Written by wanping7
from datetime import datetime
import numpy as np, pandas as pd
from datetime import datetime, timedelta
import seaborn as sns
import matplotlib.pyplot as plt
get_ipython().run_line_magic('matplotlib', 'inline')
get_ipython().run_line_magic('config', "ZMQInteractiveShell.ast_node_interactivity='all'")
import os, sys
sns.set(rc={'figure.figsize':(13,7)})
sns.set_style("whitegrid")
PATH = "../data/"
结论
- 数据无缺失
- 数据无异常
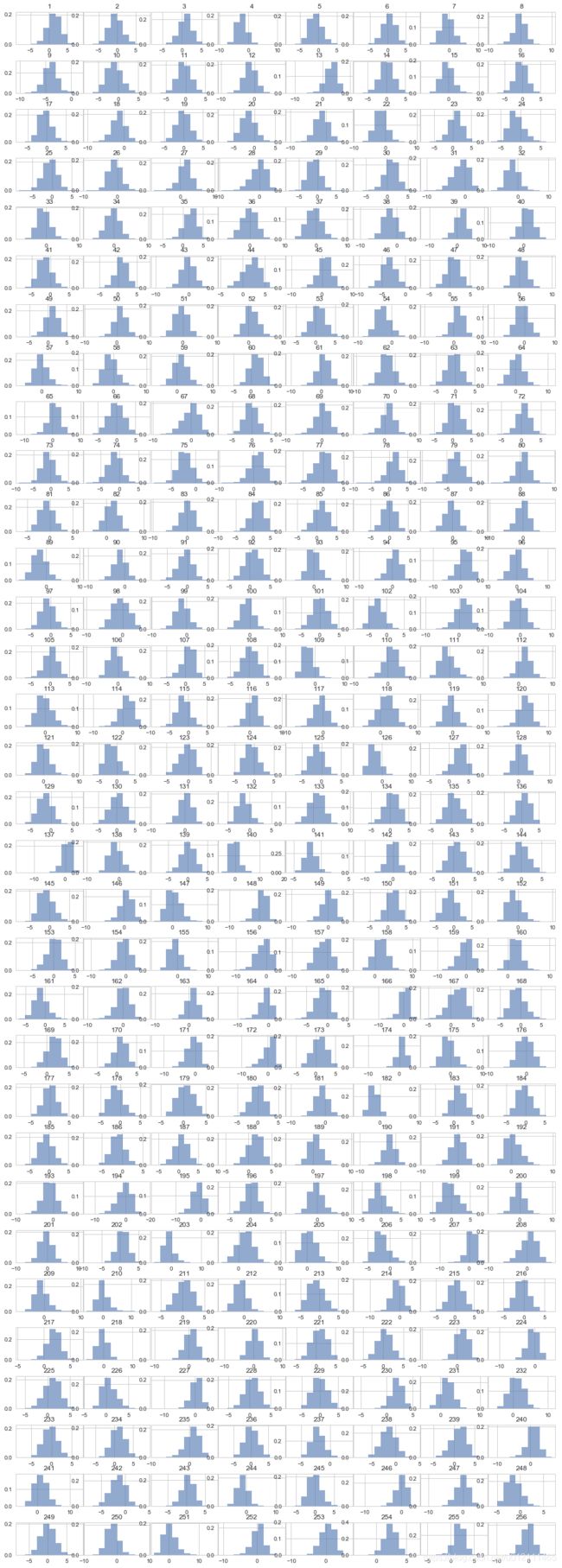
- 数据分布近似正态
- 128维实值向量
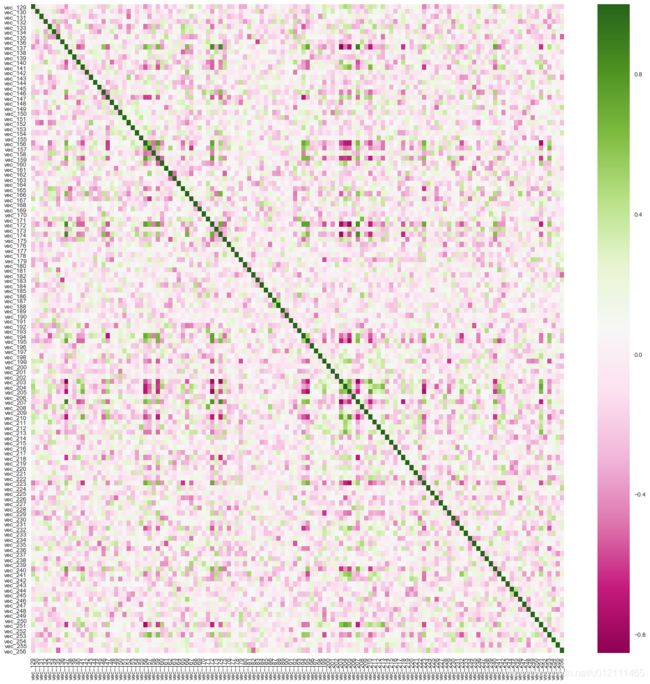
- 所有商品不同文本或图像之间的相关性(比较意义不大)
- 相关性都非常小
- 商品(抽取前200商品)
- 文本相关性大于0.6的商品占9.5%
- 图像相关性大于0.6的商品占3.9%
TRAIN_PATH = PATH + "underexpose_train/"
商品特征
- underexpose_item_feat.csv
- item_id:第0列
- txt_vec:第1-128列
- img_vec:第129-256列
1 缺失情况
item_feat = pd.read_csv(TRAIN_PATH + "underexpose_item_feat.csv", header=None)
item_feat.columns = ["item_id"] + ["vec_" + str(i) for i in item_feat.columns[1:]]
print("缺失情况:", item_feat.isna().sum().sum())
item_feat["vec_1"] = item_feat["vec_1"].map(lambda x:x[1:]).astype("float64")
item_feat["vec_129"] = item_feat["vec_129"].map(lambda x:x[1:]).astype("float64")
item_feat["vec_128"] = item_feat["vec_128"].map(lambda x:x[:-1]).astype("float64")
item_feat["vec_256"] = item_feat["vec_256"].map(lambda x:x[:-1]).astype("float64")
item_feat.head(2)

2 异常
item_feat.iloc[:, 1:].min().min()
item_feat.iloc[:, 1:].max().max()

(item_feat.iloc[:, 1:]>10).sum().sum()

(item_feat.iloc[:, 1:]<-10).sum().sum()

3 分布
plot_time = datetime.now()
fig, axs = plt.subplots(32,8, figsize=(17, 50), facecolor='w', edgecolor='k')
fig.subplots_adjust(hspace = .5, wspace=.01)
axs = axs.ravel()
for i in range(256):
x = axs[i].hist(item_feat.iloc[:, i+1], density=True, alpha=0.6)
x = axs[i].set_title(str(1+i))
print("画图耗时:", datetime.now()-plot_time)
plot_time = datetime.now()
fig, axs = plt.subplots(32,8, figsize=(17, 50), facecolor='w', edgecolor='k')
fig.subplots_adjust(hspace = .5, wspace=.01)
axs = axs.ravel()
for i in range(256):
x = axs[i].boxplot(item_feat.iloc[:, i+1])
x = axs[i].set_title(str(1+i))
print("画图耗时:", datetime.now()-plot_time)

4 文本与图像相关性
文本相关性
corr_matrix_txt = item_feat.iloc[:,1:129].corr()
sns.set(rc={'figure.figsize':(20, 20)})
x = sns.set_style("whitegrid")
x = sns.heatmap(corr_matrix_txt,
xticklabels=corr_matrix_txt.columns.values,
yticklabels=corr_matrix_txt.columns.values,
cmap="PiYG")

图片相关性
corr_matrix_img = item_feat.iloc[:, 129:].corr()
sns.set(rc={'figure.figsize':(20, 20)})
x = sns.set_style("whitegrid")
x = sns.heatmap(corr_matrix_img,
xticklabels=corr_matrix_img.columns.values,
yticklabels=corr_matrix_img.columns.values,
cmap="PiYG")
文本与图片交叉相关性
corr_matrix_cross = item_feat.iloc[:, 1:].corr()
sns.set(rc={'figure.figsize':(20, 20)})
x = sns.set_style("whitegrid")
x = sns.heatmap(corr_matrix_cross,
xticklabels=corr_matrix_cross.columns.values,
yticklabels=corr_matrix_cross.columns.values,
cmap="PiYG")

5 商品相关性
def get_redundant_pairs(corr_matrix):
'''Get diagonal and lower triangular pairs of correlation matrix'''
pairs_to_drop = set()
cols = corr_matrix.columns
for i in range(0, corr_matrix.shape[1]):
for j in range(0, i+1):
pairs_to_drop.add((cols[i], cols[j]))
return pairs_to_drop
def get_top_abs_correlations(corr_matrix, n=5):
au_corr = corr_matrix.abs().unstack()
labels_to_drop = get_redundant_pairs(corr_matrix)
au_corr = au_corr.drop(labels=labels_to_drop).sort_values(ascending=False)
return au_corr[0:n], 100* au_corr[au_corr>0.6].shape[0]/au_corr.shape[0]
文本
corr_matrix_item_txt = item_feat.set_index(["item_id"]).iloc[:200, :128].T.corr()
print("Top Absolute Correlations:")
top10, percent_60 = get_top_abs_correlations(corr_matrix_item_txt, 10)
print("=======================================================>Top10相关商品:")
top10
print("=======================================================>相关系数>0.6商品占比:", str(percent_60)+"%")

图像
corr_matrix_item_img = item_feat.set_index(["item_id"]).iloc[:200, 128:].T.corr()
print("Top Absolute Correlations:")
top10, percent_60 = get_top_abs_correlations(corr_matrix_item_img, 10)
print("=======================================================>Top10相关商品:")
top10
print("=======================================================>相关系数>0.6商品占比:", str(percent_60)+"%")
