关于字符集和字符编码基础知识的梳理
一、基础知识
1. 二进制
计算机普遍遵循冯诺依曼结构体系,它规定了计算机内部以二进制为主要数制,所以计算机只认识二进制的0或1。其它符号比如十进制的[2-9]、字母[a-zA-Z]、标点符号、中文等等计算机是不认识的。那么,当我们说"a"的时候,它是怎么理解的呢?
2. 编码表
即然计算机只认识0、1符号,那可以建立一套"映射系统",比如
a<--> 00000001
b<--> 00000010
c<--> 00000011
当我们说"a"的时候,计算机就理解为"00000001",即一个符号,用一串唯一的二进制表示,这套"映射系统"就称为编码表。计算机世界里面到处都体现着映射的思想。
3. ASCII编码表
早期的计算机只在欧美国家使用,所以这套"映射系统"是根据英文规则设计的,叫ASCII表,规定用8位长度的二进制表示一个字符,最多可以表示 2^8 = 256 个字符。ASCII表涵盖了英文字母,数字,和常用的英文符号,比如",.+-"等;但是普通汉字至少6万多个,很明显8位的ASCII编码方案满足不了中文系统的要求,比如中文 "啊"就无法用ASCII表示。
4. 中文编码表
综上所述,我们可以推理,只要再设计一套长度更大的"映射系统"就可以解决问题了,比如
啊 = 00000000 00000001
哦 = 00000000 00000010
即使用16位二进制(两字节)表示一个汉字,最多可表示 2^16 = 65536 个汉字。
5. 全角与半角
计算机只认识二进制01,所有的字形符号都是通过编码表(映射系统)翻译实现的
在英文系统的编码表里,有用1字节表示的标点符号,如英文逗号","
在中文系统的编码表里,有用N(1-4)字节表示的标点符号,如中文逗号",”
语义上我们统称为逗号,但计算机实际表现形式是不同的
英文逗号"," 在ASCII编码下是 00101100,一字节长,屏幕打印宽度是一个宽度
中文逗号"," 在GBK编码下是 10100011 10101100,两字节长,屏幕打印宽度是两个宽度
半角就是指 ASCII 编码表以内的标点符号,它们都是占一个字节,一个打印宽度的
全角就是指在ASCII编码表以外,如GBK,BIG5, Unicode等编码规则下的,多字节的标点符号,屏幕打印宽度通常是两个宽度,即一个汉字宽度。
简言之,ASCII以内的就叫半角符号,以外的就叫全角符号。
二、常见字符集
字符(Character)是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。字符集(Character set)是多个字符的集合,字符集种类较多,每个字符集包含的字符个数不同,常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、 GB18030字符集、Unicode字符集等。
ASCII(American StandardCode for Information Interchange,美国信息互换标准编码)是基于罗马字母表的一套电脑编码系统。7位(bits)表示一个字符,共128字符,字符值从0到127,其中32到126是可打印字符。7位编码的字符集只能支持128个字符,为了表示更多的欧洲常用字符对ASCII进行了扩展,ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。ASCII扩展字符集:它是从ASCII字符集扩充出来的,扩充后的符号增加了表格符号、计算符号、希腊字母和特殊的拉丁符号。
GB2312又称为GB2312-80字符集,全称为《信息交换用汉字编码字符集·基本集》,由原中国国家标准总局发布,1981年5月1日实施。GB2312是中国国家标准的简体中文字符集。它所收录的汉字已经覆盖99.75%的使用频率,基本满足了汉字的计算机处理需要。在中国大陆和新加坡获广泛使用。GB2312收录简化汉字及一般符号、序号、数字、拉丁字母、日文假名、希腊字母、俄文字母、汉语拼音符号、汉语注音字母,共 7445 个图形字符。其中包括6763个汉字,其中一级汉字3755个,二级汉字3008个;包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
BIG5又称大五码或五大码,1984年由台湾财团法人信息工业策进会和五家软件公司宏碁 (Acer)、神通 (MiTAC)、佳佳、零壹 (Zero One)、大众 (FIC)创立,故称大五码。
GBK编码,是在GB2312-80标准基础上的内码扩展规范,使用了双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字,完全兼容GB2312-80标准,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字。GBK编码方案于1995年10月制定, 1995年12月正式发布
GB 18030的全称是GB18030-2000《信息交换用汉字编码字符集基本集的扩充》,是我国政府于2000年3月17日发布的新的汉字编码国家标准,2001年8月31日后在中国市场上发布的软件必须符合本标准。
Unicode字符集编码是UniversalMultiple-Octet Coded Character Set 通用多八位编码字符集的简称,是由一个名为Unicode 学术学会(Unicode Consortium)的机构制订的字符编码系统,支持现今世界各种不同语言的书面文本的交换、处理及显示。该编码于1990年开始研发,1994年正式公布,最新版本是2012年1月31日的Unicode 6.1。Unicode是一种在计算机上使用的字符编码。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
UTF-8(8-bit UnicodeTransformation Format)是一种针对Unicode的可变长度字符编码,又称万国码。UTF-8是Unicode的其中一个使用方式。 UTF是 Unicode Tranformation Format,即把Unicode转做某种格式的意思。UTF-8便于不同的计算机之间使用网络传输不同语言和编码的文字,使得双字节的Unicode能够在现存的处理单字节的系统上正确传输。UTF-8使用可变长度字节来储存 Unicode字符,例如ASCII字母继续使用1字节储存,重音文字、希腊字母或西里尔字母等使用2字节来储存,而常用的汉字就要使用3字节。
三、关于BOM头
所谓BOM头(Byte Order Mark)就是文本文件中开始的几个并不表示任何字符的字节,用二进制编辑器(如bz.exe)就能看到了。
UTF8的BOM头为 0xEF 0xBB0xBF
Unicode大端模式为 0xFE0xFF
Unicode小端模式为 0xFF0xFE
四、Unicode与UTF-8的转换
因为英文字符也全部使用双字节,存储成本和流量会大大地增加,所以Unicode编码大多数情况并没有被原始地使用,而是被转换编码成UTF8。下表就是其转换公式:
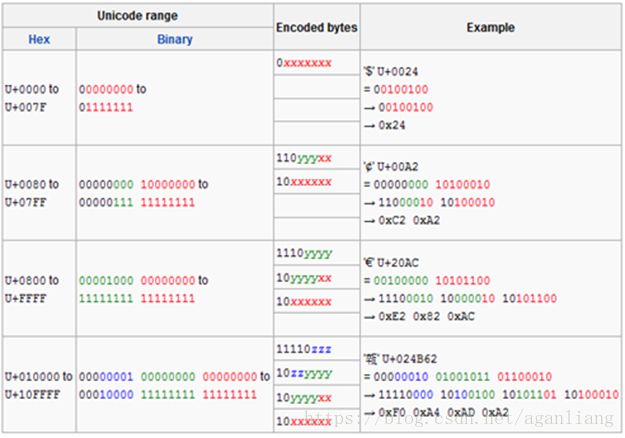
第一种:Unicode从 0x0000 到 0x007F 范围的,是不是有点熟悉?对,其实就是标准ASCII码里面的内容,所以直接去掉前面那个字节 0x00,使用其第二个字节(与ASCII码相同)作为其编码,即为单字节UTF8。
第二种:Unicode从 0x0080 到 0x07FF 范围的,转换成双字节UTF8。
第三种:Unicode从 0x8000 到 0xFFFF 范围的,转换成三字节UTF8,一般中文都是在这个范围里。
第四种:超过双字节的Unicode目前还没有广泛支持,仅见emoji表情在此范围。
【扩展阅读】:
浅谈文字编码和Unicode
http://www.fmddlmyy.cn/text16.html
http://www.fmddlmyy.cn/text17.html
谈谈Unicode编码,简要解释UCS、UTF、BMP、BOM等名词
http://www.fmddlmyy.cn/text6.html
谈谈Windows程序中的字符编码
http://www.fmddlmyy.cn/text7.html