redis学习
redis学习
一、什么是redis
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
二、redis常见数据结构
1、String(可用于缓存、计数器、session共享)
可以是字符串,整数或者浮点数,对整个字符串或者字符串中的一部分执行操作,对整个整数或者浮点执行自增(increment)或者自减(decrement)操作。
字符串命令:
①get、获取存储在指定键中的值
②set、设置存储在指定键中的值
③del、删除存储在指定键中的值(这个命令可以用于所有的类型)
④incr、加一
⑤decr、减一
2、list(可用于消息队列)
一个链表,链表上的每个节点都包含了一个字符串,从链表的两端推入或者弹出元素,根据偏移量对链表进行修剪(trim),读取单个或者多个元素,根据值查找或者移除元素。
列表命令:
①rpush、将给定值推入列表的右端
②lrange、获取列表在指定范围上的所有值
③lindex、获取列表在指定范围上的单个元素
④lpop、从列表的左端弹出一个值,并返回被弹出的值
⑤llen 返回列表的长度
3、set
包含字符串的无序收集器(unordered collection)、并且被包含的每个字符串都是独一无二的。添加,获取,移除单个元素,检查一个元素是否存在于集合中,计算交集,并集,差集,从集合里面随机获取元素。
集合命令:
①sadd、将给定元素添加到集合
②smembers、返回集合包含的所有元素
③sismember、检查指定元素是否存在于集合中
④srem、检查指定元素是否存在于集合中,那么移除这个元素
4、hash
包含键值对无序散列表,添加,获取,移除当键值对,获取所有键值对。
散列命令:
①hset、在散列里面关联起指定的键值对
②hget、获取指定散列键的值
③hgetall、获取散列包含的所有键值对
④hdel、如果给定键存在于散列里面,那么移除这个键
5、zset(排行榜)
字符串成员(member)与浮点数分值(score)之间的有序映射,元素的排列顺序由分值的大小决定。添加,获取,删除单个元素,根据分值范围(range)或者成员来获取元素。
有序集合命令:
①zadd、将一个带有给定分值的成员添加到有序集合里面
②zrange、根据元素在有序排列中所处的位置,从有序集合里面获取多个元素
③zrangebyscore、获取有序集合在给定分值范围内的所有元素
④zrem、如果指定成员存在于有序集合中,那么移除这个成员
三、redis的key设计规范
简单的key存储,如 zhangsan 的存储,此时普通的需求可以满足;然而在实际业务中,往往key键的存储会非常的复杂,比如我们现在有一个需求:
++需求:根据基础数据系统中的数据字典类型查询对应的字典集合++
这时,我们需要关注的业务就变得复杂了,就不能使用常规的key键存储方式,上面的需求大致可以拆分为:
1.系统:基础数据系统
2.模块:数据字典
3.方法:根据数据字典类型查询
4.参数:字典类型
为什么要这样拆分呢?为了可读性;也为了抽象出key存储规则;因为业务复杂情况下,我们定义的key键太多时就不便于管理,也不便于查找,以 系统-模块-方法-参数 这样的规则定义,我们可以很清晰的了解redis key存储的值是做了什么事情,而且rdm中也可以以此来分组,后面会讲到。
下面贴上根据此规则定义抽象出的redis工具类:
package com.yclimb.mdm.redis;
/**
* Redis 工具类
*
* @author yclimb
* @date 2018/4/19
*/
public class RedisUtils {
/**
* 主数据系统标识
*/
public static final String KEY_PREFIX = "mdm";
/**
* 分割字符,默认[:],使用:可用于rdm分组查看
*/
private static final String KEY_SPLIT_CHAR = ":";
/**
* redis的key键规则定义
* @param module 模块名称
* @param func 方法名称
* @param args 参数..
* @return key
*/
public static String keyBuilder(String module, String func, String... args) {
return keyBuilder(null, module, func, args);
}
/**
* redis的key键规则定义
* @param module 模块名称
* @param func 方法名称
* @param objStr 对象.toString()
* @return key
*/
public static String keyBuilder(String module, String func, String objStr) {
return keyBuilder(null, module, func, new String[]{objStr});
}
/**
* redis的key键规则定义
* @param prefix 项目前缀
* @param module 模块名称
* @param func 方法名称
* @param objStr 对象.toString()
* @return key
*/
public static String keyBuilder(String prefix, String module, String func, String objStr) {
return keyBuilder(prefix, module, func, new String[]{objStr});
}
/**
* redis的key键规则定义
* @param prefix 项目前缀
* @param module 模块名称
* @param func 方法名称
* @param args 参数..
* @return key
*/
public static String keyBuilder(String prefix, String module, String func, String... args) {
// 项目前缀
if (prefix == null) {
prefix = KEY_PREFIX;
}
StringBuilder key = new StringBuilder(prefix);
// KEY_SPLIT_CHAR 为分割字符
key.append(KEY_SPLIT_CHAR).append(module).append(KEY_SPLIT_CHAR).append(func);
for (String arg : args) {
key.append(KEY_SPLIT_CHAR).append(arg);
}
return key.toString();
}
/**
* redis的key键规则定义
* @param redisEnum 枚举对象
* @param objStr 对象.toString()
* @return key
*/
public static String keyBuilder(RedisEnum redisEnum, String objStr) {
return keyBuilder(redisEnum.getKeyPrefix(), redisEnum.getModule(), redisEnum.getFunc(), objStr);
}
}
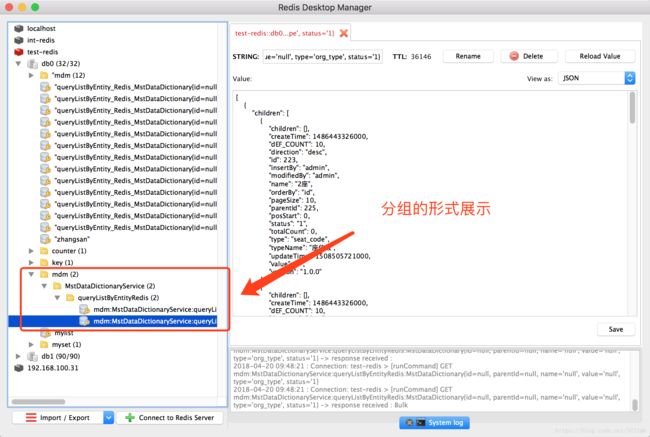
上面代码中有此文字描述 分割字符,默认[:],使用:可用于rdm分组查看 ;redis key默认使用冒号分割,好处在于可以在rdm中以文件夹的形式分组查看,如图:
四、redis的安装
1、redis5单机安装
2、redis主从和哨兵
3、redis5集群搭建
4、redis3集群搭建
5、redis配置详解
五、redis和memcache区别
1)存储方式方面
从可靠性的角度来说,redis支持持久化,有快照和AOF两种方式,而memcache是纯的内存存储,不支持持久化的。所以memcache断点后数据会丢失。
2)数据支持类型方面
从数据结构上来说,redis在kv模式上,支持5中数据结构,String、list、hash、set、zset,并支持很多相关的计算,比如排序、阻塞等,而memcache只支持kv简单存储。所以当你的缓存中不只需要存储kv模型的数据时,redis丰富的数据操作空间,绝对是非常好的选择,另外说一句,利用redis可以高效的实现类似于单集群下的阻塞队列、锁及线程通信等功能。redis的value最大可以达到1GB,而memcache只有1MB
3)内存管理方面
从内存管理方面来说,redis也有自己的内存机制,redis采用申请内存的方式,会把带过期时间的数据存放到一起,redis理论上能够存储比物理内存更多的数据,当数据超量时,会引发swap,把冷数据刷到磁盘上。而memcache把所有的数据存储在物理内存里。memcache使用预分配池管理,会提前把内存分为多个slab,slab又分成多个不等大小的chunk,chunk从最小的开始,根据增长因子增长内存大小。redis更适合做数据存储,memcache更适合做缓存,memcache在存储速度方面也会比redis这种申请内存的方式来的快。
4)数据一致方面
从数据一致性来说,memcache提供了cas命令,可以保证多个并发访问操作同一份数据的一致性问题。 redis是串行操作,所以不用考虑数据一致性的问题。
5)IO方面
从IO角度来说,redis选用的I/O多路复用模型,虽然单线程不用考虑锁等问题,但是还要执行kv数据之外的一些排序、聚合功能,复杂度比较高。memcache也选用非阻塞的I/O多路复用模型,速度更快一些。(IO多路复用中有三种方式:select,poll,epoll。需要注意的是,select,poll是线程不安全的,epoll是线程安全的。
redis内部实现采用epoll,采用了epoll+自己实现的简单的事件框架。epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性,绝不在io上浪费一点时间)
6)线程方面
从线程角度来说,memcahce使用多线程,主线程listen,多个worker子线程执行读写,可能会出现锁冲突。redis是单线程的,这样虽然不用考虑锁对插入修改数据造成的时间的影响,但是无法利用多核提高整体的吞吐量,只能选择多开redis来解决。
7)集群方面
从集群方面来说,redis天然支持高可用集群,支持主从,而memcache需要自己实现类似一致性hash的负载均衡算法才能解决集群的问题,扩展性比较低。
另外,redis集成了事务、复制、lua脚本等多种功能,功能更全。redis功能这么全,是不是什么情况下都使用redis就行了呢?
非也,redis确实比memcache功能更全,集成更方便,但是memcache相比redis在内存、线程、IO角度来说都有一定的优势,可以利用cpu提高机器性能,在不考虑扩展性和持久性的访问频繁的情况下,只存储kv格式的数据,建议使用memcache,memcache更像是个缓存,而redis更偏向与一个存储数据的系统。
六、Leveldb介绍
LevelDB是Google开源的持久化KV单机数据库,具有很高的随机写,顺序读/写性能,但是随机读的性能很一般,也就是说,LevelDB很适合应用在查询较少,而写很多的场景。LevelDB应用了LSM (Log Structured Merge) 策略,lsm_tree对索引变更进行延迟及批量处理,并通过一种类似于归并排序的方式高效地将更新迁移到磁盘,降低索引插入开销,关于LSM,本文在后面也会简单提及。
根据Leveldb官方网站的描述,LevelDB的特点和限制如下:
特点:
- 1、key和value都是任意长度的字节数组;
- 2、entry(即一条K-V记录)默认是按照key的字典顺序存储的,当然开发者也可以重载这个排序函数;
- 3、提供的基本操作接口:Put()、Delete()、Get()、Batch();
- 4、支持批量操作以原子操作进行;
- 5、可以创建数据全景的snapshot(快照),并允许在快照中查找数据;
- 6、可以通过前向(或后向)迭代器遍历数据(迭代器会隐含的创建一个snapshot);
- 7、自动使用Snappy压缩数据;
- 8、可移植性;
限制:
- 1、非关系型数据模型(NoSQL),不支持sql语句,也不支持索引;
- 2、一次只允许一个进程访问一个特定的数据库;
- 3、没有内置的C/S架构,但开发者可以使用LevelDB库自己封装一个server;
Level存储结构
1,内存的数据
内存中有两个表MemTable和Immutable MemTable
MemTable代表当前活跃的表,它主要包含Log, Manifest,以及Current三个硬盘文件,以及内存中的一个跳表SkipList。
Log是用来记录用户的写入或者删除操作,先写入log文件(按操作的顺序),再写入MemTable的SkipList中(根据key有序插入到相应的跳表位置)。
当MemTable的容量达到一定程序后,此Memtable被转换为Immutable MemTable,仍然在内存中,但可读不可写。新的MemTable被创建,并用来服务新的写入请求,至于Immutable MemTable什么时候会被写入到硬盘中,可参见数据的合并中simple compaction操作。
2,硬盘中的数据
硬盘中有多级Level的数据表,叫做SSTable
它从Level 0 到Level N,每一个级别都可能有多个sst数据表。
Level 1到Level N: 它们的每级内部的数据表之间的key是无交叉的(具体参见数据的合并)。
Level 0: Level 0比较特别,它的多个数据表的key有交叉。Level 0的每一个数据表都是直接来源于Immutable MemTable,当系统进行记录的简单合并操作时候,直接将Immutable MemTable中的跳表转换为一个sst,因此Level 0中的多个sst的key可能有交叉。
知识点
数据的合并Compaction
当需要删除数据时候,系统直接插入删除标记即可,那旧的数据什么时候才会被清除呢?这就要用到Compaction操作。有两种合并,一种是simple,一种是major。
simple compaction操作就是Immutable MemTable中的跳表转换为Level 0的一个sst(内存到硬盘)。
major compaction操作指的是Level L与Level L+1的合并操作,是层级之间的合并操作(硬盘到硬盘)。当L >=1的时候,首先选取Level L中的一个数据表,然后寻找Level L+1中的所有与Level L的key有交叉的数据表,进行多路合并。合并的一个原则就是,如果Level L中有一个key在Level L+1中存在,那么将Level L+1中的所有这样的key记录都删除即可。当L = 0,它和Level 1的合并有些特殊,我们需要选取Level 0的多个数据表(由于Level 0的key是有交叉的),与Level 1的多个数据表进行合并。
SSTable数据表的结构
数据表有多个数据块,存储有Block的索引,以及相应Block的数据。Block的大小为32KB。
缓存
有两个级别的缓存,数据表的索引缓存,数据Block的缓存。索引的缓存是默认,Block的缓存可配置。
为什么写入性能较好?
跳表是在内存中,利用了多级链表的结构,查找和插入效率高,比平衡树减少了很多节点移动的操作,因此插入速度极快;日志的写入虽然是磁盘写入,但由于是顺序写入,因此性能也很好。
为什么读取比较慢?
首先查找MemTable和Immutable MemTable,没有找到的话进入cache中查找,仍然没有找到,那么只能通过硬盘查找了。
硬盘查找首先查找Level 0,如果没有继续Level 1,直到最后一层Level,还没找到,那么不存在,如果中间任何一个地方找到了,那么直接返回。这个顺序时根据数据的新旧顺序而来的。 对于某一个Level的数据表具体查找如何执行的呢? 首先载入这个数据表的索引到内存中,查看key位于哪一个Block中,然后将相应的Block载入到内存中,逐个查找记录。 至少需要两次硬盘读取操作,很慢,顺序读因为有缓存的缘故,性能相对较好。