kafka 生产者使用详解
前言
看完本文你将学会以下知识:
- kafka 数据的生产大致流程
- 如何创建并使用 kafka生产者
- kafka生产者的常用配置
- 了解 kafka生产者 的分区
kafka数据生产流程
大概流程如下图:
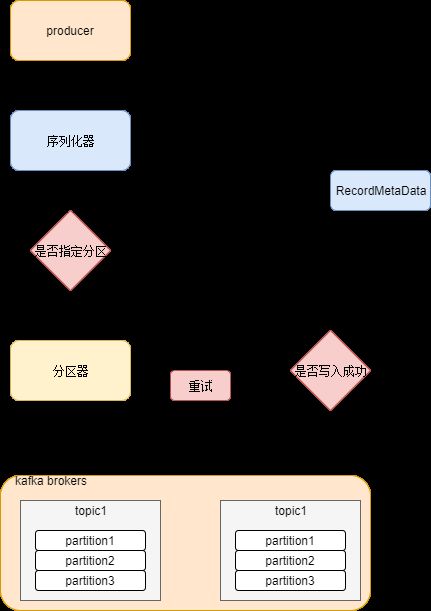
- kafka生产者会将消息封装成一个 ProducerRecord 向 kafka集群中的某个 topic 发送消息
- 发送的消息首先会经过序列化器进行序列化,以便在网络中传输
- 发送的消息需要经过分区器来决定该消息会分发到 topic 对应的 partition,当然如果指定了分区,那么就不需要分区器了。
- 这个时候消息离开生产者开始往kafka集群指定的 topic 和 partition 发送
- 如果写入成功,kafka集群会回应 生产者一个 RecordMetaData 的消息,如果失败会根据配置的允许失败次数进行重试,如果还是失败,那么消息写入失败,并告诉生产者。
创建 kafka生产者
大致了解了生产者工作的流程,我们就来看看一个生产者是怎么创建的把!
最简单的kafka 生产者莫过于其自带的
kafka-console-producer.sh --broker-list localhost:9092 --topic test,接着就可以通过向控制台输入数据来给kafka生产了,当然,这个没太多实际意义,一般也就用来测试测试。一般我们常用的方式还是通过api的方式自己写代码来创建:
- 第一步 当然是添加相关依赖包了:
org.apache.kafka
kafka-clients
1.0.0
- 第二步 普通使用
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++){
producer.send(new ProducerRecord("my-topic", Integer.toString(i), Integer.toString(i))
,new Callback() {
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
//todo something when complete }
});
}
//all done close
producer.close();
是不是觉得很简单?虽然使用起来是很简单,但是要使用好也不是那么容易噢。。。这里请注意以下几点:
1、一定要记得close producer,以免造成资源浪费
2、send() 是异步的,所以上面的代码是有点问题的,producer.close();应该在合适的机会调用,而不是代码末尾
3、如果你想使用同步发送,那么只需要简单的producer.send().get() 使用get()函数就可以了
- 第三步 事务使用
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("transactional.id", "my-transactional-id");
KafkaProducer producer
= new KafkaProducer(props, new StringSerializer(), new StringSerializer());
//begining transaction
producer.initTransactions();
try {
producer.beginTransaction();
for (int i = 0; i < 100; i++){
producer.send(new ProducerRecord<>("my-topic", Integer.toString(i), Integer.toString(i)));
}
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
// We can't recover from these exceptions, so our only option is to close the producer and exit.
producer.close();
} catch (KafkaException e) {
// For all other exceptions, just abort the transaction and try again.
producer.abortTransaction();
}
producer.close();
1、每个生产者只能有一个打开的事务,并且需要配置好transactional.id。
2、beginTransaction()和commitTransaction()调用之间发送的所有消息都是单个事务的一部分。
3、send()不需要指定回调函数,也不需要使用get(),因为事务是统一处理的,当事务发生错误可以通过KafkaException来捕获进行处理
ok!上面就是kafka生产者的创建部分内容了,也基本该了解kafka生产者的使用了,为了更好的使用它,我们有必要对它的相关配置来进行详细了解。
kafka生产者 配置
- acks 和 timeout.ms
timeout.ms(0.9.0.0版本中就被弃用)
指定了 broker 等待同步副本返回消息确认的时间,与 asks 的配置相匹配——如果在指定时间内没有收到同步副本的确认,那么 broker 就会返回一个错误。-
acks = 1
指定了必须要有多少个分区副本收到消息,生产者才会认为消息写入是成功的。这个参数对消
息丢失的可能性有重要影响。该参数有如下选项:- acks=0,生产者在成功写入消息之前不会等待任何来自服务器的响应。也就是说,如果当中
出现了问题,导致服务器没有收到消息,那么生产者就无从得知,消息也就丢失了。不过,因为
生产者不需要等待服务器的响应,所以它可以以网络能够支持的最大速度发送消息,从而达到很
高的吞吐量。
acks=1,只要集群的 Leader 节点收到消息,生产者就会收到一个来自服务器的成功响应。如果消息无法到达 Leader 节点(比如首领节点崩溃,新的 Leader 还没有被选举出来),生产者会收到一个错误响应,为了避免数据丢失,生产者会重发消息。不过,如果一个没有收到消息的节点成为新Leader,消息还是会丢失。这个时候的吞吐量取决于使用的是同步发送还是异步发送。如果让发送客户端等待服务器的响应(通过调用 Future 对象的 get() 方法),显然会增加延迟(在网络上传输一个来回的延迟)。如果客户端使用回调,延迟问题就可以得到缓解,不过吞吐量还是会受发送中消息数量的限制(比如,生产者在收到服务器响应之前可以发送多少个消息)。
如果 acks=all,只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。这种模式是最安全的,它可以保证不止一个服务器收到消息,就算有服务器发生崩溃,整个集群仍然可以运行。不过,它的延迟比 acks=1 时更高,因为我们要等待不只一个服务器节点接收消息。
- acks=0,生产者在成功写入消息之前不会等待任何来自服务器的响应。也就是说,如果当中
buffer.memory=33554432
该参数用来设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。如果生产消息的速度超过发送的速度,会导致生产者空间不足。这个时候,send()方法调用要么被阻塞,要么抛出异常,取决于如何设置block.on.buffer.full参数(在 0.9.0.0 版本里被替换成了max.block.ms,表示在抛出异常之前可以阻塞一段时间)compression.type=none
默认情况下,消息发送时不会被压缩。该参数可以设置为snappy、gzip或lz4,它指定了消息被发送给 broker 之前使用哪一种压缩算法进行压缩。
- snappy 压缩算法由 Google 发明,占用较少的 CPU,却能提供较好的性能和相当可观的压缩比,如果比较关注性能和网络带宽,可以使用这种算法。
- gzip 压缩算法一般会占用较多的 CPU,但会提供更高的压缩比,所以如果网络带宽比较有限,可以使用这种算法。
使用压缩可以降低网络传输开销和存储开销,而这往往是向 Kafka 发送消息的瓶颈所在。
- retries 和 retry.backoff.ms
retries=0
生产者从服务器收到的错误有可能是临时性的错误(比如分区找不到 Leader)。在这种情况下,retries
参数的值决定了生产者可以重发消息的次数,如果达到这个次数,生产者会放弃重试并返回错误。retry.backoff.ms=100
默认情况下,生产者会在每次重试之间等待 100ms,不过可以通过retry.backoff.ms参数来改变这个时间间隔。建议在设置重试次数和重试时间间隔之前,先测试一下恢复一个崩溃节点需要多少时间(比如所有分区选举出 Leader 需要多长时间),让总的重试时间比 Kafka 集群从崩溃中恢复的时间长,否则生产者会过早地放弃重试。不过有些错误不是临时性错误,没办法通过重试来解决(比如“消息太大”错误)。一般情况下,因为生产者会自动进行重试,所以就没必要在代码逻辑里处理那些可重试的错误。你只需要处理那些不可重试的错误和重试次数超出上限的情况。
- batch.size 和 linger.ms
- batch.size:=16384
当有多个消息需要被发送到同一个分区时,生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算(而不是消息个数)。 - linger.ms:=0
指定了生产者在每次发送消息的时间间隔
当批次被填满 或者 等待时间达到
linger.ms设置的间隔时间,批次里的所有消息会被发送出去,哪怕此时该批次只有一条消息。
所以就算把批次大小设置得很大,也不会造成延迟,只是会占用更多的内存而已。但如果设置得太小,因为生产者需要更频繁地发送消息,会增加一些额外的开销。
client.id=''
该参数可以是任意的字符串,服务器会用它来识别消息的来源max.in.flight.requests.per.connection=5
该参数指定了生产者在收到服务器响应之前可以发送多少个消息。它的值越高,就会占用越多的内存,不过也会提升吞吐量。把它设为 1 可以保证消息是按照发送的顺序写入服务器的,即使发生了重试。
如何保证顺序性:如果把 retries 设为非零整数,同时把
max.in.flight.requests.per.connection设为比 1 大的数,那么,如果第一个批次消息写入失败,而第二个批次写入成功,broker 会重试写入第一个批次。如果此时第一个批次也写入成功,那么两个批次的顺序就反过来了。一般来说,如果某些场景要求消息是有序的,那么消息是否写入成功也是很关键的,所以不建议把
retries设为 0。可以把max.in.flight.requests.per.connection设为 1,这样在生产者尝试发送第一批消息时,就不会有其他的消息发送给broker。不过这样会严重影响生产者的吞吐量,所以只有在对消息的顺序有严格要求的情况下才能这么做。
- request.timeout.ms 和 metadata.fetch.timeout.ms
- request.timeout.ms=305000
指定了生产者在发送数据时等待服务器返回响应的时间 - metadata.fetch.timeout.ms (0.9.0.0版本中就被弃用)
指定了生产者在获取元数据(比如目标分区的 Leader 是谁)时等待服务器返回响应的时间。如果等待响应超时,那么生产者要么重试发送数据,要么返回一个错误(抛出异常或执行回调)。
- max.request.size=1048576
该参数用于控制生产者发送的请求大小。它可以指能发送的单个消息的最大值,也可以指单个请求里所有消息总的大小。例如,假设这个值为 1MB,那么可以发送的单个最大消息为 1MB,或者生产者可以在单个请求里发送一个批次,该批次包含了 1000 个消息,每个消息大小为 1KB。另外,broker 对可接收的消息最大值也有自己的限制(message.max.bytes),所以两边的配置最好可以匹配,避免生产者发送的消息被 broker 拒绝。
注意区分
batch.size只是针对一个 topic 的 partition,而max.request.size针对单次请求的。
- receive.buffer.bytes=32768 和 send.buffer.bytes=131072
这两个参数分别指定了 TCP socket 接收和发送数据包的缓冲区大小。如果它们被设为 -1,就使用操作系统的默认值。如果生产者或消费者与 broker 处于不同的数据中心,那么可以适当增大这些值,因为跨数据中心的网络一般都有比较高的延迟和比较低的带宽。
关于更多的配置信息,可以查看:http://kafka.apachecn.org/documentation.html#configuration
通过上面的一些讲解,应该已经可以比较友好的使用 kafka生产者了,接下来我们还剩下最后一个部分,kafka的分区
分区
从第一个部分 kafka数据生产流程 我们知道,分区我们是可以自己指定的,也可以是使用默认的分区器。
- 指定分区
指定分区很简单,在我们创建发送的 ProducerRecord 时候指定下就可以
/**
* Creates a record to be sent to a specified topic and partition
*
* @param topic The topic the record will be appended to
* @param partition The partition to which the record should be sent
* @param key The key that will be included in the record
* @param value The record contents
*/
public ProducerRecord(String topic, Integer partition, K key, V value) {
this(topic, partition, null, key, value, null);
}
- 默认分区器
默认分区器其实也很简单,关键源码如下
/**
* org.apache.kafka.clients.producer.internals.DefaultPartitioner
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
//记录了 topic 写入消息的数量,并返回本条消息是第`nextValue`条。
int nextValue = nextValue(topic);
List availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
阅读源码是件比较需要耐心的事情,但是解释源码,会让人欲仙欲死,这里我只解释下上面代码的几个方法做了什么,具体流程,烦您自己耐心看看咯
- nextValue(topic)
,这个nextValue(topic)的作用就是根据 topic 上一次写入 partition 的序号,返回一个 +1 的序号,并记录。说简单点,其实也就是记录了这个 topic 写入消息的数量,并告诉本条消息你是第几条。 - cluster.availablePartitionsForTopic
根据 topic 获取其对应的 partitions 信息,这里其实就是为了获取 partition 数量 - Utils.toPositive
传入一个int,并将其二进制数据的首位进行去 0 操作 - Utils.murmur2
kafka 自带的 hash算法,返回一个32位的hash值,不依赖 java的hash,好处就是可以不受java 版本变更的影响,这一点相当重要,因为 hash算法会影响到数据的储存位置
关于 默认的分区器 就到这了,相当的简单,总结下就是,分区可以自己指定,一般在一些数据倾斜的时候发生,大多数时候都是使用的默认分区器,默认分区器会根据 key 进行分区,如果 key=null,会采取轮询的方式进行分区,否则则根据 key 的 hash,进行散列的随机分区。
当然,可能还缺一个自定义分区器,不过,相信这个东西肯定难不倒亲爱的你,这里就不哔哩哔哩了哈