方式一:Local模式
后续补充......
方式二:Standalone cluster
后续补充......
方式三:Flink on Yarn
两种部署方式比较:
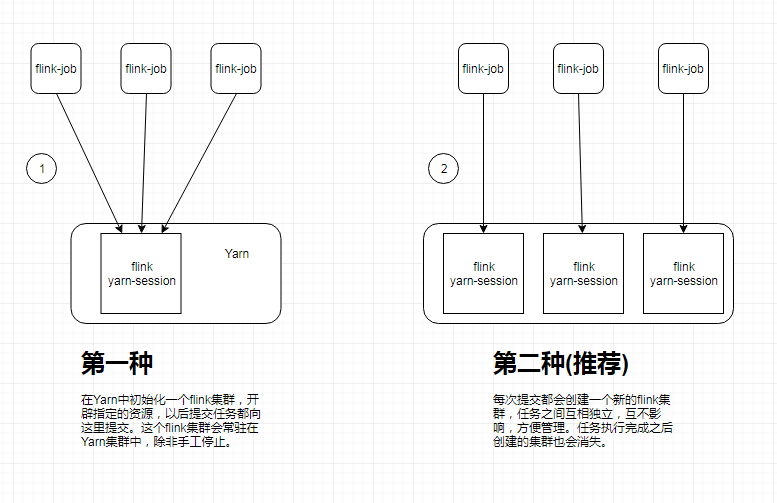
第一种方式启动命令的一些参数说明:
./bin/yarn-session.sh 命令用法:
必选: -n,--container
可选:
-D
-d,--detached 独立运行
-jm,--jobManagerMemory
-nm,--name 在YARN上为一个自定义的应用设置一个名字
-q,--query 显示yarn中可用的资源 (内存, cpu核数)
-qu,--queue
-s,--slots
-tm,--taskManagerMemory
-z,--zookeeperNamespace
-id,--applicationId
第二种方式启动命令的一些参数说明:
./bin/flink run 命令用法J:
run [OPTIONS]
"run" 操作参数:
-c,--class
-m,--jobmanager
-p,--parallelism
默认查找当前yarn集群中已有的yarn-session信息中的jobmanager【/tmp/.yarn-properties-root】:
./bin/flink run ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1
连接指定host和port的jobmanager:
./bin/flink run -m hadoop100:1234 ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1
启动一个新的yarn-session:
./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar -input hdfs://hostname:port/hello.txt -output hdfs://hostname:port/result1
注意:yarn session命令行的选项也可以使用./bin/flink 工具获得。它们都有一个y或者yarn的前缀
例如:./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar
其他部署方式:Mesos;Docker;Kubernetes;AWS;Goole Compute Engine;MapR
HA:
本质也就是JobManager 高可用(HA),JobManager协调每个flink任务部署。它负责任务调度和资源管理。 默认情况下,每个flink集群只有一个JobManager,这将导致一个单点故障(SPOF):如果JobManager挂了,则不能提交新的任务,并且运行中的程序也会失败。 使用JobManager HA,集群可以从JobManager故障中恢复,从而避免SPOF(单点故障) 。 用户可以在standalone或 YARN集群 模式下,配置集群高可用。
JobManager HA配置:
1、Standalone集群的高可用
Standalone模式(独立模式)下JobManager的高可用性的基本思想是,任何时候都有一个 Master JobManager ,并且多个Standby JobManagers 。 Standby JobManagers可以在Master JobManager 挂掉的情况下接管集群成为Master JobManager。 这样保证了没有单点故障,一旦某一个Standby JobManager接管集群,程序就可以继续运行。 Standby JobManager和Master JobManager实例之间没有明确区别。 每个JobManager都可以成为Master或Standby节点。
2、Yarn 集群高可用
flink on yarn的HA 其实主要是利用yarn自己的job恢复机制。
HA参见:https://www.cnblogs.com/wynjauu/articles/10545128.html
转载请注明地址:https://www.cnblogs.com/wynjauu/articles/10543833.html