数据仓库系列(8):实时数据开发
(一)技术路线图

(二)典型应用场景
1. 电商平台大促期间成交金额;
2. 广告主实时报表(分钟级更新);
3. 实时反作弊;
4. 业务场景异常监控。
(三)流式技术架构
目前流式计算框架相对成熟,以Storm、Spark Streaming为代表的开源组件也被广泛应用。流式数据处理,简单来讲,就是系统每产生一条数据,都会被立刻采集并发送到流式任务中心进行处理,不需要额外的定时调度来执行任务。
流式框架具备以下优点:
1. 时效性高:延迟粒度通常在秒级;
2. 任务常驻:流式任务一旦启动,就会一直运行,直到人为终止,且数据源是无界的;
3. 处理性能高:流式计算通常会采用较好的服务器来运行任务,因为一旦处理吞吐量赶不上采集吞吐量,就会出现数据计算延迟;
4. 逻辑简单:由于流式计算通常是针对单条数据做处理,缺乏数据之间的关联运算能力,所以在支持的业务逻辑上相对简单,并且处理结果会与离线存在一定的差异。
以Storm的Topology为例来看一下流式数据处理过程:

(四)数据采集
流式数据的源头,一般来自于各个业务的日志服务器,有两种,一种为访问日志:网页端Web日志、客户端日志,另一种为数据库变更日志:Mysql的binlog日志、HBase的hlog日志等。这些数据每采集一条。便会发送到消息队列中间件中,供下游实时订阅。
但很多时候,出于吞吐量及系统压力上的考虑,很多数据并不是新增一条就处理一次,而是根据数据大小或者时间阀值,每收集到一个小的数据文件便处理一次,例如日志512KB处理一次,或者是30秒写一次。
在有一些情况下,为了保证实时数据和离线数据的来源保持一致,一般都是通过消息队列中间件的方式来采集数据,一方面发送给实时系统做统计,另一方面也是离线系统数据采集的源头。
Kafka作为Storm的好朋友,通常用在流式处理过程之前,用于缓冲过量的数据。在数据密集型的系统架构中,一般会使用Kafka作为中间的缓冲,使用Storm做数据统计时,我们一般会从Kafka中消费消息,然后把最终的统计结果存储到目标数据库中,Storm-kafka模块极大方便了我们在开发Spout时和Kafka的整合。
完整过程如下图所示:

(五)数据处理
目前在业界比较广泛采用的框架有Twitter的Storm、Apache的Spark Streaming,以及最近几年流行的Flink。它们整体架构大同小异,但在实现细节上有诸多的不同,需要根据业务场景的特征来灵活选择框架。
当数据被实时加工处理后,会写到存储系统中,通常采用Redis存储数据,一来速度非常快,二来落地到Mysql也非常方便。在流式处理框架中,数据的写入通常是增量的方式进行。
流式基础框架图2:

Storm涉及到的概念有:
1. 拓扑(Topologies);
2. 元组(Tuple);
3. 流(Streams);
4. 喷口(Spouts);
5. 螺栓(Bolts);
6. 任务(Tasks);
7. 组件(Component);
8. 流分组(Stream groupings);
9. 可靠性(Reliability);
10.工作进程(Workers)。
Storm组建关系及流程如下图:


(六)去重
指标去重不仅是离线开发中常见的难题,也是实时系统中常见的问题。由于实时任务追求处理性能,一般的业务逻辑是在内存中完成的,如果数据量过大,势必拖累系统性能并带来异常隐患。
去重有两种情况,一种是精确去重,另一种是模糊去重。精确去重需要特定的业务逻辑来处理,当数据量过大时需要分散到不同的服务器上完成统计,最后汇总统计结果;模糊去重可以采用一些算法模型,将内存的使用量降低到正常的千分之一左右。
常见的模糊去重算法有两种:
1. 布隆过滤器:布隆过滤器是数据算法的扩展应用,不保存真实数据,只存储明细数据对应的哈希值标记位,计算的结果比真实值偏小,并且可以设定哈希碰撞的误差率,每1亿条数据大约需要100MB左右的空间即可完成去重计算;
2. 基数估计:基数估计同样应用了哈希原理,按照数据的分散程度来估计现有数据集的边界,从而得出大概的去重值总和,该算法的结果可能偏大也可能偏小,但1亿条数据只需要10KB即可完成计算。
(七)数据倾斜
数据倾斜也是常见的业务逻辑问题,假设在数据量非常大时,在某个节点需要通过区分key值来做不同的运算,便非常容易遇到数据倾斜的问题。解决实时处理中的数据倾斜问题通常有两种方式:
1. 去重指标分桶:通过对去重值进行分桶哈希,相同的值一定会落到同一个桶中,最后把每个桶的值进行加总,便得到了最终结果,该方式主要利用分散的内存资源;
2. 非去重指标分桶:数据随机分发到每个桶中,最后把每个桶的值进行加总,并得到了最终结果,该方式主要利用分散的CPU计算能力。
(八)幂等
幂等是一个数学概念,特点是任意多次执行所产生的影响均与一次执行的影响相同,例如setTrue()函数就是一个幂等函数,无论多次执行,其结果都是一样的。
以Storm的Ack机制为例:
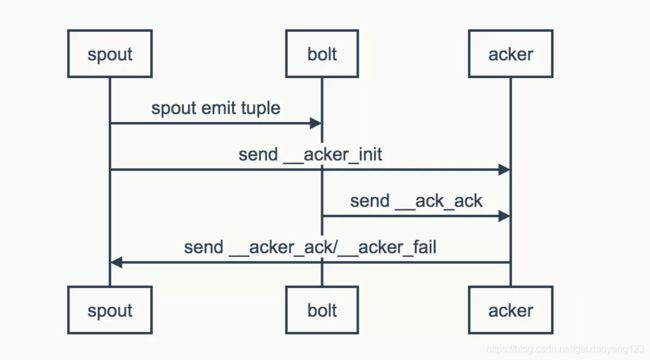
Storm为了保证数据能正确的被处理,对于Spout产生的每一个Tuple,Storm都会进行跟踪。如果一个Tuple处理成功,则调用Spout的Ack方法;如果Tuple处理失败,则调用Fail方法;如果在规定的时间内,没有收到Ack响应Tuple,同样触发Fail方法,认为该Tuple处理失败。
Storm系统中有一组叫做Acker的特殊的任务,它们负责跟踪DAG(有向无环图)中的每个消息。Acker任务保存了Spout ID到一对值的映射。第一个值就是Spout的任务ID,通过这个ID,Acker就知道消息处理完成时该通知哪个Spout任务。第二个值是一个64bit的数字,我们称之为Ack val,它是树中所有消息的随机ID的异或计算结果。Ack val表示了整棵树的的状态,无论这棵树多大,只需要这个固定大小的数字就可以跟踪整棵树。当消息被创建和被应答的时候都会有相同的消息ID发送过来做异或。每当Acker发现一棵树的Ack val值为0的时候,它就知道这棵树已经被完全处理了。
在很多复杂情况下,例如网络波动、Storm重启等,会出现重复数据,因此并不是所有操作都是幂等的。

在幂等的概念下,我们需要了解消息传输保障的三种机制:At most once、At least once和Exactly once。
At most once:消息传输机制是每条消息传输零次或者一次,即消息可能会丢失;
At least once:意味着每条消息会进行多次传输尝试,至少一次成功,即消息传输可能重复但不会丢失;
Exactly once:的消息传输机制是每条消息有且只有一次,即消息传输既不会丢失也不会重复。
Storm采用了上游数据备份和消息确认的机制,来保障消息在失败之后能够重新处理。Storm的消息确认原理是,每个操作都会把前一次操作处理消息的确认信息返回,同时,Topology的数据源还会备份它生成的所有数据记录。当所有数据记录的处理确认信息收到,备份即会被安全拆除;失败后,如果不是所有的消息处理确认信息被收到,那数据记录会被数据源数据替换。此举能够保障不会发生数据丢失事件,但是,也会带来数据结果重复的问题,这就是At least once传输机制。
因此Storm的机制本身难以保持幂等,需要通过额外的业务处理逻辑来处理数据,在金融等行业尤为要注意。
(九)多表关联
在流式数据处理中,数据的计算是以计算增量为基础的,所以各个环节到达的时间和顺序,既是不确定的,也是无序的。在这种情况下,如果两表要关联,势必需要将数据在内存中进行存储,当一条数据到达后,需要去另一个表中查找数据,如果能够查到,则关联成功,写入下游;如果无法查到,可以被分到未分配的数据集合中进行等待。在实际处理中,考虑到数据查找的性能,会把数据按照关联主键进行分桶处理,以降低查找的数据量,提高性能。
(十)维表加载
部分业务场景下,为了加快数据的周转速度,通常不会将所有信息都记录到日志中,部分维度信息需要从维表中加载,但通常会遇到三种情况:
1. 数据无法准备好,因为离线系统是批量处理,势必存在更新的延迟情况;
2. 无法获取全量最新数据,当维表也作为一个实时流输入时,由于到达的无序且时间不确定,容易产生关联上的歧义。
解决方法有两种:
1. 全量加载:维表数据量较少时,建议全部加载到内存中进行关联;
2. 增量加载:如果维表数据很多,可以将热门数据保留在内存中,通过每天增量更新冷门数据的形式进行处理。
(十一)洪峰挑战
主要解决思路有如下几种:
1. 独占资源与共享资源合理分配:在一台机器中,共享资源池可以被多个实时任务抢占,如果一个任务80%的时间都需要抢资源,可以考虑分配更多的独占资源;
2. 合理设置缓存机制:虽然内存的读写性能是最好的,但很多数据依然需要读库更新,可以考虑将热门数据尽量多的留在内存中,通过异步的方式来更新缓存;
3. 计算合并单元:在流式计算框架中,拓扑结构的层级越深,性能越差,考虑合并计算单元,可以有效降低数据的传输、序列化等时间;
4. 内存共享:在海量数据的处理中,大部分的对象都是以字符串形式存在的,在不同线程间合理共享对象,可以大幅度降低字符拷贝带来的性能消耗;
5. 在高吞吐与低延迟间寻求平衡:高吞吐与低延迟天生就是一对矛盾体,将多个读写库的操作或者ACK操作合并时,可以有效降低数据吞吐,但也会增加延迟,可以进行业务上的取舍。