01_公司数仓架构当前存在的问题
先来看看我们数仓当前采用的技术架构:
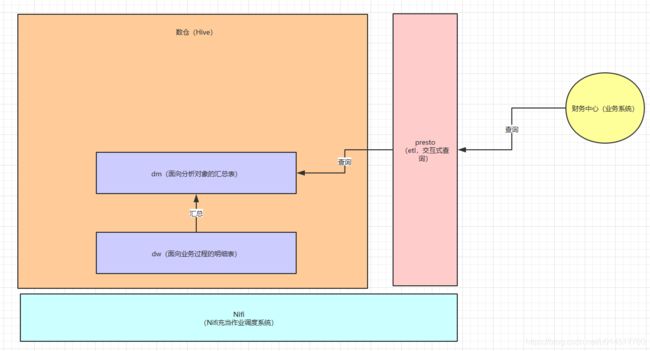
数仓:数仓分为2层:dw和dm层。
dw层是面向业务过程的明细表,比如:用户下单,采购入库会分别对应一张表。
而dm层是面向分析对象的汇总表,分析对象就是指:商品,门店,仓库,站点。比如:如果分析对象是商品,dm层就会有一张商品的每日汇总表,记录这个商品每一天卖了多少件这样子。
NIFI:用了Nifi来充当作业调度系统,来控制哪个任务先执行,哪个任务后执行。比如:先执行dw层的下单事务事实表,要等它执行完,才能执行dm层的商品每日汇总表。
presto:presto在这个架构中主要有2个作用。第一个就是用presto来做etl;第二个就是用presto来做交互式查询,比如:如果数仓要提供一些报表给财务中心(财务中心是我们公司其中一个业务系统),这个架构中是用presto来直接查询Hive的数仓数据。
在大致清楚了目前的数仓架构之后,下面,都会以“对财务中心提供一张财务报表”的场景来分析这套架构存在的问题。
背景引入:
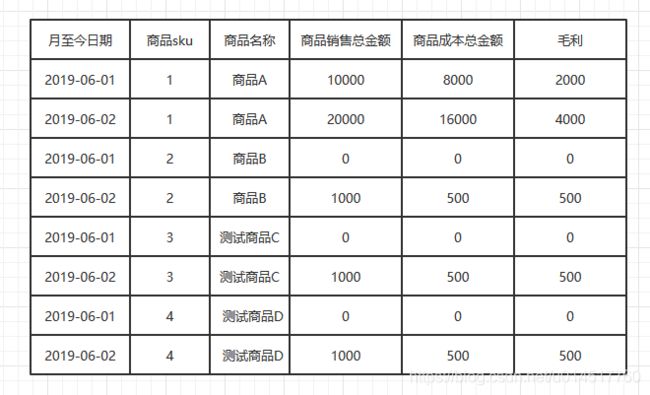
假设,财务中心现在需要的报表是这样子的:

这个报表中,有2个搜索条件,第一个是月至今的日期,第二个是商品名称。
比如:月至今日期输入“2019-06-02”,就只会查询出月至今日期=2019-06-02的两条记录;
商品名称如果输入“商品B”,则只会查询出商品名称是商品B的2条记录。
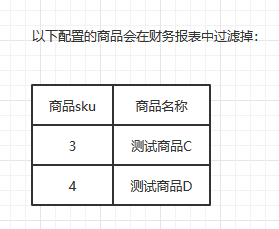
同时,这个报表后台还有个配置,有些商品是这个报表不希望看到的商品,比如:测试商品C。这个配置页面大致是这样子的:

也就是说,如果后台配置中,过滤了测试商品C和测试商品D,则最后的财务报表中是不能显示测试商品C和测试商品D的相关数据的,即使用户没有在筛选框中过滤测试商品C和测试商品D。
在清楚了大致的需求后,我们就可以来分析目前架构存在的问题了。
–
1.交互查询性能较差
在这套架构中,是用presto来直接查询Hive中的数据。
虽然说presto是即席查询的技术,但是大多数公司还是用来临时看看这个表目前的数据大致是怎样的。
如果直接用来做交互式查询,现在dm层的这张dm_sku_mtd(简化了表名),用2000万的数据来测试,财务中心分页查询一次大概需要3秒。就算是筛选条件中过滤了日期和商品名称,还是需要1~2秒返回。
有人会说,报表1~2秒性能还可以啊。但是,实际上,你的数仓如果以后的业务是APP直接显示某个商品的聚合指标呢?你也是1到2秒返回吗?这样就太慢了。
一般来说,如果是直接查询mysql的单表,在日期和商品sku id上做索引之后,其实几十毫秒就能查询出来数据了,再加上接口的开销,对用户来说可能就200~300ms就能看到数据了。
但是,如果用户要查看APP上的某个指标,用presto去查询Hive的单表,要1~2秒才能返回,再加上接口的开销,我按少了算2秒,那也是很慢了。用户看上去就是load了2秒,数据才能出来,这个用户体验是很差的。
–
2.数仓分层太少,每次都是烟囱式开发
不知道大家有没有注意到,为什么背景中我要把这个后台配置,过滤掉测试商品C和测试商品D这个配置引入进来?
如果只是dw层dm层2层的开发,肯定就是这样子玩的:
(1)dw:搞1个下单的事务事实表,存放每个商品每次下单的记录

(2)dm:对dw层的这张下单事务事实表,按月至今每天进行汇总。其中dm层的这张汇总表里面,已经过滤了测试商品C和测试商品D了。然后财务中心的Java系统直接基于presto查询这张表。

不知道,大家有有没有发现这2层的架构有什么问题?
假如说,以后订单中心(公司的另一个业务系统,和财务中心平级),也需要一个和上面的报表很类似的一个报表。
但是,订单中心要求的报表有一点点不同,它不需要过滤掉测试商品C和测试商品D,因为订单中心希望看到全部商品的汇总数据。
现在问题来了,dw层的事务事实表是可以复用的,但是dm层的这张汇总表可以复用吗?不行啊!因为你之前因为财务中心的需求,在dm层的汇总表的etl sql中已经过滤掉了财务中心后台配置的测试商品C和测试商品D了。
那就尴尬了,因为其实订单中心要的报表的所有字段和之前财务中心的报表都是一模一样的,但是,因为你开发财务中心的时候过滤掉了测试商品C和测试商品D,导致dm层的这个汇总表不能复用。
此时,你就需要重新创建1个dm层的汇总表,这个新表的逻辑和财务中心那个汇总表的逻辑是一模一样的,只是不需要去过滤财务中心后台配置的那些商品。
这里,给大家解释一下,因为财务中心可能因为一些安全性的问题,后台配置过滤的不只是测试商品,可能连正式商品E都会过滤掉。但是,订单中心的报表是需要这个正式商品E的。
相信看到这里,大家已经能感觉到,2层架构的缺陷是什么了。说白了,就是你的明细层可以复用,但是你的汇总层无法复用!
更有甚者,有的人直接就在明细层的下单事务事实表中,把财务中心后台配置的商品全部过滤了。那就坑爹了,你连明细层都无法复用,此时你又要去重新创建一个一模一样的下单事务事实表吗?
这里,先不展开怎么解决,大家只要意识到2层架构的问题就好了。
大家不要以为这个是小问题。我这里举出的只是其中一个很小的场景,会导致dw或dm层无法复用。在真实复杂的电商业务中,如果你在分层时不将公共层和个性化的东西区分开,你会发现你的公共层会慢慢被业务入侵,破坏,最终导致你的公共层无法复用。
因为,相信大家做数仓的目的,除了对外统一提供一致的入口和出口以外。还有一个很重要的目的就是避免每来1个新业务,明明之前都做过类似的指标了,还要为这个新业务重新做一次,即烟囱式开发。
良好的数仓设计,必定是有一块公共层,这块公共层的数据是所有业务可以复用的。然后每来1块新业务,直接把公共层的数据拿出来,稍作修改或者根本不做修改,就可以对外提供了。
举个例子,比如:公共层中应该存放所有商品的汇总数据。而财务中心只需要拿到公共层的汇总数据,然后过滤掉测试商品C和测试商品D;而订单中心将公共层的汇总数据拿过来,直接就可以使用了,因为它不需要去过滤商品。
(公共层的汇总表)

(财务中心的汇总表,稍加过滤)
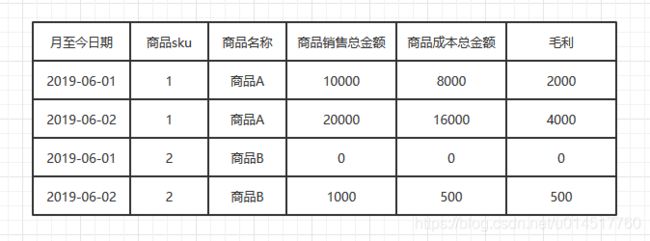
(订单中心的汇总表,不需要过滤)
3.用presto来做etl的缺陷
首先澄清,这里,讲的是开源的presto,而不是像京东那些对presto进行过大量二次开发的presto。
相信大家在做etl技术选型的时候,几个选择就是:Hive QL,Spark SQL。
这里,我首先来讲一下为什么这个架构当时要选用presto来做etl。
大家知道,中小型公司做数仓,大部分还是用Hive,因为Hive可以存放的数据量很大。
但是,Hive有一个问题就是查询速度很慢,如果你用原生的Hive QL来查询,底层实际上将Hive QL转换成Map Reduce程序去执行,MR是走磁盘的,肯定是很慢咯。
我们公司当时做数仓,就是希望数仓的数据,能够给业务系统(比如:上面说的订单中心和财务中心)提供交互式的查询,而不仅仅是出报表。
那么大家可以试想一下,上面做的商品汇总表是在Hive中,而又要给订单中心提供交互式的查询,用Hive QL或Spark SQL能实现交互式的查询吗?肯定不行啊,Hive QL很慢就不说了,就算是Spark SQL也不适合做交互式查询的,Spark SQL因为底层要分析DAG之类的,还要为各个工作节点分配各种资源,可能都要几秒才能返回,这样的交互式查询的效率肯定是不行的。
因此,当时就选用了presto来做交互式查询,事实证明,presto的确1~2秒就能出结果,比Spark SQL在交互式查询的方面要出色。
因此,当时顺便就用preso来做etl了,因为当时我们以为etl不就是select吗?直接用presto来做,就不需要再额外搭建Spark集群了。
至于Hive QL来做etl虽然稳定,但是太慢了,因此没有选用。
但是,实际在对接复杂的需求的时候,就发现presto做etl的缺陷了。
如果系统中只是sum,avg,max等等这种很简单的聚合需求,你用presto来写sql是完全是可以做的。
但是,需求是无耻的!大家有没有试想过会有sql无法实现的etl需求?
我举个我们项目中的需求,来分析一下什么是sql无法实现的etl需求。
比如说:我们现在dw层有一张库存流水明细表,保存了每一条库存流水,这里简化成只有“采购入库”和“销售出库”的库存流水。

我们这里只列出了仓库id=1,sku id=1的一个商品的6条流水记录,其中4条是6月份的流水,2条是7月份的流水。
现在,无耻的需求来了!我要计算“每个商品,每个月的月初和月末的库存,而且每月的月初库存数必须=上一个月的月末库存数”。

6月的库存数 = 6月月初的库存 + 6月采购入库数 - 6月销售出库数 = 0 + 100 + 100 - 50 - 50 = 100。实际上在我们真实的需求中,这个6月月末的库存数的计算公式的复杂度远远比这个公式复杂地多。
算完6月的库存数之后,就要算7月的库存数了,因为已经有了6月月末的库存数(100),因此7月的月初库存数也是100,
则7月的库存数 = 6月月末的库存数 + 6月采购入库数 - 6月销售出库数 = 100 + 50 + 50 = 200
大家试想一下,如果这个计算公式,复杂10倍,比如:7月的库存数 = 6月采购入库数 + A + B - C - D + (D > 0?E:F)。你要计算7月的月初和月末的库存,肯定要先计算出6月月末的库存数,再将它作为此7月的月初库存数,才能去根据公式计算7月的数据。
现在,问题来了,sql怎么写才能做到先计算6月数据,再依赖6月数据,去生成7月数据呢?
如果是你写个Java程序去写这个逻辑,肯定很简单。先计算出6月的数据,insert进去;然后计算7月数据的时候,就可以依赖刚刚insert进去的6月的数据了。伪代码大致是这样的:
for(月份=6月;月份 <= 7月; 月份++){
// 1.计算6月的数据 // 3.第二次循环进来,计算7月的数据,就可以依赖刚刚insert进去的6月的数据了
// 2.insert到表中
}
但是,你如果尝试用一条sql去实现这个循环,会发现很难写,而且presto是没有存储过程的,你也别想依赖存储过程去写一个for循环。
就算你的sql很牛b,用sql写出来了,我保证大多数人写出来的sql极其复杂,可读性和可维护性都很差,也许后面的人来接受你这个复杂sql,很快就被绕晕了。
这里,先抛出几个核心问题,当然这套架构还有很多的问题。后面会针对每个问题,来分析如何去优化这套架构。