1.介绍:
当我们开发一个分类模型的时候,我们的目标是把输入映射到预测的概率上,当我们训练模型的时候就不停地调整参数使得我们预测出来的概率和真实的概率更加接近。
这篇文章我们关注在我们的模型假设这些类都是明确区分的,假设我们是开发一个二分类模型,那么对应于一个输入数据,我们将他标记为要么绝对是正,要么绝对是负。比如,我们输入的是一张图片,来判断这张图片是苹果还是梨子。
在训练过程中,我们可能输入了一张图片表示的是苹果,那么对于这张输入图片的真实概率分布为yi=(苹果:1,梨子:0),但是我们的模型可能预测出来的是另一种概率分布yi^(苹果:0.4,梨子:0.6),然后我们发现了在这张输入图片上的真实概率分布和预测出来的概率分布差别很大,所以我们要调整参数,来使得这两个分布更加接近。
但是我们怎么定义这个接近呢?也就是我们如何去衡量预测概率分布yi^和真实概率分布yi的接近程度?
2.熵(Entropy):
熵的概念来自物理中的热力学,表示热力学系统中的无序程度,我们说的熵是信息论中的熵,表示对不确定性的测量,熵越高,能传输的信息越多,熵越少,传输的信息越少。对发生概率较高的事件,用短比特表示;对发生概率较低的事件,用长比特表示,以此来减少传送相同信息所需要的比特长度。
也就是我们现在有了观测到的概率分布yi = P(X=xi)。我们要使用平均最小的bit,所以我们应该为xi 分配log(1/yi) 个比特。对所有的xi 我们都有一个对应的最小需要分配的bit长度,那么我们对这个log(1/yi)求期望也就得到了X的熵的定义了:
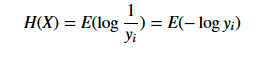

3.交叉熵(Cross-Entropy):
假如说我们用这个分布来作为我们来对事件编码的一个工具,熵就衡量了我们用这个正确的分布yi来对事件编码所能用的最小的bit 长度,我们不能用更短的bit来编码这些事件或者符号了。
相对的,交叉熵是我们要对yi这个分布去编码,但是我们用了一些模型估计分布yi^。这里的话通过yi^这个分布我们得到的关于xi的最小编码长度就变成了log(1/yi^),但是呢,我们的期望仍是关于真实分布yi的。所以交叉熵的定义就变成了:

交叉熵是大于等于熵的,因为我们使用了错误的分布yi^会带来更多的bit使用。当yi和yi^相等的时候,交叉熵就等于熵了。
4.KL 散度(KL Divergence):
KL散度和交叉熵的区别比较小,KL散度又叫做相对熵,从定义很好看出区别:
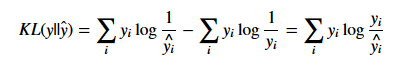
这个意思就是说我们要编码一个服从yi分布的随机变量,假设我们使用了一些数据估计出来这个随机变量的分布是yi^,那么我们需要用比真实的最小bit多多少来编码这个随机变量。这个值是大于等于0的,并且当,yi和yi^相等的时候才为0。注意这里对交叉熵求最小和对KL松散度求最小是一样的。也就是我们要调整参数使得交叉熵和熵更接近,KL松散度越接近0,也就是yi^越接近yi。
从公式可以看出,KL散度=|交叉熵|-|熵|,对于一个确定的真实概率分布yi,它的熵是不会跟随预测概率分布yi^变动的常数。因此KL散度等价于交叉熵,它们之间相差一个固定的常数值。
5.预测:
通过上面的描述和介绍,我们应该很高兴使用交叉熵来比较两个分布yi,yi^之间的不同,然后我们可以用所有训练数据的交叉熵的和来作为我们的损失,假如用n来表示我们训练数据的数量,则损失loss为:

来对这个函数求最小值我们就可以求到最好的参数来使得yi和yi^最接近。
6.概率和似然(Probability and Likelihood):
“概率”描述了给定模型参数后,描述结果的合理性,而不涉及任何观察到的数据。
抛一枚均匀的硬币,拋20次,问15次拋得正面的可能性有多大? 这里的可能性就是”概率”,均匀的硬币就是给定参数θ=0.5,“拋20次15次正面”是观测值O。求概率P(H=15|θ=0.5)=?的概率。
“似然”描述了给定了特定观测值后,描述模型参数是否合理。
拋一枚硬币,拋20次,结果15次正面向上,问其为均匀的可能性? 这里的可能性就是”似然”,“拋20次15次正面”为观测值O为已知,参数θ=?并不知道,求L(θ|H=15)=P(H=15|θ=?)的最大化下的θ 值。
在很多实际问题中,比如机器学习领域,我们更关注的是似然函数的最大值,我们需要根据已知事件(观测值)来找出产生这种结果最有可能的条件(参数θ),这就是极大似然。
7.对数似然(Log Likelihood):
似然作为衡量两个分布之间差异的测量标准更加直接,似然越大说明两个分布越接近,在分类问题中,我们会选择那些多数时候预测对了的模型。因为我们总是假设所有的数据点都是独立同分布的,对于所有数据的似然就可以定义为所有单个数据点的似然的乘积:
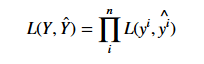
对于第n个数据他的似然怎么算呢?其实很简单,就是简单的yi*yi^,来看一下我们最初的那个例子yi={苹果:1,梨子:0},yi^={苹果:0.4,梨子:0.6},所以似然就等于:
![]()
所以这里我们是不是可以考虑一下使用极大似然估计法来求最优参数呢?也就是求似然函数的极大值点。我们来对这个似然函数动一点点手脚。
我们知道对数函数使连续单调函数,我们要求似然函数的极大值等同于我们要求对数似然函数的极大值,然后我们取一个负,就等同于求负对数似然函数的极小值:

这样,我们就可以把似然函数中的累积连乘变成累加了。而且我们知道我们的观测结果yi^中两个元素必有一个元素是1,另一个元素是0.则对数似然函数为:
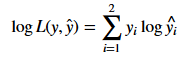
然后我们看看所有的数据的负对数似然:

看着有没有一点眼熟?这就是我们上面的所有数据的交叉熵:

8.总结:
当我们做一个分类模型的时候,我们需要一种方法去衡量真实概率分布yi和预测概率分布yi^之间的差异,然后在训练过程中调整参数来减小这个差异。在这篇文章中我们可以看到交叉熵、KL散度、对数似然其实是等价的概念,我们可以求交叉熵、KL散度和负对数似然的极小值,来减小我们的loss。