yarn/zookeeper/solr/elasticsearch概况总结
一、Yarn简单概况
Yarn为Hadoop资源管理系统;核心是将MapReduce V2 中的JobTracker分离,创建一个全局的ResourceManager和若干个针对应用程序的ApplicationMaster。其中ResourceManager负责整个系统的资源管理和分配,而ApplicationMaster负责单个应用程序的管理。基本架构如下所示:
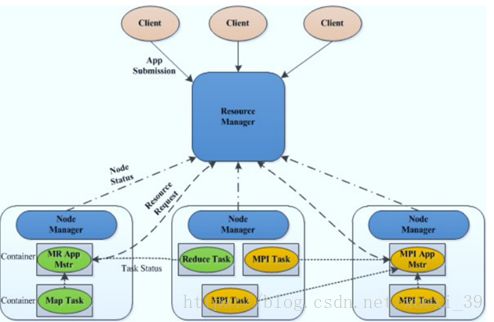
1)Yarn构成:主要由ResourceManager、NodeManager、container以及ApplicationMaster等组成;其中
ResourceManager控制整个集群并管理应用程序向基础计算资源的分配;
作用:处理客户端请求;启动和监控ApplicationMaster;监控NodeManager;资源的分配和调度。
NodeManager管理Yarn集群中的每个节点;
作用:管理单个节点上的资源;处理来自ResourceManager的命令;处理来自ApplicationMaster的命令。
ApplicaitonMaster管理Yarn内运行的每个应用程序实例;
作用:负责数据的切分;为应用程序申请资源并分配给内部的任务;任务的监控和容错。
Container是Yarn中的资源抽象;
作用:对任务运行环境进行抽象,封装CPU,内存等多维度的资源以及环境变量,启动命令等任务运行相关的信息。
2)Yarn工作流:当用户向Yarn提交一个应用程序后,
第一个阶段是启动ApplicationMaster;
第二个阶段是由ApplicationMaster创建应用程序,为它申请资源,并控制它的整个运行过程,直到运行完成为止。
3)Yarn运行步骤:
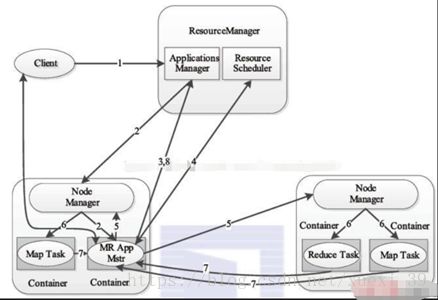
- 用户向Yarn中提交应用程序(包括ApplicationMaster程序,启动ApplicationMaster的命令,用户程序等);
- ResourceManager为该应用程序分配第一个container,并与对应的Node-Manager通信,要求Container启动应用程序ApplicationMaster;
- ApplicationMaster向ResourceManager注册,用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源并监控它的运行状态,直到结束;
- ApplicationManager采用轮询的方式通过RPC协议向ResourceManager注册和申请资源;
- 一旦ApplicationMaster申请到资源后,便与NodeManager通信,要求它启动任务;
- NodeManager为任务设置好运行环境(环境变量、jar包、二进制程序等),将任务启动命令写到一个脚本中,并通过运行该脚本启动任务;
- 各个任务通过某一个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
- 应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
二、ZooKeeper简单介绍
ZooKeeper是一种高可用、高性能且一致的开源协调服务,核心服务(分布式锁服务),还包括其他服务(配置维护、组服务、分布式消息队列、分布式通知/协调等),采用的协议是Zab协议。
实现方式:数据结构(Znode)+原语(对数据结构的操作)+watch机制(通知机制)。
1、Zookeeper数据模型Znode:
a)引用方式:Znode通过路径引用(同时是绝对路径);
b)Znode结构:兼具文件和目录两种特点。即像文件一样维护着数据、元信息、ACL、时间戳等数据结构,又像目录一样可作为路径标识的一部分,每个Znode包括三部分;stat:为状态信息,描述该Znode的版本,权限等信息;data:与该Znode关联的数据;children:该Znode下的子节点。
c)数据访问:每个节点存储的数据要被原子性的操作(即读操作将获取与节点相关的所有数据,写操作也将替换节点的所有数据);
d)节点类型:分为临时节点与永久节点。节点的类型在创建时即被确定,同时不能改变;
e)顺序节点:当创建Znode时,用户可以请求Zookeeper的路径末尾添加一个递增的计数。这个计数对于此节点的父节点来说时唯一的;
f)观察:客户端在节点上设置watch(监视器),当节点状态发生改变时将会触发watch所对应的操作。
2、Zookeeper的特点:
a)最终一致性:为客户端展示同一个视图;
b)可靠性:若消息被一台服务器接受,那么它将被所有的服务器接受;
c)实时性:Zookeeper不能保证两个客户端同时得到刚更新的数据,若要更新足心数据,应该在读数据之前调用sync()接口;
d)等待无关:慢的或者失效的client不可干预快速的client的请求;
e)原子性:更新只能成功或者失败,没有中间状态;
f)顺序性:所有的server,同一个消息发布顺序一致。
三、Zookeeper基本架构
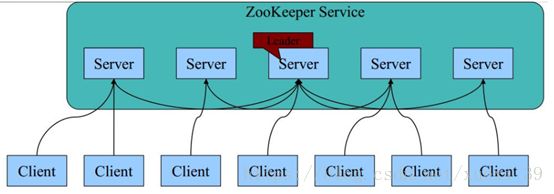
- 每个server的内存中存储了一份数据;
- Zookeeper启动时,将从实例中选举一个leader(Paxios协议);
- Leader负责处理数据更新等操作(zab协议);
- 一个更新操作成功,当且仅当大多数server在内存中成功修改数据。
三、solr简单介绍
Solr是一个独立的企业级搜索应用服务器,提供类型与webservice的API接口,用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引,也可以通过http get操作提出查找请求,并得到XML的返回结果。
Solr对外提供标准的http接口来实现对数据的索引的增加、删除、修改、查询。在solr中,用户通过向部署在servlet容器中的solr web应用程序发送http请求来启动索引和搜索。Solr接受请求,确定要使用的适当solrRequestHandler,然后处理请求,通过HTTP以同样的方式返回响应。默认配置返回solr的标准XML响应,也可以配置Solr的备用响应格式。
Solr索引向servlet传递四个不同的索引请求:
Add/update允许向solr添加文档或更新文档。直到提交后才能搜索到这些添加和更新;
Commit告诉solr,应该使得上次提交以来所做的所有更改都可以搜索到;
Optimize重构Lucene的文件以改进搜索性能,索引完成后执行一下优化较好;
Delete可以通过id或者查询来指定。按id删除或删除具有指定id的文档,按查询删除将删除查询返回的所有文档。
四、Elasticsearch简单介绍:
Elasticsearch是一个基于lucene的搜索服务器,它提供一个分布式多用户能力的全文搜索引擎,基于Restful web接口,采用倒排序索引方式。
Elasticsearch是一个分布式可扩展的实时搜索和分析引擎。它时一个建立在全文索引引擎apache lucene基础上的搜索引擎,不仅包括了全文搜索功能,还可以
分布式实时文件存储,并将每一个字段都编入索引,使其可以被索引;
实时分析的分布式搜索引擎;
可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
以上关于hadoop相关的内容,是我在初步学习hadoop相关概念时,把网上相关资料整合在一起,方便自己理解。如果有什么问题,欢迎大家可以讨论指正!