Storm集群的搭建和使用入门
Storm
- Storm是一个流式计算框架,数据源源不断的产生,源源不断的收集,源源不断的计算。(数据实时产生、实时传输、实时计算、实时展示)
- Storm只负责数据的计算,不负责数据的存储。
- 2013年前后,阿里巴巴基于storm框架,使用java语言开发了类似的流式计算框架佳作,Jstorm。2016年年底阿里巴巴将源码贡献给了Apache storm,两个项目开始合并,新的项目名字叫做storm2.x。
Storm的架构图:
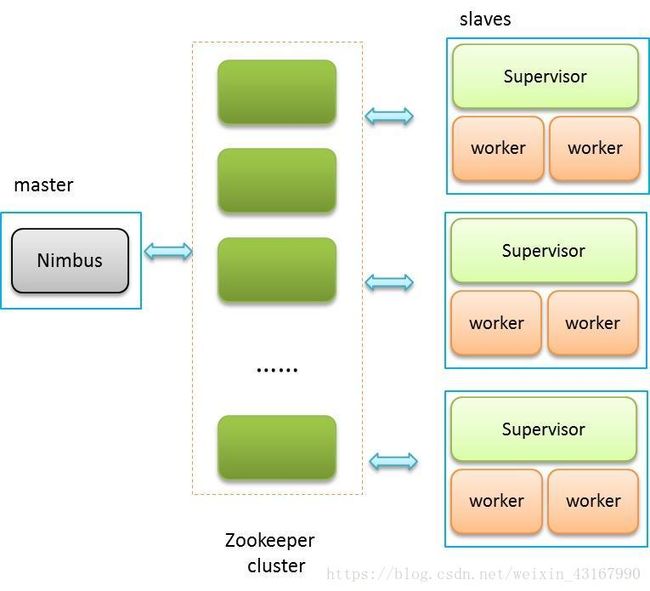
其中:
- Nimbus:负责资源分配和任务调度。
- Supervisor:负责接受nimbus分配的任务,启动和停止属于自己管理的worker进程。
- Worker:运行具体处理组件逻辑的进程。
- Task:worker中每一个spout/bolt的线程称为一个task. 在storm0.8之后,task不再与物理线程对应,同一个spout/bolt的task可能会共享一个物理线程,该线程称为executor。
Storm编程模型

- DataSource: 数据源
- Spout:在一个topology中产生源数据流的组件。通常情况下spout会从外部数据源中读取数据,然后转换为topology内部的源数据。Spout是一个主动的角色,其接口中有个nextTuple()函数,storm框架会不停地调用此函数,用户只要在其中生成源数据即可。
- Bolt:在一个topology中接受数据然后执行处理的组件。Bolt可以执行过滤、函数操作、合并、写数据库等任何操作。Bolt是一个被动的角色,其接口中有个execute(Tuple input)函数,在接受到消息后会调用此函数,用户可以在其中执行自己想要的操作。
- Tuple:一次消息传递的基本单元。本来应该是一个key-value的map,但是由于各个组件间传递的tuple的字段名称已经事先定义好,所以tuple中只要按序填入各个value就行了,所以就是一个value list.
- Stream:源源不断传递的tuple就组成了stream。
- Topology:Storm中运行的一个实时应用程序,因为各个组件间的消息流动形成逻辑上的一个拓扑结构。
分组策略
- 随机分组(Shuffle grouping):随机分发tuple到Bolt的任务,保证每个任务获得相等数量的tuple。 跨服务器通信,浪费网络资源,尽量不适用
- 字段分组(Fields grouping):根据指定字段分割数据流,并分组。例如,根据“user-id”字段,相同“user-id”的元组总是分发到同一个任务,不同“user-id”的元组可能分发到不同的任务。 跨服务器,除非有必要,才使用这种方式。
- LocalOrShuffle 分组。 优先将数据发送到本地的Task,节约网络通信的资源。(常用)
安装运行
安装搭建
-
前期准备
准备搭建3节点集群,准备3个虚拟机node1,node2,node3
配置好hosts映射文件和互相的ssh免密登录
配置好JDK
storm是依赖于zookeeper的,搭建storm集群前,必须先把zookeeper集群搭建好 -
安装storm
1 ) 准备好storm安装包apache-storm-1.1.1.tar.gz,下载地址:
http://storm.apache.org/downloads.html
2 ) 上传解压重命名为storm到/export/server路径下
3 ) 修改配置文件 storm.yamlcd /export/server/storm/conf/
vi storm.yaml添加如下配置:
# 指定storm使用的zookeeper集群 storm.zookeeper.servers: - "node1" - "node2" - "node3" # 指定storm集群中的nimbus节点所在的服务器 nimbus.seeds: ["node1", "node2", "node3"] # 指定storm文件存放目录 storm.local.dir: "/export/data/storm" # 指定supervisor节点上,启动worker时对应的端口号,每个端口对应槽,每个槽位对应一个worker supervisor.slots.ports: - 6700 - 6701 - 6702 - 67034 ) 分发到其他节点
scp -r /export/server/storm node2:/export/server/
scp -r /export/server/storm node3:/export/server/
运行
-
前台启动 (前台启动会占用窗口)
1 ) 在node1上启动 nimbus进程(主节点) 和 web UIcd /export/server/storm/bin
storm nimbus克隆一个node1的连接窗口
cd /export/server/storm/bin
storm ui2 ) 在 node2 和 node3 上启动 supervisor(从节点)
cd /export/server/storm/bin
storm supervisor -
后台启动 (这里直接把命令写入了脚本通过ssh实现一键启动)
#!/bin/bash source /etc/profile nohup /export/server/storm/bin/storm nimbus >/dev/null 2>&1 & echo "node1 nimbus is running" nohup /export/server/storm/bin/storm ui >/dev/null 2>&1 & echo "node1 core is running" for host in node2 node3 do { ssh $host "source /etc/profile;nohup /export/server/storm/bin/storm supervisor >/dev/null 2>&1 &" echo "$host Supervisor is running" } donenohup,表示不挂起的意思( no hang up) ,忽略所有挂断信号。要运行后台中的 nohup 命令,添加 & 到命令的尾部。
/dev/null,表示空设备文件
2>&1,2就是标准错误,1是标准输出,2>&1表示把标准错误重定向到标准输出么
&,表示即使终端关闭程序仍会运行(前提是你把程序递交到服务器上)
所以,像这样的命令
nohup /export/server/storm/bin/storm nimbus >/dev/null 2>&1 &就表示后台启动程序并且不输出启动日志文件 -
进入web页面查看集群
浏览器登入node1:8080

进入web页面后可以查看Nimbus主节点信息, 其中node1是主节点
如果在node2或node3上也执行了storm nimbus命令那么其会作为主节点备份, 状态会显示为 Not a Leader :

在Topology summary(Topology信息)中可以看到Topology程序的名称, 所有者, 状态, 运行时间和程序运行的其他相关信息包括worker数量,进程数量等, 这些可以在编写程序时在代码中指定; 也可以通过点击Topology程序的名称进入下级页面查看更详细的任务信息

web页面中还有Supervisor Summary(从节点信息)和Nimbus Configuration(主节点配置)等内容…
使用入门
处理日志数据
-
依赖
org.apache.storm storm-core 1.1.1 -
编写Spout类读取日志文件中的内容, 并把数据发送给下游Bolt类进行处理
/*** * Version: * Description: 读取外部文件,把一行一行的数据发送给下游的bolt * 类似于hadoop mapreduce的inputformat ***/ public class ReadFileSpout extends BaseRichSpout { private SpoutOutputCollector spoutOutputCollector; private BufferedReader bufferedReader; /** * 初始化方法, 类似于这个类的构造器, 只被运行一次 * 一般用来打开数据链接, 打开网络连接 * @param map 传入的是storm集群的配置文件和用户自定义的配置文件, 一般不用 * @param topologyContext 上下文对象, 一般不用 * @param spoutOutputCollector 数据输出的收集器,spout把数据传给此参数,由此参数传给storm框架 */ public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { try { //本地模式 //this.bufferedReader = new BufferedReader(new FileReader(new File("D:\\wordcount.txt"))); //集群模式 this.bufferedReader = new BufferedReader(new FileReader(new File("//root//stormdata//wordcount.txt"))); } catch (FileNotFoundException e) { e.printStackTrace(); } this.spoutOutputCollector = spoutOutputCollector; } /** * 下一个tuple, tuple是数据传送的基本单位 * 后台有个while方法一直调用该方法, 每调用一次就发送一个tuple出去 */ public void nextTuple() { String line = null; try { //一行一行的读取文件内容,并且一行一行的发送 line = bufferedReader.readLine(); if (line != null){ spoutOutputCollector.emit(Arrays.asList(line)); } } catch (IOException e) { e.printStackTrace(); } } /** * 通过字段声明发出的数据是什么 * @param outputFieldsDeclarer */ public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields("line")); } } -
编写Bolt类对出入的内容进行单词切分
/*** * Description: 输入一行一行的数据 * 对一行数据进行切割 * 输出单词及单词出现的次数 ***/ public class SplitBolt extends BaseRichBolt { private OutputCollector outputCollector; /** * 初始化方法,只被运行一次 * @param map 配置文件 * @param topologyContext 上下文对象 * @param outputCollector 数据收集器 */ @Override public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) { this.outputCollector = outputCollector; } /** * 执行业务逻辑的方法 * @param tuple 获取的上游数据 */ @Override public void execute(Tuple tuple) { //获取上游句子(字段:"line") String line = tuple.getStringByField("line"); //对句子进行切割 String[] words = line.split(" "); //发送数据 for (String word : words) { //需要发送单词和单词出现的次数,总共两个字段 outputCollector.emit(Arrays.asList(word, "1")); } } /** * 声明发送出去的数据 * @param outputFieldsDeclarer */ @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields("word", "num")); } } -
编写Bolt类对单词进行计数
/*** * Description: 负责统计每个单词出现的次数, 类似于hadoop mapreduce的reduce * 输入单词及单词出现的次数 * 输出打印在控制台 ***/ public class WordCountBolt extends BaseRichBolt { //定义一个map用于储存单词及其数量 private Map -
编写启动类对程序进行整合
/*** * Description: wordcount驱动类,用来提交任务 ***/ public class WordCountTopology { public static void main(String[] args) throws InvalidTopologyException, AuthorizationException, AlreadyAliveException { //通过TopologyBuilder 封装任务信息 TopologyBuilder topologyBuilder = new TopologyBuilder(); //设置spout获取数据 //SpoutDeclarer setSpout(String id, IRichSpout spout, Number parallelism_hint):参数:自定义id, spout对象, 并发数量 topologyBuilder.setSpout("readfilesspout", new ReadFileSpout(), 2); //设置splitbolt 对句子进行切割 topologyBuilder.setBolt("splitbolt", new SplitBolt(), 4).shuffleGrouping("readfilesspout"); //设置wordcountbolt 对单词进行统计 topologyBuilder.setBolt("wordcountbolt", new WordCountBolt(), 2).shuffleGrouping("splitbolt"); //准备一个配置文件 Config config = new Config(); //启动2个worker! config.setNumWorkers(2); //任务提交有:本地模式 和 集群模式 //本地模式 //LocalCluster localCluster = new LocalCluster(); //localCluster.submitTopology("wordcount", config, topologyBuilder.createTopology()); //集群模式,参数:Topology名字, 配置文件, Topology对象 StormSubmitter.submitTopology("wordcount2", config, topologyBuilder.createTopology()); } } -
执行程序
1 ) 选择本地模式运行
直接运行驱动类的main方法即可, 统计后的结果会直接打印在控制台2 ) 选择上传到集群进行执行
首先通过maven的package命名将程序打好jar包
注意在storm-core的依赖中加入:provided
在pom文件中加入maven的打包插件:maven-assembly-plugin jar-with-dependencies com.yahaha.storm.kanban.kanbanTopolgy make-assembly package single org.apache.maven.plugins maven-compiler-plugin 3.7.0 1.8 1.8 在上传到node2或node3上, 在指定路径下要确保存在日志文件
通过storm命令执行程序:bin/storm jar storm-wordcount-1.0-SNAPSHOT.jar com.yahaha.storm.wc.WordCountTopology
当被读取的日志文件发生实时增加时, storm程序的处理也会实时同步进行!