YARN 初识
Apache YARN (Yet Another Resource Negotiator,另一个资源协调者)是Hadoop的集群资源管理系统,它从Hadoop 2.0版本开始被引入,主要是为了改进MapReduce的实现,可以很好地支持其它的分布式计算模式。
YARN提供了请求和使用集群资源的API,但这些API通常不能由用户代码直接使用,而是使用由分布式集群框架提供的更高级的API,这些框架构建在YARN上,并对用户隐藏了资源管理的细节,如下图所示,它展示了一些分布式计算框架(MapReduce、Spark等等)作为YARN 应用运行在集群计算层(YARN)和存储层(HDFS 和 HBase)上。
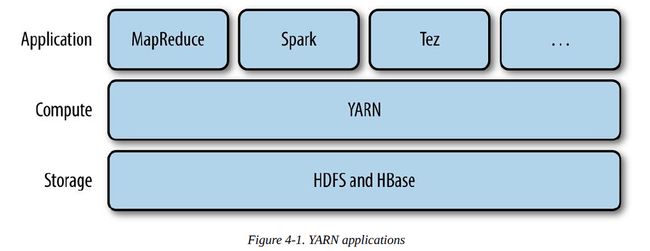
当然也有其它的应用层是构建在上图架构之上的,比如Pig,Hive和Crunch等是构建在MapReduce、Spark、Tez之上的,但是它们不直接与YARN交互。
解剖YARN应用的运行机制
YARN提供的核心服务是通过两个长时间运行的守护进程:resource manager(资源管理器),每个集群中只有一个,主要负责管理集群中使用的资源,另一个是node managers(节点管理器)运行在集群中每个节点上,主要负责启动和监控container(容器),container是用一套有限的资源(内存、CPU等)来执行特定应用的进程,这要看YARN怎么配置了,一个container也许是一个Unix进程或是一个Linux cgroup。
下图展示了YARN是怎样运行的:
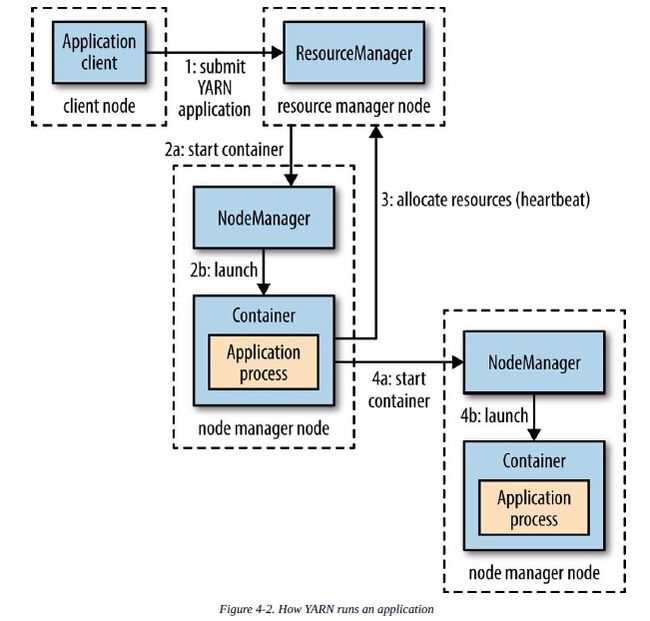
在YARN上运行一个应用,客户端需要联系resource manager并请求运行一个application master进程(图中的第一步),然后resource manager寻找一个node manager,它可以在其container中启动application master(图中2a和2b)。一旦application master启动起来,它做什么取决于具体的应用,它可以在container做一些简单的计算,然后把结果返还给客户端。或者它可以向resource manager请求更多的container(第3步),并用它们运行一个分布式计算(图中4a和4b)。
从图中看到,YARN没有为应用的各个部分(client, master, process)提供任何方式进行相互通信。实际YARN是用远程调用的形式(比如Hadoop的RPC层)来传递状态更新和结果返回给客户端。
Resource Requests
YARN处理资源请求有一个灵活的模型,对一组container的请求可以表达为每个container需要的计算机资源数量(内存和CPU),以及对container的局部约束。
局部性可以确保分布式数据处理算法有效的使用集群的带宽,所以,YARN允许一个应用对它请求的container指定局部性约束。局部性约束可以应用到集群中任何一个container,包括同一个机架或不同机架上的节点上的container。
有时,局部性约束不能得到满足,在这种情况下,无论是否分配,约束是可以选择、放宽的。例如,如果请求的节点不能启动一个container(因为它正在运行其他的container),YARN将会试着在同一个机架的节点上启动一个container,如果还不行,那就在集群中的任何一个节点上启动。
一般情况下,启动一个container去处理HDFS块(比如,运行一个map task),应用将在该块的3个副本中的其中一个节点上来请求一个container,有可能是同一个机架上的节点,也可能是集群中的任何一个。
Application Lifespan
YARN应用的生命周期可以有较大的不同:从运行几秒钟的“短命”应用到运行几天甚至几个月的长期应用。可以从应用的生命周期来对应用分类:首先,最简单情况是一个用户job对应一个应用,这通常是MapReduce采用的方法。
第二种为每个工作流或用户回话的多个job(可能不相关)运行一个应用,这种方式比第一种更高效,因为container可以在不同的job中重用,并且在不同的job间也有可能缓存中间的数据。
第三种为对于长期运行的应用可以在不同的用户间共享,这样的应用通常是起到某种协调作用的角色。例如,Apache Slider有一个长期运行的主应用负责启动集群中其它的应用。
Building YARN Applications
从零开始写一个YARN应用是相当复杂的,但是在大多数情况下是不需要的,因为往往可能使用一个现存的应用。例如,你需要运行一个有向无环图(DAG: directed acyclic graph)的job,那么可以用Spark或Tez。
YARN Compared to MapReduce 1
在Hadoop最初版本(版本1或更早)的MapReduce分布式实现,有时会被称作“MapReduce 1”,主要是为了和”MapReduce 2“区分开来,MapReduce 2是使用YARN来实现的。
在MapReduce1,中,有两中类型的守护进程控制着job的执行过程:一个job tracker和一个或多个task tracker。job tracker负责协调系统中所有的job,通过调度task任务,在task tracker节点上执行。task tracker负责执行job tracker分配给它的任务,并向job tracker节点发送处理报告,这记录了每个job的整体执行情况。如果一个task失败,job tracker会在不同的task tracker节点上重新调度它。
在MapReduce1中, job tracker同时负责job的调度和任务进度的监控(跟踪任务、重启失败或运行缓慢的task和做任务的记录,比如维护计数器的总数)。相比之下,YARN的这些责任是由单个的实体处理:资源管理器(resource manager)和一个主应用程序(application master,每个MapReduce job都有一个)。MapReduce1的 job tracker也负责存储已完成任务的历史记录,虽然有可能运行一个job历史服务器,作为一个守护进程去加载关闭的job tracker。对于YARN来说,等效的角色是时间轴服务器(timline server),它存储着应用的历史记录。
YARN中和task tracker等效的是node manager。MapReduce1和YARN的映射,如下图:

YARN被设计用来解决MapReduce1许多限制的问题。主要有以下几个方面的好处:
- 可扩展性(Scalability):相比MapReduce1,YARN可以运行一个更大的集群。MapReduce1 运行4000节点和40000个task就遇到了扩展性的瓶颈,这主要是因为job tracker要同时管理job和task。YARN克服了这些限制,凭借其分割resource manager / application master的架构,它可以扩展到10000个节点和100000个task。
相比于job tracker,YARN 应用的每个实例(这里为MapReduce job)都有一个专用的application master。这种模式接近于Google原始的MapReduce论文,它描述了一个主进程是怎样协调集群中的工作节点运行map和reduce任务的。 - 可用性(Availability):高可用(HA:High Availability)通常是指在当前服务进程失败的情况下,通过复制所需的状态给另一个守护进程来接管提供服务的任务。然而,对于job tracker来说,在job tracker的内存中,大量迅速变化的复杂状态(例如,每隔几秒更新task的状态)来实现HA是很困难的。
在YARN中,通过使用resource manager和application master来拆分job tracker的职责,使HA成为一个分而治之的问题:分担给resource manager和每一个YARN application。 - 利用率(Utilization): 在MapReduce1中,每个tasktracker在配置时被静态分配为固定大小的“槽(slots)”,它又被分为多个map槽和多个reduce槽。一个map槽只能运行map task,一个reduce槽只能运行reduce task。
在YARN中,一个node manager管理一个资源池,而不是固定数量的特定的“槽”。在YARN运行MapReduce,不会遇到像MapReduce1那样仅因为只有map槽可用,而reduce任务必须等待的情况,如果运行task的资源可用,则应用会将可用的资源分配给他们。
此外,YARN中资源是细粒度的,可以满足应用的每个请求,而不是每个固定的槽。 - 多租户(Multitenancy): 多租户技术(multi-tenancy technology)或称多重租赁技术,是一种软件架构技术,它是在探讨与实现如何于多用户的环境下共用相同的系统或程序组件,并且仍可确保各用户间数据的隔离性。
在多租户技术中,租户(tenant)是指使用系统或电脑运算资源的客户,但在多租户技术中,租户包含在系统中可识别为指定用户的一切数据,举凡帐户与统计信息(accounting data),用户在系统中建置的各式数据,以及用户本身的客制化应用程序环境等,都属于租户的范围,而租户所使用的则是基于供应商所开发或建置的应用系统或运算资源等,供应商所设计的应用系统会容纳数个以上的用户在同一个环境下使用,为了要让多个用户的环境能力同一个应用程序与运算环境上使用,则应用程序与运算环境必须要特别设计,除了可以让系统平台可以允许同时让多份相同的应用程序运行外,保护租户数据的隐私与安全也是多租户技术的关键之一。
多租户技术的实现重点,在于不同租户间应用程序环境的隔离(application context isolation)以及数据的隔离(data isolation),以维持不同租户间应用程序不会相互干扰,同时数据的保密性也够强。
在某些方面,YARN的最大好处是它开辟了Hadoop MapReduce之外的其它分布式应用。MapReduce只是众多YARN应用中的一个。
在同一个AYRN集群中,可以运行不同版本的MapReduce,这使得升级MapReduce会更容易。
YARN 调度器
在理想状态下,对YARN应用的请求将会被立即处理,然而,在实际情况下,资源是有限的,并且在繁忙的集群中,一个应用常常需要等待某些请求完成。YARN调度器的工作就是根据一些定义好的策略来为应用分配资源。调度一般是一个难题并且没有最好的策略,这就是为什么YARN要提供调度器的可选和可配置的策略。
Scheduler Options
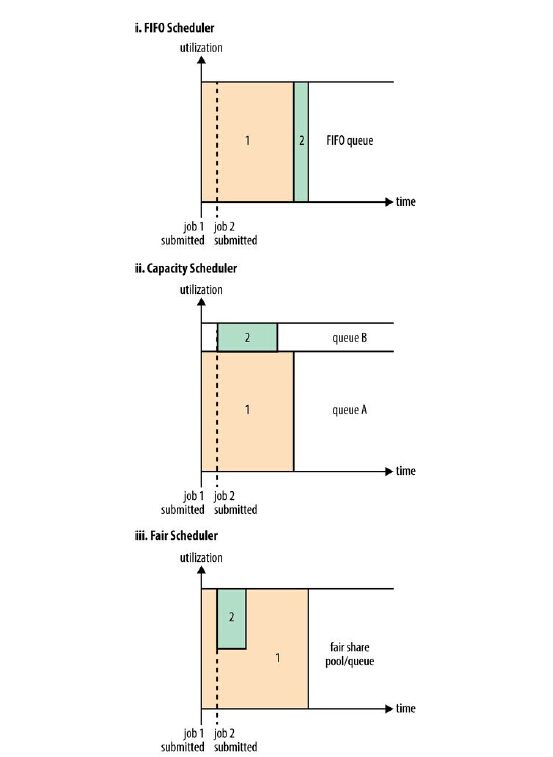
在YARN中有三种调度器:FIFO、容量(Capacity)、公平调度器(Fair Schedule)。FIFO调度器是按应用提交到队列的先后顺序来调度的,一旦一个请求得到处理,下一个应用将接受后续的请求。FIFO调度器简单易理解并且不需要任何配置,但是它不适合用于共享集群,因为大型应用将会使用集群中所有的资源,每个应用必须等待直到轮到它。
对于共享集群最好使用Capacity Schedule和Fair Schedule,它们能让运行时间较长的job能够及时完成,并且用户能够运行并发较小的即席查询(ad hoc queries),在一个合理的时间内得到结果。
对于Capacity Schedule,每个一个job都有一个专用的队列,小的job可以立即得到运行。因为需要为每个job保留capacity,所以这将降低集群的利用率,也意味着运行大job的完成时间要晚于使用FIFO调度器的时间。
对于Fair 调度器,他不需要保留固定数量的容量(capacity),因为它会在运行的job间动态平衡资源。当第一个job(较大)启动时,仅有该job在运行,所以它会得到集群中所有的资源,当第二个job(较小)启动时,它会得到集群中一半的资源。所以每个job都在使用公平份额的资源。
值得注意的是在第二个job启动到它接收到资源会有一段时间的延迟,因为它需要等待第一个占用全部资源的job释放资源。小的job运行完成并且不再需要资源,大的job将会再次得到集群中的所有资源。整体效果是高的集群使用率和能够及时完成小的job。
下图显示了这三种调度器的差异: