SparkSql读取外部数据源
1、产生背景
用户需求:方便快速从不同的数据源(json、parquet、rdbms),经过混合处理(json join parquet),再将处理结果以特定的格式(son、Parquet)写回指定的系统(HDFS、S3)上去
Spark SQL 1.2 ==> 外部数据源API
Loading and saving Data is not easy
Parse raw data:text/json/parquet
Convert data format transformation
Datasets stores in various Formats/Systems
2、目标
对于开发人员:是否需要吧代码合并到spark中 ??不需要 —jars
用户:
读:spark.read.format(format)
format
build-in:json parquet jdbc cvs(2+)
package: 外部的 并不是spark内置 https://spark-packages.org/
写:
people.write.format(“parquet”).save(“path")
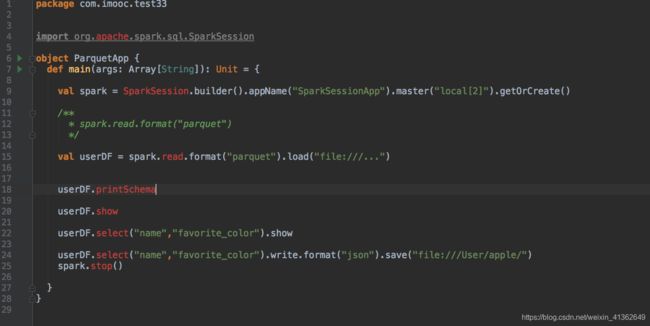
3、操作Parquet文件数据
加载数据:spark.read.format(“parquet”).load(path)
保存数据:df.write.format(“parquet”).save(path)
spark.read.load(“file:…..json’) 会报错,因为sparksql默认处理的format就是parquet
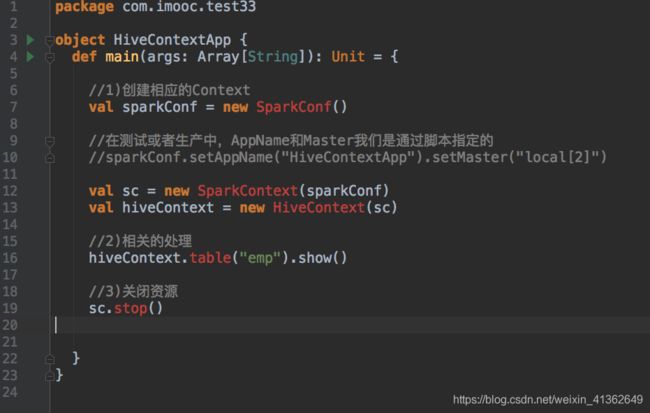
4、操作Hive表数据
spark.table(tableName)
df.write.saveAsTable(tablename)
spark.sql(“select deptno,count(1) as mount from amp where group by deptno”).filter(“deptno is not null”).write.saveAsTable(“hive_table_1”)
spark.sql(“show tables”).show
spark.table(“hive_table_1”).show
spark.sqlContext.setConf(“spark.sql.shuffle.partitions”,”10")
在生产环境中一定要注意设置spark.sql.shuffle.aprtitions,默认是200
5、操作mysql关系型数据库
操作mysql的数据
//第一种方法
val jdbcDF = spark.read.format(“jdbc”).option(“url”,”jdbc:mysql://localhost:3306/hive”).option(“dbtable”,”hive.TBLS”).option(“user”,”root”).option(“password”,”root’)..option(“driver”,”com.mysql.jdbc.Driver”).load()
jdbcDF.printSchema
jdbcDF.show
jdbc.select(“TBL_ID”,”TBL_NAME”).show
//第二种方法
import java.util.Properties
val connectionProperties = new Properties()
connectionProperties.put(“user”,”root”)
connectionProperties.put(“password”,”root”)
connectionProperties.put(“driver”,”com.mysql.jdbc.Driver”)
val jdbcDF2 = spark.read.jdbc(“jdbc:mysql://localhost:3306”,”hive.TBLS”,connectionProperties)
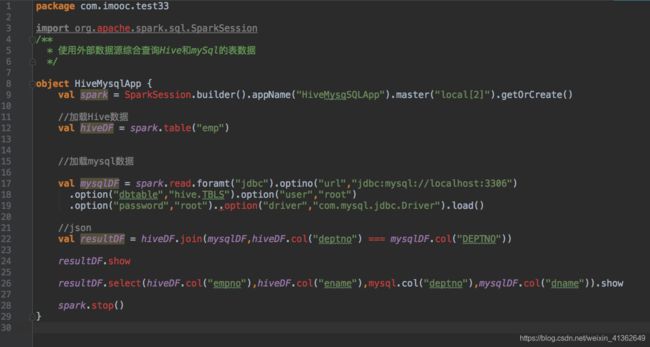
6、综合使用
外部数据源综合案例
create database spark;
use spark;
CREATE TABLE DEPT(
DEPTNO int(2) PRIMARY KEY,
DNAME VARCHAR(14),
LOC VARCHAR(13)
);
INSERT INTO DEPT VALUES(10,’ACCOUNTING’,’NEW YORK’);
INSERT INTO DEPT VALUES(20,’RESEARCH’,’DALLAS’);
INSERT INTO DEPT VALUES(30,’SALES’,’CHICAGO')
INSERT INTO DEPT VALUES(40,’OPERATIONS’,’BOSTON’)