Big Mart Sales:预测销售结果 |Python
BigMart的数据科学家收集了2013年不同城市的10家商店中共1599种产品的销售数据(训练集),目的是建立预测模型并预测给定商店中每种产品的销售情况(测试集)。显然,这是一个回归问题。本篇文章将对测试集数据的结果进行预测。
训练集的数据形式如下:

变量描述如下:
Item_Identifier:产品编号
Item_Weight:产品重量
Item_Fat_Content:产品是否低脂肪
Item_Visibility:商店分配给特定产品的展示区域在所有产品的总展示区域的百分比
Item_Type:产品类别
Item_MRP:产品的最高零售价
Outlet_Identifier:商店编号
Outlet_Establishment_Year:商店建立年份
Outlet_Size:商店的占地面积
Outlet_Location_Type:商店所在城市的类别
Outlet_Type:商店是杂货店还是某种超市
Item_Outlet_Sales:销售额。这是要预测的结果变量。
本篇文章将按照以下内容进行阐述:
导入库和数据
数据描述性分析
数据清洗
特征工程
建立模型
导入库和数据
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.model_selection import cross_val_score,KFold,GridSearchCV
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor,ExtraTreesRegressor,AdaBoostRegressor
train_data=pd.read_csv(r'C:\Users\****\Desktop\data\Big Mart Sales\train.csv')
test_data=pd.read_csv(r'C:\Users\****\Desktop\data\Big Mart Sales\test.csv')
train_data.head()

为了便于分析,将数据集合并:
train_data['Source']='train'
test_data['Source']='test'
dataset=pd.concat(objs=[train_data,test_data],axis=0).reset_index(drop=True)
print(train_data.shape,test_data.shape,dataset.shape)
(8523, 13) (5681, 12) (14204, 13)
数据描述性分析
首先看一下数据是否有缺失值:
dataset.isnull().sum()

变量Item_Outlet_Sales是目标变量,它的缺失值是测试集中的值,不用考虑。在数据清洗的时候,将会对变量Item_Weight和Outlet_Size的缺失值进行填充。
接着看下数值型变量的一些统计量的信息:
dataset.describe()

可以发现:
变量Item_Visibility的最小值是0,这样的数据没有实际意义,因为当产品在商店中售卖时,其展示区域不可能为0,可以将其作为缺失值处理;
变量Outlet_Establishment_Year的取值范围是1985-2009,表示商店建立年份,可以将该变量转换为商店建立时长。
对于分类变量,可以看一下变量的取值:
categorical_columns=[x for x in dataset.dtypes.index if dataset.dtypes[x]=='object']
categorical_columns=[x for x in categorical_columns if x not in ['Item_Identifier','Outlet_Identifier','Source']]
for col in categorical_columns:
print('\nFrequency of Categories for Varible {}'.format(col))
print(dataset[col].value_counts())

可以发现:
变量Item_Fat_Content的取值"Low Fat",“LF”,和"Low fat"含义相同,"Regular"和"reg"的含义相同;
特征工程
观察变量Item_Identifier发现,其取值以FD,DR,NC开头,即Food,Drinks和Non-Consumables,可以用该变量创建一个新的变量Item_Type_Combined:
dataset['Item_Type_Combined']=dataset['Item_Identifier'].apply(lambda x:x[0:2])
dataset['Item_Type_Combined']=dataset['Item_Type_Combined'].map({'FD':'Food','NC':'Non-Consumable','DR':'Drink'})
dataset['Item_Type_Combined'].value_counts()
Food 10201
Non-Consumable 2686
Drink 1317
Name: Item_Type_Combined, dtype: int64
对于变量Item_Fat_Content,可以将意思相同的样本合并起来:
dataset['Item_Fat_Content'].replace({'LF':'Low Fat','reg':'Regular','low fat':'Low Fat'},inplace=True)
dataset['Item_Fat_Content'].value_counts()
Low Fat 9185
Regular 5019
Name: Item_Fat_Content, dtype: int64
对于变量Item_Visibility,将其取值0转换为缺失值:
dataset.loc[dataset['Item_Visibility']==0,'Item_Visibility']=np.nan
dataset['Item_Visibility'].isnull().sum()
879
对于变量Outlet_Establishment_Year,将其转换为建成时长:
dataset['Outlet_Year']=2013-dataset['Outlet_Establishment_Year']
dataset['Outlet_Year'].value_counts()
28 2439
26 1553
14 1550
9 1550
16 1550
11 1548
4 1546
6 1543
15 925
Name: Outlet_Year, dtype: int64
数据清洗
在处理缺失值之前,我将所有分类变量转换成数值型变量,并绘制所有变量之间的热力图,结果如下:

如图,可以看到各变量之间的相关系数,本篇文章对所有缺失值的处理将基于上图。
对于变量Item_Weight,它与其它所有变量之间的相关系数都很小,但相对地,它与变量Item_Identifier之间的相关系数最大。因此,将基于不同的Item_Identifier分组下变量Item_Weight的均值来填充缺失值:
item_avg_weight=dataset.groupby('Item_Identifier')['Item_Weight'].mean()
miss_bool=dataset['Item_Weight'].isnull()
dataset['Item_Weight'].fillna(0,inplace=True)
for index,row in dataset.iterrows():
if (row['Item_Weight']) == 0:
dataset.loc[index,'Item_Weight']=item_avg_weight[row['Item_Identifier']]
dataset['Item_Weight'].isnull().sum()
0
对于变量Outlet_Size,可以发现它与变量Outlet_Location_Type,Outlet_Identifier的相关系数较大,与变量Outlet_Type,Outlet_Year的相关系数次之。先观察变量Outlet_Size与其它四个变量之间的取值关系:
dataset.groupby(['Outlet_Location_Type','Outlet_Size'])['Outlet_Size'].count()
Outlet_Location_Type Outlet_Size
Tier 1 Medium 1550
Small 2430
Tier 2 Small 1550
Tier 3 High 1553
Medium 3105
Name: Outlet_Size, dtype: int64
dataset.groupby(['Outlet_Identifier','Outlet_Size'])['Outlet_Size'].count()
Outlet_Identifier Outlet_Size
OUT013 High 1553
OUT018 Medium 1546
OUT019 Small 880
OUT027 Medium 1559
OUT035 Small 1550
OUT046 Small 1550
OUT049 Medium 1550
Name: Outlet_Size, dtype: int64
dataset.groupby(['Outlet_Type','Outlet_Size'])['Outlet_Size'].count()
Outlet_Type Outlet_Size
Grocery Store Small 880
Supermarket Type1 High 1553
Medium 1550
Small 3100
Supermarket Type2 Medium 1546
Supermarket Type3 Medium 1559
Name: Outlet_Size, dtype: int64
dataset.groupby(['Outlet_Year','Outlet_Size'])['Outlet_Size'].count()
Outlet_Year Outlet_Size
4 Medium 1546
9 Small 1550
14 Medium 1550
16 Small 1550
26 High 1553
28 Medium 1559
Small 880
Name: Outlet_Size, dtype: int64
可以发现,变量Item_Identifier与Item_Year不合适填充Outlet_Size的缺失值,因为变量Item_Size不是缺失值的样本没有遍历这两个变量,即对于变量Item_Identifier与Item_Year在某些取值下的样本中,变量Item_Size全是缺失值。因此,使用变量Item_Location_Type和Outlet_Type填充变量Outlet_Size的缺失值:
dataset.loc[(dataset['Outlet_Location_Type']=='Tier 2')&(dataset['Outlet_Size'].isnull()),'Outlet_Size']='Small'
dataset.loc[(dataset['Outlet_Type']=='Grocery Store')&(dataset['Outlet_Size'].isnull()),'Outlet_Size']='Small'
dataset.loc[(dataset['Outlet_Type']=='Supermarket Type2')&(dataset['Outlet_Size'].isnull()),'Outlet_Size']='Medium'
dataset.loc[(dataset['Outlet_Type']=='Supermarket Type3')&(dataset['Outlet_Size'].isnull()),'Outlet_Size']='Medium'
dataset['Outlet_Size'].isnull().sum()
0
对于变量Item_Visibility,与变量Outlet_Type的相关系数最大,可以使用该变量进行缺失值的填充:
dataset.groupby(['Outlet_Type'])['Item_Visibility'].mean()
Outlet_Type
Grocery Store 0.110926
Supermarket Type1 0.064380
Supermarket Type2 0.064257
Supermarket Type3 0.064303
Name: Item_Visibility, dtype: float64
dataset.loc[(dataset['Outlet_Type']=='Grocery Store')&(dataset['Item_Visibility'].isnull()),'Item_Visibility']=0.110926
dataset.loc[(dataset['Outlet_Type']=='Supermarket Type1')&(dataset['Item_Visibility'].isnull()),'Item_Visibility']=0.064380
dataset.loc[(dataset['Outlet_Type']=='Supermarket Type2')&(dataset['Item_Visibility'].isnull()),'Item_Visibility']=0.064257
dataset.loc[(dataset['Outlet_Type']=='Supermarket Type3')&(dataset['Item_Visibility'].isnull()),'Item_Visibility']=0.064303
dataset['Item_Visibility'].isnull().sum()
0
填充完缺失值之后,可以看一下该变量的数据分布状况:
sns.distplot(dataset['Item_Visibility'],label='Skew:%.2f'%(dataset['Item_Visibility'].skew()))
plt.legend()
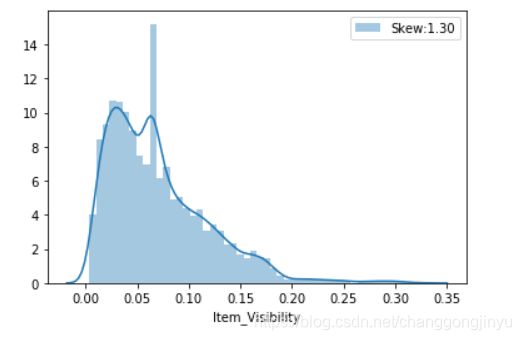
可以看到,有一点右偏,可以对该变量进行对数变换:
dataset['Item_Visibility']=dataset['Item_Visibility'].map(lambda i:np.log(i) if i>0 else 0)
sns.distplot(dataset['Item_Visibility'],label='Skew:%.2f'%(dataset['Item_Visibility'].skew()))
plt.legend()
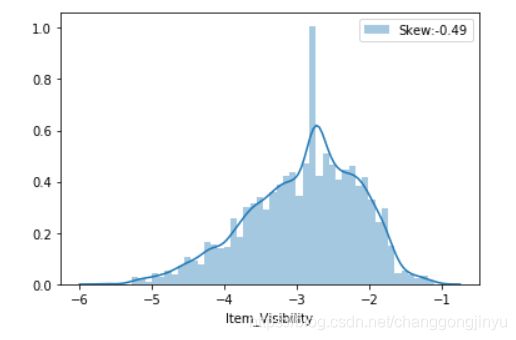
接下来,对分类变量转换成数值型变量:
le=LabelEncoder()
columns=['Item_Fat_Content','Item_Type','Outlet_Identifier','Outlet_Location_Type','Outlet_Size','Outlet_Type','Item_Type_Combined']
for i in columns:
dataset[i]=le.fit_transform(dataset[i])
dataset=pd.get_dummies(dataset,columns=columns)
dataset.head()
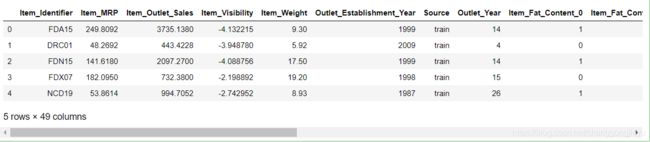
在建立模型之前,需要还原数据集,删掉多余的变量,并将测试集中的两列代表编号的数据提取出来:
dataset.drop(['Item_Identifier','Outlet_Establishment_Year','Item_Type_Combined_0','Item_Type_Combined_1','Item_Type_Combined_2'],axis=1,inplace=True)
train_data=dataset.loc[dataset['Source']=='train']
test_data=dataset.loc[dataset['Source']=='test']
train_data.drop(['Source'],axis=1,inplace=True)
test_data.drop(['Source','Item_Outlet_Sales'],axis=1,inplace=True)
test_data=test_data.reset_index()
ID=test_data[['Item_Identifier','Outlet_Identifier']]
train_data.head()

建立模型
首先,建立一个函数,该函数可以输入算法训练数据,进行交叉验证,预测并将结果保存至csv文件:
target='Item_Outlet_Sales'
predictors=[x for x in train_data.columns if x not in [target]]
def model(alg,train_data,test_data,predictors,target,filename):
alg.fit(train_data[predictors],train_data[target])
predictions=alg.predict(train_data[predictors])
cv_score=cross_val_score(alg,train_data[predictors],train_data[target],cv=20,scoring='neg_mean_squared_error')
cv_score=np.sqrt(np.abs(cv_score))
mse=mean_squared_error(train_data[target].values,predictions)
print('\nModel Report')
print('RMSE:{:.4}'.format(np.sqrt(mse)))
print('CV Score:Mean - {:.4} | Std - {:.4} | Min - {:.4} | Max - {:.4}'.format(np.mean(cv_score),np.std(cv_score),np.min(cv_score),np.max(cv_score)))
test_data[target]=alg.predict(test_data[predictors])
submission=pd.concat(objs=[ID,test_data[target]],axis=1)
submission.to_csv(filename,index=False)
首先进行线性回归:
LR=LinearRegression()
model(LR,train_data=train_data,test_data=test_data,predictors=predictors,target=target,filename='LinearRegression.csv')
coef=pd.Series(LR.coef_,predictors).sort_values()
coef.plot(kind='bar',title='Modle Cofficients')

LB Score: 1203
决策树回归:
decision_tree=DecisionTreeRegressor(max_depth=10,min_samples_leaf=150)
model(decision_tree,train_data,test_data,predictors=predictors,target=target,filename='DecisionTreeRegressor.csv')
coef=pd.Series(decision_tree.feature_importances_,predictors).sort_values(ascending=False)
coef.plot(kind='bar',title='Modle Cofficients')

LB Score:1156
随机森林:
random_forest=RandomForestRegressor(n_estimators=100,max_depth=6,min_samples_leaf=100)
model(random_forest,train_data,test_data,predictors=predictors,target=target,filename='RandomForestRegressor.csv')
coef=pd.Series(random_forest.feature_importances_,predictors).sort_values(ascending=False)
coef.plot(kind='bar',title='Modle Cofficients')

LB Score:1152.65
相比决策树,随机森林的得分有一定的提升。关于参数的选定,我尝试了多种参数取值的组合,最终选取了结果最好的参数。
GrdientBossting 回归:
kfold=KFold(n_splits=20)
X_train=train_data[predictors]
Y_train=train_data[target]
param_grid={'n_estimators':[100,200,300],'learning_rate':[0.1,0.2],'max_depth':[6],'min_samples_leaf':[200,300],'subsample':[0.7],'alpha':[0.8,0.9]}
gbc=GridSearchCV(estimator=GradientBoostingRegressor(),param_grid=param_grid,cv=kfold,scoring='neg_mean_squared_error',verbose=True)
gbc.fit(X_train,Y_train)
print(gbc.best_estimator_)

经过了多次超参数搜索,在我尝试的参数中,由下面的参数组合的模型预测得最好:
GBM=GradientBoostingRegressor(n_estimators=100,learning_rate=0.1,max_depth=6,min_samples_leaf=300,subsample=0.7,alpha=0.9)
model(GBM,train_data,test_data,predictors=predictors,target=target,filename='GradientBoostingRegressor.csv')

LB Score:1149.71
ExtraTrees回归:
param_grid={'n_estimators':[100,200,300],'max_depth':[6,8,10],'min_samples_leaf':[100,200,300]}
extra_trees=GridSearchCV(estimator=ExtraTreesRegressor(),param_grid=param_grid,cv=kfold,scoring='neg_mean_squared_error',verbose=True)
extra_trees.fit(X_train,Y_train)
print(extra_trees.best_estimator_)

经过了多次超参数搜索,在我尝试的参数中,由下面的参数组合的模型预测得最好:
extr=ExtraTreesRegressor(n_estimators=400,max_depth=10,min_samples_leaf=100)
model(extr,train_data,test_data,predictors=predictors,target=target,filename='ExtraTreesRegressor.csv')

LB Score:1146.95
上传至Analytics Vidhya之后,最终得分即排名如下:

参考文章:
https://www.analyticsvidhya.com/blog/2016/02/bigmart-sales-solution-top-20/