“script” : “ctx._source.views+=1”,
“upsert”: {
“views”: 1
}
}
我们第一次运行这个请求时, upsert 值作为新文档被索引,初始化 views 字段为 1 。 在后续的运行中,由于文档已经存在, script 更新操作将替代 upsert 进行应用,对 views 计数器进行累加。
Head插件示例
加入字段的文档id不存在,会报错
使用upsert字段:
Client程序演示
//更新部分文档script 不报错 upset
private static void updateBlogByScriptNoException(Client client, String index, String type, String id) throws InterruptedException, ExecutionException {
Map<String,Object> map = new HashMap<String,Object>();
map.put("new_tag", "search");
UpdateRequest updateRequest = new UpdateRequest(index, type, id)
.script("ctx._source.tags.add(params.new_tag)", ScriptType.INLINE, map).upsert(map);
client.update(updateRequest).get();
System.out.println(updateRequest.scriptString());
}
// 10.更新部分文档script脚本 id不存在的文档直接插入不报错
updateBlogByScriptNoException(client,"website1","blog1","5");
getBlogByPK(client,"website1","blog1","5");
显示
连接成功…
ctx._source.tags.add(params.new_tag)
{“new_tag”:”search”}
website1–blog1–5–1
更新和冲突
在本节的介绍中,我们说明 检索 和 重建索引 步骤的间隔越小,变更冲突的机会越小。 但是它并不能完全消除冲突的可能性。 还是有可能在 update 设法重新索引之前,来自另一进程的请求修改了文档。
为了避免数据丢失, update API 在 检索 步骤时检索得到文档当前的 _version 号,并传递版本号到 重建索引 步骤的 index 请求。 如果另一个进程修改了处于检索和重新索引步骤之间的文档,那么 _version 号将不匹配,更新请求将会失败。
对于部分更新的很多使用场景,文档已经被改变也没有关系。 例如,如果两个进程都对页面访问量计数器进行递增操作,它们发生的先后顺序其实不太重要; 如果冲突发生了,我们唯一需要做的就是尝试再次更新。
这可以通过 设置参数 retry_on_conflict 来自动完成, 这个参数规定了失败之前 update 应该重试的次数,它的默认值为 0 。
POST /website/pageviews/1/_update?retry_on_conflict=5
{
“script” : “ctx._source.views+=1”,
“upsert”: {
“views”: 0
}
}
失败之前重试该更新5次。
在增量操作无关顺序的场景,例如递增计数器等这个方法十分有效,但是在其他情况下变更的顺序 是 非常重要的。 类似 index API , update API 默认采用 最终写入生效 的方案,但它也接受一个 version 参数来允许你使用 optimistic concurrency control 指定想要更新文档的版本。
删除文档
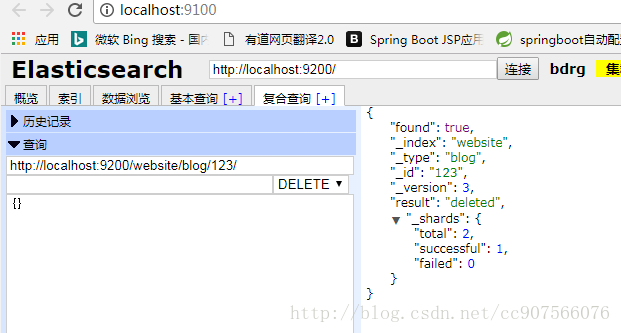
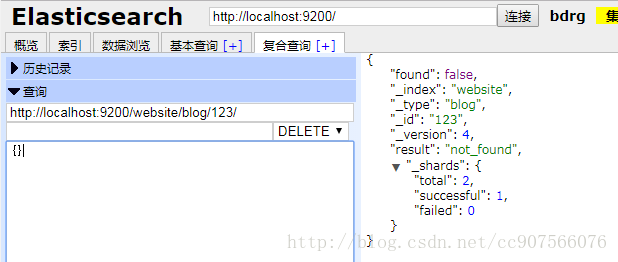
DELETE 语法后增加索引等参数
DELETE /{index}/{type}/{id}如果找到该文档,Elasticsearch 将要返回一个 200 ok 的 HTTP 响应码
如果文档没有 找到,我们将得到 404 Not Found 的响应码
即使文档不存在( Found 是 false ), _version 值仍然会增加。这是 Elasticsearch 内部记录本的一部分,用来确保这些改变在跨多节点时以正确的顺序执行。
正如已经在更新整个文档中提到的,删除文档不会立即将文档从磁盘中删除,只是将文档标记为已删除状态。随着你不断的索引更多的数据,Elasticsearch 将会在后台清理标记为已删除的文档。
Head插件示例
再次执行:
Client程序演示
// 删除一个文档
private static void delBlogByPk(Client client, String index, String type, String id) {
DeleteResponse response4 = client.prepareDelete(index,type,id).get();
System.out.println(response4.getResult().toString());
}
// 5.删除一个文档
delBlogByPk(client,"website1","blog1","1");
调用显示:
DELETED
处理冲突
Elasticsearch 需要一种方法确保文档的旧版本不会覆盖新的版本。 Elasticsearch 使用这个 _version 号来确保变更以正确顺序得到执行。如果旧版本的文档在新版本之后到达,它可以被简单的忽略。
我们可以利用 _version 号来确保 应用中相互冲突的变更不会导致数据丢失。我们通过指定想要修改文档的 version 号来达到这个目的。 如果该版本不是当前版本号,我们的请求将会失败。
但是我们所有的操作都将更改这个version号,即elasticsearch采取的乐观锁的方式来处理的并发事件。即我们的数据总是最新操作的数据。
乐观并发控制
在数据库领域中,有两种方法通常被用来确保并发更新时变更不会丢失:
悲观并发控制
这种方法被关系型数据库广泛使用,它假定有变更冲突可能发生,因此阻塞访问资源以防止冲突。 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。
乐观并发控制
Elasticsearch 中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。 然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。 例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
Elasticsearch 是分布式的。当文档创建、更新或删除时, 新版本的文档必须复制到集群中的其他节点。Elasticsearch 也是异步和并发的,这意味着这些复制请求被并行发送,并且到达目的地时也许 顺序是乱的 。 Elasticsearch 需要一种方法确保文档的旧版本不会覆盖新的版本。
当我们之前讨论 index , GET 和 delete 请求时,我们指出每个文档都有一个 _version (版本)号,当文档被修改时版本号递增。 Elasticsearch 使用这个 _version 号来确保变更以正确顺序得到执行。如果旧版本的文档在新版本之后到达,它可以被简单的忽略。
我们可以利用 _version 号来确保 应用中相互冲突的变更不会导致数据丢失。我们通过指定想要修改文档的 version 号来达到这个目的。 如果该版本不是当前版本号,我们的请求将会失败。
让我们创建一个新的博客文章:
PUT /website/blog/1/_create
{
“title”: “My first blog entry”,
“text”: “Just trying this out…”
}

响应体告诉我们,这个新创建的文档 _version 版本号是 1 。现在假设我们想编辑这个文档:我们加载其数据到 web 表单中, 做一些修改,然后保存新的版本。
首先我们检索文档:
GET /website/blog/1
响应体包含相同的 _version 版本号 1 :
{
“_index” : “website”,
“_type” : “blog”,
“_id” : “1”,
“_version” : 1,
“found” : true,
“_source” : {
“title”: “My first blog entry”,
“text”: “Just trying this out…”
}
}
现在,当我们尝试通过重建文档的索引来保存修改,我们指定 version 为我们的修改会被应用的版本:
PUT /website/blog/1?version=1
{
“title”: “My first blog entry”,
“text”: “Starting to get the hang of this…”
}
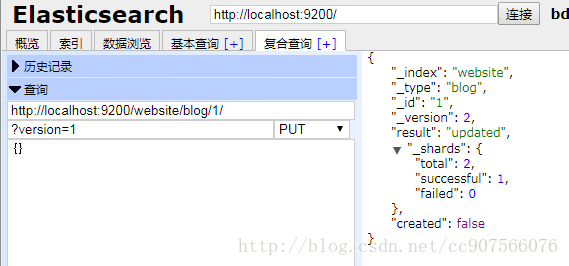
我们想这个在我们索引中的文档只有现在的 _version 为 1 时,本次更新才能成功。
此请求成功,并且响应体告诉我们 _version 已经递增到 2 :
{
“_index”: “website”,
“_type”: “blog”,
“_id”: “1”,
“_version”: 2
“created”: false
}
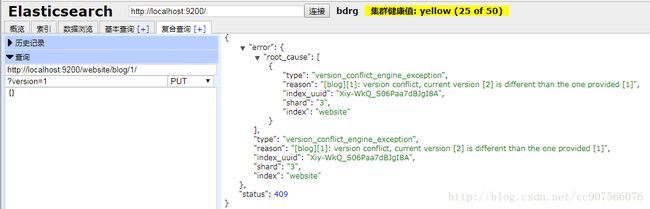
然而,如果我们重新运行相同的索引请求,仍然指定 version=1 , Elasticsearch 返回 409 Conflict HTTP 响应码,和一个如下所示的响应体:
{
“error”: {
“root_cause”: [
{
“type”: “version_conflict_engine_exception”,
“reason”: “[blog][1]: version conflict, current [2], provided [1]”,
“index”: “website”,
“shard”: “3”
}
],
“type”: “version_conflict_engine_exception”,
“reason”: “[blog][1]: version conflict, current [2], provided [1]”,
“index”: “website”,
“shard”: “3”
},
“status”: 409
}
这告诉我们在 Elasticsearch 中这个文档的当前 _version 号是 2 ,但我们指定的更新版本号为 1 。
我们现在怎么做取决于我们的应用需求。我们可以告诉用户说其他人已经修改了文档,并且在再次保存之前检查这些修改内容。 或者,在之前的商品 stock_count 场景,我们可以获取到最新的文档并尝试重新应用这些修改。
所有文档的更新或删除 API,都可以接受 version 参数,这允许你在代码中使用乐观的并发控制,这是一种明智的做法。
Head插件示例
Client程序演示
先两次执行put操作让version=2,之后我们调用:
//检索一个固定版本的文档
private static void getBlogWithVersion(Client client, String index, String type, String id,
long version) {
GetResponse response3 = client.prepareGet(index, type, id).setVersion(version).execute().actionGet();
System.out.println(response3.getSourceAsString());//这是_source部分
System.out.println(response3.getIndex()+"--"+response3.getType()+"--"+response3.getId()+"--"+response3.getVersion());
}
// 7.检索一个固定版本文档
getBlogWithVersion(client,"website1","blog1","1",1L);
调用结果如下:
客户端操作错误:[blog1][1]: version conflict, current version [2] is different than the one provided [1]
通过外部系统使用版本控制
一个常见的设置是使用其它数据库作为主要的数据存储,使用 Elasticsearch 做数据检索, 这意味着主数据库的所有更改发生时都需要被复制到 Elasticsearch ,如果多个进程负责这一数据同步,你可能遇到类似于之前描述的并发问题。
如果你的主数据库已经有了版本号 — 或一个能作为版本号的字段值比如 timestamp — 那么你就可以在 Elasticsearch 中通过增加 version_type=external 到查询字符串的方式重用这些相同的版本号, 版本号必须是大于零的整数, 且小于 9.2E+18 — 一个 Java 中 long 类型的正值。
外部版本号的处理方式和我们之前讨论的内部版本号的处理方式有些不同, Elasticsearch 不是检查当前 _version 和请求中指定的版本号是否相同, 而是检查当前 _version 是否 小于 指定的版本号。 如果请求成功,外部的版本号作为文档的新 _version 进行存储。
外部版本号不仅在索引和删除请求是可以指定,而且在 创建 新文档时也可以指定。
例如,要创建一个新的具有外部版本号 5 的博客文章,我们可以按以下方法进行:
PUT /website/blog/2?version=5&version_type=external
{
“title”: “My first external blog entry”,
“text”: “Starting to get the hang of this…”
}
在响应中,我们能看到当前的 _version 版本号是 5 :
{
“_index”: “website”,
“_type”: “blog”,
“_id”: “2”,
“_version”: 5,
“created”: true
}
现在我们更新这个文档,指定一个新的 version 号是 10 :
PUT /website/blog/2?version=10&version_type=external
{
“title”: “My first external blog entry”,
“text”: “This is a piece of cake…”
}
请求成功并将当前 _version 设为 10 :
{
“_index”: “website”,
“_type”: “blog”,
“_id”: “2”,
“_version”: 10,
“created”: false
}
如果你要重新运行此请求时,它将会失败,并返回像我们之前看到的同样的冲突错误, 因为指定的外部版本号不大于 Elasticsearch 的当前版本号。