Exception in thread "main" org.apache.hadoop.hbase.DoNotRetryIOException: java.lang.IllegalAccessError: tried to access method com.google.common.base.Stopwatch.()V from class org.apache.hadoop.hbase.zookeeper.MetaTableLocator
at org.apache.hadoop.hbase.client.RpcRetryingCaller.translateException(RpcRetryingCaller.java:229)
at org.apache.hadoop.hbase.client.RpcRetryingCaller.callWithoutRetries(RpcRetryingCaller.java:202)
at org.apache.hadoop.hbase.client.ClientScanner.call(ClientScanner.java:320)
at org.apache.hadoop.hbase.client.ClientScanner.nextScanner(ClientScanner.java:295)
at org.apache.hadoop.hbase.client.ClientScanner.initializeScannerInConstruction(ClientScanner.java:160)
at org.apache.hadoop.hbase.client.ClientScanner.(ClientScanner.java:155)
at org.apache.hadoop.hbase.client.HTable.getScanner(HTable.java:821)
at org.apache.hadoop.hbase.client.MetaScanner.metaScan(MetaScanner.java:193)
at org.apache.hadoop.hbase.client.MetaScanner.metaScan(MetaScanner.java:89)
at org.apache.hadoop.hbase.client.MetaScanner.allTableRegions(MetaScanner.java:324)
at org.apache.hadoop.hbase.client.HRegionLocator.getAllRegionLocations(HRegionLocator.java:88)
at org.apache.hadoop.hbase.util.RegionSizeCalculator.init(RegionSizeCalculator.java:94)
at org.apache.hadoop.hbase.util.RegionSizeCalculator.(RegionSizeCalculator.java:81)
at org.apache.hadoop.hbase.mapreduce.TableInputFormatBase.getSplits(TableInputFormatBase.java:256)
at org.apache.hadoop.hbase.mapreduce.TableInputFormat.getSplits(TableInputFormat.java:237)
at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:301)
at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:318)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:196)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Unknown Source)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308)
at org.eminem.hadoop.ESInitCall.run(ESInitCall.java:51)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.eminem.hadoop.ESInitCall.main(ESInitCall.java:75)
Caused by: java.lang.IllegalAccessError: tried to access method com.google.common.base.Stopwatch.()V from class org.apache.hadoop.hbase.zookeeper.MetaTableLocator
at org.apache.hadoop.hbase.zookeeper.MetaTableLocator.blockUntilAvailable(MetaTableLocator.java:596)
at org.apache.hadoop.hbase.zookeeper.MetaTableLocator.blockUntilAvailable(MetaTableLocator.java:580)
at org.apache.hadoop.hbase.zookeeper.MetaTableLocator.blockUntilAvailable(MetaTableLocator.java:559)
at org.apache.hadoop.hbase.client.ZooKeeperRegistry.getMetaRegionLocation(ZooKeeperRegistry.java:61)
at org.apache.hadoop.hbase.client.ConnectionManager$HConnectionImplementation.locateMeta(ConnectionManager.java:1185)
at org.apache.hadoop.hbase.client.ConnectionManager$HConnectionImplementation.locateRegion(ConnectionManager.java:1152)
at org.apache.hadoop.hbase.client.RpcRetryingCallerWithReadReplicas.getRegionLocations(RpcRetryingCallerWithReadReplicas.java:300)
at org.apache.hadoop.hbase.client.ScannerCallableWithReplicas.call(ScannerCallableWithReplicas.java:151)
at org.apache.hadoop.hbase.client.ScannerCallableWithReplicas.call(ScannerCallableWithReplicas.java:59)
at org.apache.hadoop.hbase.client.RpcRetryingCaller.callWithoutRetries(RpcRetryingCaller.java:200)
... 26 more
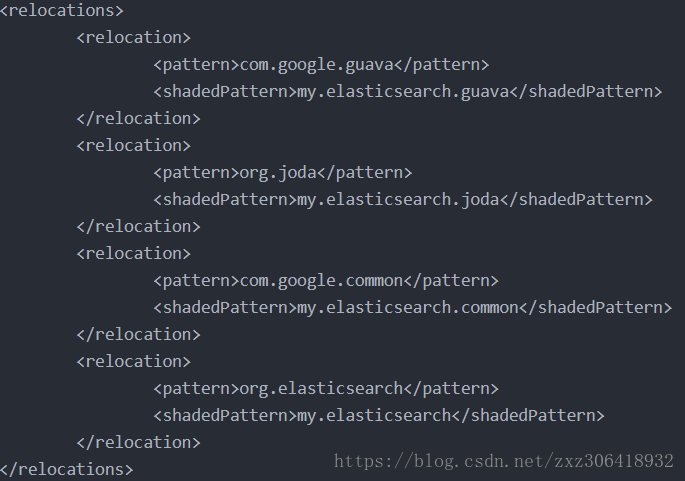
2018-08-14 14:51:15,802 FATAL [main] org.apache.hadoop.mapred.YarnChild: Error running child : java.lang.NoSuchFieldError: FAIL_ON_SYMBOL_HASH_OVERFLOW
at my.elasticsearch.common.xcontent.json.JsonXContent.(JsonXContent.java:49)
at my.elasticsearch.common.xcontent.XContentFactory.contentBuilder(XContentFactory.java:122)
at my.elasticsearch.action.index.IndexRequest.source(IndexRequest.java:382)
at my.elasticsearch.action.index.IndexRequest.source(IndexRequest.java:372)
at my.elasticsearch.action.update.UpdateRequest.doc(UpdateRequest.java:472)
at my.elasticsearch.action.update.UpdateRequestBuilder.setDoc(UpdateRequestBuilder.java:163)
at org.eminem.hadoop.mapper.ESInitMapper.map(ESInitMapper.java:135)
at org.eminem.hadoop.mapper.ESInitMapper.map(ESInitMapper.java:1)
at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:146)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1724)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:162)
利用JavaScript进行对象排序,根据用户的年龄排序展示
<script>
var bob={
name;bob,
age:30
}
var peter={
name;peter,
age:30
}
var amy={
name;amy,
age:24
}
var mike={
name;mike,
age:29
}
var john={
FLP
One famous theory in distributed computing, known as FLP after the authors Fischer, Lynch, and Patterson, proved that in a distributed system with asynchronous communication and process crashes,
每一行命令都是用分号(;)作为结束
对于MySQL,第一件你必须牢记的是它的每一行命令都是用分号(;)作为结束的,但当一行MySQL被插入在PHP代码中时,最好把后面的分号省略掉,例如:
mysql_query("INSERT INTO tablename(first_name,last_name)VALUES('$first_name',$last_name')");
题目链接:zoj 3820 Building Fire Stations
题目大意:给定一棵树,选取两个建立加油站,问说所有点距离加油站距离的最大值的最小值是多少,并且任意输出一种建立加油站的方式。
解题思路:二分距离判断,判断函数的复杂度是o(n),这样的复杂度应该是o(nlogn),即使常数系数偏大,但是居然跑了4.5s,也是醉了。 判断函数里面做了3次bfs,但是每次bfs节点最多