Spark实时项目第六天-维度数据业务流程之监控维表数据并用maxwell-bootstrap初始化数据(全量导入省份表)
处理维度数据合并的策略
维度数据和状态数据非常像,但也有不同之处:
共同点:
- 长期保存维护
- 可修改
- 使用k-v方式查询
不同点:
- 数据变更的时机不同
状态数据往往因为事实数据的新增变化而变更
维度数据只会受到业务数据库中的变化而变更
根据共同点,维度数据也是非常适合使用hbase存储的,稍有不同的是维度数据必须启动单独的实时计算来监控维度表变化来更新实时数据。
实时处理流程
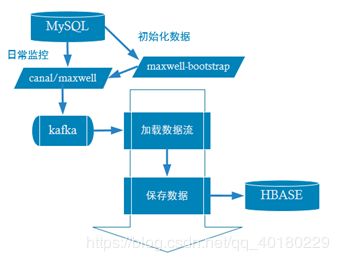
HBase建表
create table gmall_province_info ( id varchar primary key , info.name varchar , info.region_id varchar , info.area_code varchar )SALT_BUCKETS = 3
增加ProvinceInfo
在scala\com\atguigu\gmall\realtime\bean\ProvinceInfo.scala
case class ProvinceInfo(id:String,
name:String,
region_id:String,
area_code:String) {
}
增加ProvinceInfoApp
import com.alibaba.fastjson.JSON
import com.atguigu.gmall.realtime.bean.ProvinceInfo
import com.atguigu.gmall.realtime.utils.{MyKafkaUtil, OffsetManagerUtil}
import org.apache.hadoop.conf.Configuration
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{HasOffsetRanges, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.phoenix.spark._
object ProvinceInfoApp {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setAppName("province_info_app").setMaster("local[*]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val groupId = "gmall_province_group"
val topic = "ODS_T_BASE_PROVINCE"
val offsets: Map[TopicPartition, Long] = OffsetManagerUtil.getOffset(groupId, topic)
var inputDstream: InputDStream[ConsumerRecord[String, String]] = null
if (offsets != null && offsets.size > 0) {
inputDstream = MyKafkaUtil.getKafkaStream(topic, ssc, offsets, groupId)
} else {
inputDstream = MyKafkaUtil.getKafkaStream(topic, ssc, groupId)
}
//获得偏移结束点
var offsetRanges: Array[OffsetRange] = Array.empty[OffsetRange]
val inputGetOffsetDstream: DStream[ConsumerRecord[String, String]] = inputDstream.transform { rdd =>
offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd
}
val provinceInfoDstream: DStream[ProvinceInfo] = inputGetOffsetDstream.map { record =>
val jsonString: String = record.value()
val provinceInfo: ProvinceInfo = JSON.parseObject(jsonString, classOf[ProvinceInfo])
provinceInfo
}
provinceInfoDstream.cache()
provinceInfoDstream.print(1000)
provinceInfoDstream.foreachRDD { rdd =>
rdd.saveToPhoenix("gmall_province_info", Seq("ID", "NAME", "REGION_ID", "AREA_CODE"),
new Configuration, Some("hadoop102,hadoop103,hadoop104:2181"))
OffsetManagerUtil.saveOffset(groupId, topic, offsetRanges)
}
ssc.start()
ssc.awaitTermination()
}
}
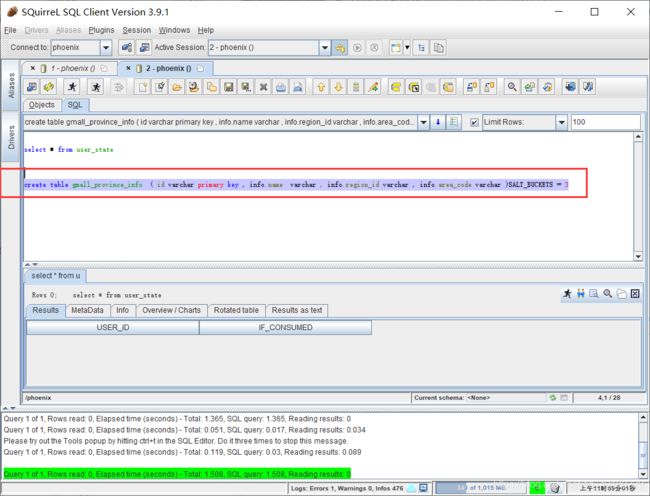
修改BaseDBMaxwellApp
加入判断是否为空
if(dataObj != null && !dataObj.isEmpty){
MyKafkaSinkUtil.send(topic, id, dataObj.toJSONString)
}
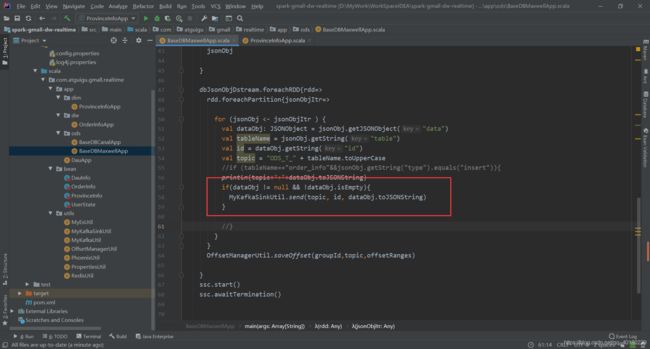
利用maxwell-bootstrap 初始化数据
其中client_id 是指另一个已启动的maxwell监控进程的client_id
bin/maxwell-bootstrap --user maxwell --password 123123 --host hadoop102 --database spark_gmall --table base_province --client_id maxwell_1
用kafka监控ODS_DB_GMALL_M: 能够将base_province这张维表全量导入
