Adobe 官方公布的 RTMP 规范+未公布的部分
RTMP 规范中文版 PDF 下载地址
译序:
本文是为截至发稿时止最新 Adobe 官方公布的 RTMP 规范。本文包含 RTMP 规范的全部内容。是第一个比较全面的 RTMP 规范的中译本。由于成文时间仓促,加上作者知识面所限,翻译错误之处在所难免,恳请各位朋友热心指出,可以直接在博客后面留言,先行谢过。rtmp_specification_1.0.pdf 官方下载地址http://wwwimages.adobe.com/www.adobe.com/content/dam/Adobe/en/devnet/rtmp/pdf/rtmp_specification_1.0.pdf,国内下载地址http://download.csdn.net/detail/defonds/6312051。请随时关注官方文档更新:http://www.adobe.com/cn/devnet/rtmp.html。以下内容来自 rtmp_specification_1.0.pdf。
1. 简介
Adobe 公司的实时消息传输协议 (RTMP) 通过一个可靠地流传输提供了一个双向多通道消息服务,比如 TCP [RFC0793],意图在通信端之间传递带有时间信息的视频、音频和数据消息流。实现通常对不同类型的消息分配不同的优先级,当运载能力有限时,这会影响等待流传输的消息的次序。本文档将对实时流传输协议 (Real Time Messaging Protocol) 的语法和操作进行描述。
1.1. 术语
本文档中出现的关键字,"MUST"、"MUST NOT"、"REQUIRED"、"SHALL"、"SHALL NOT"、"SHOULD"、"SHOULD NOT"、"RECOMMENDED"、"NOT RECOMMENDED"、"MAY" 、"OPTIONAL",都将在 [RFC2119] 中进行解释。
2. 贡献者
Rajesh Mallipeddi,Adobe Systems 原成员,起草了本文档原始规范,并提供大部分的原始内容。Mohit Srivastava,Adobe Systems 成员,促成了本规范的开发。
3. 名词解释
Payload (有效载荷):包含于一个数据包中的数据,例如音频采样或者压缩的视频数据。payload 的格式和解释,超出了本文档的范围。Packet (数据包):一个数据包由一个固定头和有效载荷数据构成。一些个底层协议可能会要求对数据包定义封装。
Port (端口):"传输协议用以区分开指定一台主机的不同目的地的一个抽象。TCP/IP 使用小的正整数对端口进行标识。" OSI 传输层使用的运输选择器 (TSEL) 相当于端口。
Transport address (传输地址):用以识别传输层端点的网络地址和端口的组合,例如一个 IP 地址和一个 TCP 端口。数据包由一个源传输地址传送到一个目的传输地址。
Message stream (消息流):通信中消息流通的一个逻辑通道。
Message stream ID (消息流 ID):每个消息有一个关联的 ID,使用 ID 可以识别出流通中的消息流。
Chunk (块):消息的一段。消息在网络发送之前被拆分成很多小的部分。块可以确保端到端交付所有消息有序 timestamp,即使有很多不同的流。
Chunk stream (块流):通信中允许块流向一个特定方向的逻辑通道。块流可以从客户端流向服务器,也可以从服务器流向客户端。
Chunk stream ID (块流 ID):每个块有一个关联的 ID,使用 ID 可以识别出流通中的块流。
Multiplexing (合成):将独立的音频/视频数据合成为一个连续的音频/视频流的加工,这样可以同时发送几个视频和音频。
DeMultiplexing (分解):Multiplexing 的逆向处理,将交叉的音频和视频数据还原成原始音频和视频数据的格式。
Remote Procedure Call (RPC 远程方法调用):允许客户端或服务器调用对端的一个子程序或者程序的请求。
Metadata (元数据):关于数据的一个描述。一个电影的 metadata 包括电影标题、持续时间、创建时间等等。
Application Instance (应用实例):服务器上应用的实例,客户端可以连接这个实例并发送连接请求。
Action Message Format (AMF 动作消息格式协议):一个用于序列化 ActionScript 对象图的紧凑的二进制格式。AMF 有两个版本:AMF 0 [AMF0] 和 AMF 3 [AMF3]。
4. 字节序、对齐和时间格式
所有整数型属性以网络字节顺序传输,字节 0 代表第一个字节,零位是一个单词或字段最常用的有效位。字节序通常是大端排序。关于传输顺序的更多细节描述参考 IP 协议 [RFC0791]。除非另外注明,本文档中的数值常量都是十进制的 (以 10 为基础)。除非另有规定,RTMP 中的所有数据都是字节对准的;例如,一个十六位的属性可能会在一个奇字节偏移上。填充后,填充字节应该有零值。
RTMP 中的 Timestamps 以一个整数形式给出,表示一个未指明的时间点。典型地,每个流会以一个为 0 的 timestamp 起始,但这不是必须的,只要双端能够就时间点达成一致。注意这意味着任意不同流 (尤其是来自不同主机的) 的同步需要 RTMP 之外的机制。
因为 timestamp 的长度为 32 位,每隔 49 天 17 小时 2 分钟和 47.296 秒就要重来一次。因为允许流连续传输,有可能要多年,RTMP 应用在处理 timestamp 时应该使用序列码算法 [RFC1982],并且能够处理无限循环。例如,一个应用假定所有相邻的 timestamp 都在 2^31 - 1 毫秒之内,因此 10000 在 4000000000 之后,而 3000000000 在 4000000000 之前。
timestamp 也可以使用无符整数定义,相对于前面的 timestamp。timestamp 的长度可能会是 24 位或者 32 位。
5. RTMP 块流
本节介绍实时消息传输协议的块流 (RTMP 块流)。 它为上层多媒体流协议提供合并和打包的服务。当设计 RTMP 块流使用实时消息传输协议时,它可以处理任何发送消息流的协议。每个消息包含 timestamp 和 payload 类型标识。RTMP块流和RTMP一起适合各种音频-视频应用,从一对一和一对多直播到点播服务,到互动会议应用。
当使用可靠传输协议时,比如 TCP [RFC0793],RTMP 块流能够对于多流提供所有消息可靠的 timestamp 有序端对端传输。RTMP 块流并不提供任何优先权或类似形式的控制,但是可以被上层协议用来提供这种优先级。例如,一个直播视频服务器可能会基于发送时间或者每个消息的确认时间丢弃一个传输缓慢的客户端的视频消息以确保及时获取其音频消息。
RTMP 块流包括其自身的带内协议控制信息,并且提供机制为上层协议植入用户控制消息。
5.1 消息格式
可以被分割为块以支持组合的消息的格式取决于上层协议。消息格式必须包含以下创建块所需的字段。Timestamp:消息的 timestamp。这个字段可以传输四个字节。
Length:消息的有效负载长度。如果不能省略掉消息头,那它也被包括进这个长度。这个字段占用了块头的三个字节。
Type Id:一些类型 ID 保留给协议控制消息使用。这些传播信息的消息由 RTMP 块流协议和上层协议共同处理。其他的所有类型 ID 可用于上层协议,它们被 RTMP 块流处理为不透明值。事实上,RTMP 块流中没有任何地方要把这些值当做类型使用;所有消息必须是同一类型,或者应用使用这一字段来区分同步跟踪,而不是类型。这一字段占用了块头的一个字节。
Message Stream ID:message stream (消息流) ID 可以使任意值。合并到同一个块流的不同的消息流是根据各自的消息流 ID 进行分解。除此之外,对 RTMP 块流而言,这是一个不透明的值。这个字段以小端格式占用了块头的四个字节。
5.2 简单握手(simple handshake)
这里主要讨论的是简单握手协议。simple handshake是rtmp spec 1.0定义的握手方式。而complex handshake是后来变更的方式,Adobe没有公开。在此暂不讨论。
一个 RTMP 连接以握手开始。RTMP 的握手不同于其他协议;RTMP 握手由三个固定长度的块组成,而不是像其他协议一样的带有报头的可变长度的块。
客户端 (发起连接请求的终端) 和服务器端各自发送相同的三块。便于演示,当发送自客户端时这些块被指定为 C0、C1 和 C2;当发送自服务器端时这些块分别被指定为 S0、S1 和 S2。
5.2.1. 握手顺序
握手以客户端发送 C0 和 C1 块开始。客户端必须等待接收到 S1 才能发送 C2。
客户端必须等待接收到 S2 才能发送任何其他数据。
服务器端必须等待接收到 C0 才能发送 S0 和 S1,也可以等待接收到 C1 再发送 S0 和 S1。服务器端必须等待接收到 C1 才能发送 S2。服务器端必须等待接收到 C2 才能发送任何其他数据。
5.2.2. C0 和 S0 的格式
C0 和 S0 包都是一个单一的八位字节,以一个单独的八位整型域进行处理:
版本号 (八位):在 C0 中,这一字段指示出客户端要求的 RTMP 版本号。在 S0 中,这一字段指示出服务器端选择的 RTMP 版本号。本文档中规范的版本号为 3。0、1、2 三个值是由早期其他产品使用的,是废弃值;4 - 31 被保留为 RTMP 协议的未来实现版本使用;32 - 255 不允许使用(以区分开 RTMP 和其他常以一个可打印字符开始的文本协议)。无法识别客户端所请求版本号的服务器应该以版本 3 响应,(收到响应的) 客户端可以选择降低到版本 3,或者放弃握手。
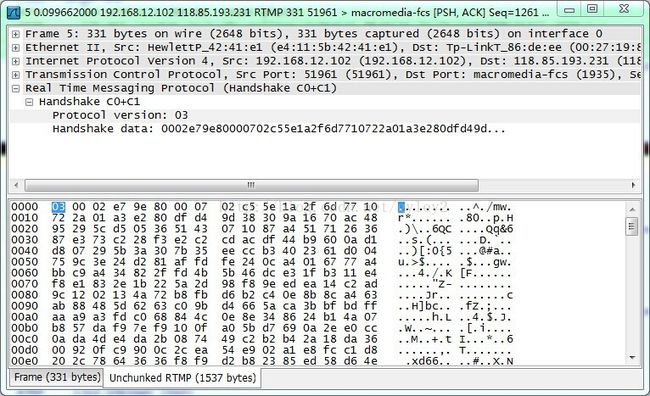
如上图,是一个c0+c1一起发送的抓包例子(complex handshake的)。其中选中的字节为c0字段,代表版本号。后面的数据是c1字段。整体包长1537.
5.2.3. C1 和 S1 的格式
C1 和 S1 数据包的长度都是 1536 字节,包含以下字段:
Zero (四个字节):这个字段必须都是 0。
Random data (1528 个字节):这个字段可以包含任意值。终端需要区分出响应来自它发起的握手还是对端发起的握手,这个数据应该发送一些足够随机的数。这个不需要对随机数进行加密保护,也不需要动态值。
5.2.4. C2 和 S2 的格式
C2 和 S2 数据包长度都是 1536 字节,基本就是 S1 和 C1 的副本 (分别),包含有以下字段:
Time2 (四个字节):这个字段必须包含终端先前发出数据包 (s1 或者 c1) timestamp。
Random echo (1528 个字节):这个字段必须包含终端发的 S1 (给 C2) 或者 S2 (给 C1) 的随机数。两端都可以一起使用 time 和 time2 字段再加当前 timestamp 以快速估算带宽和/或者连接延迟,但这不太可能是有多大用处。
5.2.5. 握手示意图
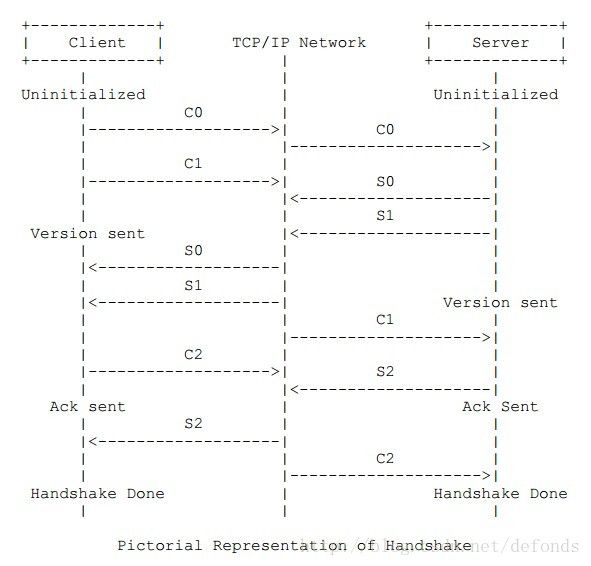
Uninitialized (未初始化):协议的版本号在这个阶段被发送。客户端和服务器都是 uninitialized (未初始化) 状态。之后客户端在数据包 C0 中将协议版本号发出。如果服务器支持这个版本,它将在回应中发送 S0 和 S1。如果不支持呢,服务器会才去适当的行为进行响应。在 RTMP 协议中,这个行为就是终止连接。
Version Sent (版本已发送):在未初始化状态之后,客户端和服务器都进入 Version Sent (版本已发送) 状态。客户端会等待接收数据包 S1 而服务器在等待 C1。一旦拿到期待的包,客户端会发送数据包 C2 而服务器发送数据包 S2。(客户端和服务器各自的)状态随即变为 Ack Sent (确认已发送)。
Ack Sent (确认已发送):客户端和服务器分别等待 S2 和 C2。
Handshake Done (握手结束):客户端和服务器可以开始交换消息了。
5.3 复杂握手(complex handshake)
rtmp 1.0规范中,指定了RTMP的握手协议:- c0/s0:一个字节,说明是明文还是加密。
- c1/s1: 1536字节,4字节时间,4字节0x00,1528字节随机数
- c2/s2: 1536字节,4字节时间1,4字节时间2,1528随机数和s1相同。这个就是srs以及其他开源软件所谓的simple handshake,简单握手,标准握手,FMLE也是使用这个握手协议。
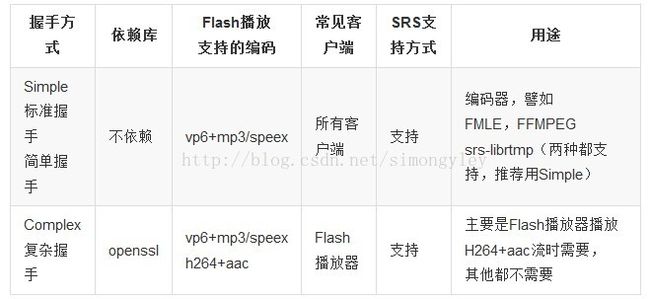
由上表可知,当服务器和客户端的握手是按照rtmp协议进行,是不支持h264/aac的,有数据,就是没有视频和声音。原因是adobe变更了握手的数据结构,标准rtmp协议的握手的包是随机的1536字节(S1S2C1C2),变更后的是需要进行摘要和加密。rtmp协议定义的为simple handshake,变更后加密握手可称为complex handshake。
本文详细分析了rtmpd(ccrtmpserver)中的处理逻辑,以及rtmpdump的处理逻辑,从一个全是魔法数字的世界找到他们的数据结构和算法。
5.3.1. complex handshake C1 S1结构(此处参照了winlin博客的相关文章)
complex handshake将C1S1分为4个部分,它们的顺序(schema)一种可能是:
// c1s1 schema0
time: 4bytes
version: 4bytes
key: 764bytes
digest: 764bytes其中,key和digest可能会交换位置,即schema可能是:
// c1s1 schema1
time: 4bytes
version: 4bytes
digest: 764bytes
key: 764bytes客户端来决定使用哪种schema,服务器端则需要先尝试按照schema0解析,失败则用schema1解析。如下图所示:

无论key和digest位置如何,它们的结构是不变的:
// 764bytes key结构
random-data: (offset)bytes
key-data: 128bytes
random-data: (764-offset-128-4)bytes
offset: 4bytes
// 764bytes digest结构
offset: 4bytes
random-data: (offset)bytes
digest-data: 32bytes
random-data: (764-4-offset-32)bytes备注:发现FMS只认识digest-key结构。
如下图所示:


5.3.2.complex handshake C2 S2结构:
c2 s2主要是用来提供对C1 S1的验证,结构如下:// 1536bytes C2S2结构
random-data: 1504bytes
digest-data: 32bytes
下面介绍C1S1C2S2的生成以及验证算法。
5.3.3.complex handshake C1 S1算法
C1S1中都是包含32字节的digest,而且digest将C1S1分成两部分:// C1S1被digest分成两部分
c1s1-part1: n bytes
digest-data: 32bytes
c1s1-part2: (1536-n-32)bytes如下图所示:
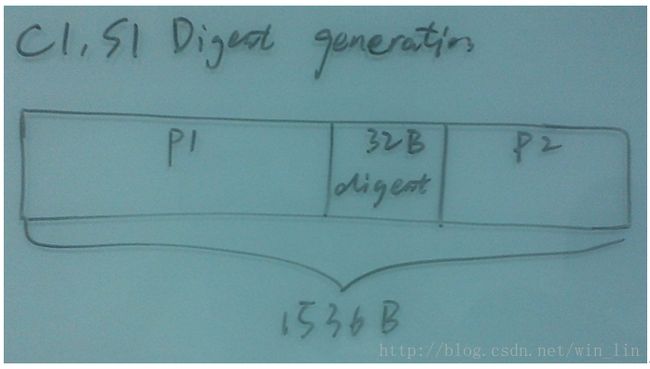
在生成C1时,需要用到c1s1-part1和c1s1-part2这两个部分的字节拼接起来的字节,定义为:
c1s1-joined = bytes_join(c1s1-part1, c1s1-part2)也就是说,把1536字节的c1s1中的32字节的digest拿剪刀剪掉,剩下的头和尾加在一起就是c1s1-joined。用到的两个常量FPKey和FMSKey:
u_int8_t FMSKey[] = {
0x47, 0x65, 0x6e, 0x75, 0x69, 0x6e, 0x65, 0x20,
0x41, 0x64, 0x6f, 0x62, 0x65, 0x20, 0x46, 0x6c,
0x61, 0x73, 0x68, 0x20, 0x4d, 0x65, 0x64, 0x69,
0x61, 0x20, 0x53, 0x65, 0x72, 0x76, 0x65, 0x72,
0x20, 0x30, 0x30, 0x31, // Genuine Adobe Flash Media Server 001
0xf0, 0xee, 0xc2, 0x4a, 0x80, 0x68, 0xbe, 0xe8,
0x2e, 0x00, 0xd0, 0xd1, 0x02, 0x9e, 0x7e, 0x57,
0x6e, 0xec, 0x5d, 0x2d, 0x29, 0x80, 0x6f, 0xab,
0x93, 0xb8, 0xe6, 0x36, 0xcf, 0xeb, 0x31, 0xae
}; // 68
u_int8_t FPKey[] = {
0x47, 0x65, 0x6E, 0x75, 0x69, 0x6E, 0x65, 0x20,
0x41, 0x64, 0x6F, 0x62, 0x65, 0x20, 0x46, 0x6C,
0x61, 0x73, 0x68, 0x20, 0x50, 0x6C, 0x61, 0x79,
0x65, 0x72, 0x20, 0x30, 0x30, 0x31, // Genuine Adobe Flash Player 001
0xF0, 0xEE, 0xC2, 0x4A, 0x80, 0x68, 0xBE, 0xE8,
0x2E, 0x00, 0xD0, 0xD1, 0x02, 0x9E, 0x7E, 0x57,
0x6E, 0xEC, 0x5D, 0x2D, 0x29, 0x80, 0x6F, 0xAB,
0x93, 0xB8, 0xE6, 0x36, 0xCF, 0xEB, 0x31, 0xAE
}; // 62生成C1的算法如下:
calc_c1_digest(c1, schema) {
get c1s1-joined from c1 by specified schema
digest-data = HMACsha256(c1s1-joined, FPKey, 30)
return digest-data;
}
random fill 1536bytes c1 // also fill the c1-128bytes-key
time = time() // c1[0-3]
version = [0x80, 0x00, 0x07, 0x02] // c1[4-7]
schema = choose schema0 or schema1
digest-data = calc_c1_digest(c1, schema)
copy digest-data to c1
/*decode c1 try schema0 then schema1*/
c1-digest-data = get-c1-digest-data(schema0)
if c1-digest-data equals to calc_c1_digest(c1, schema0) {
c1-key-data = get-c1-key-data(schema0)
schema = schema0
} else {
c1-digest-data = get-c1-digest-data(schema1)
if c1-digest-data not equals to calc_c1_digest(c1, schema1) {
switch to simple handshake.
return
}
c1-key-data = get-c1-key-data(schema1)
schema = schema1
}
/*generate s1*/
random fill 1536bytes s1
time = time() // c1[0-3]
version = [0x04, 0x05, 0x00, 0x01] // s1[4-7]
DH_compute_key(key = c1-key-data, pub_key=s1-key-data)
get c1s1-joined by specified schema
s1-digest-data = HMACsha256(c1s1-joined, FMSKey, 36)
copy s1-digest-data and s1-key-data to s1.
5.3.4.complex handshake C2 S2
C2S2的生成算法如下:random fill c2s2 1536 bytes
// client generate C2, or server valid C2
temp-key = HMACsha256(s1-digest, FPKey, 62)
c2-digest-data = HMACsha256(c2-random-data, temp-key, 32)
// server generate S2, or client valid S2
temp-key = HMACsha256(c1-digest, FMSKey, 68)
s2-digest-data = HMACsha256(s2-random-data, temp-key, 32)
5.3.5.解析补充
读rtmpd(ccrtmpserver)代码发现,handshake确实变更了。BTW:rtmpd的代码可读性要强很多,很快就能知道它在做什么;不过,它是部分C++部分C的混合体;譬如,使用了BaseRtmpProtocol和InboundRtmpProtocol这种C++的解决方式;以及在解析complex handshake时对1536字节的包直接操作,offset=buf[772]+buf[773]+buf[774]+buf[775],这个就很难看明白在做什么了,其实1536是由4字节的time+4字节的version+764字节的key+764字节的digest,key的offset在后面,digest的offset在前面,若定义两个结构再让它们自己去解析,就很明白在做什么了。sources\thelib\src\protocols\rtmp\inboundrtmpprotocol.cpp: 51
InboundRTMPProtocol::PerformHandshake
// 没有完成握手。
case RTMP_STATE_NOT_INITIALIZED:
// buffer[1537]
// 第一个字节,即c0,表示握手类型(03是明文,06是加密,其他值非法)
handshakeType = GETIBPOINTER(buffer)[0];
// 删除第一个字节,buffer[1536] 即c1
buffer.Ignore(1);
// 第5-8共4个字节表示FPVersion,这个必须非0,0表示不支持complex handshake。
_currentFPVersion = ENTOHLP(GETIBPOINTER(buffer) + 4);
// 进行明文握手(false表示明文)
PerformHandshake(buffer, false);
InboundRTMPProtocol::PerformHandshake
// 先验证client,即验证c1
// 先尝试scheme0
valid = ValidClientScheme(0);
// 若失败,再尝试scheme1
valid = ValidClientScheme(1)
// 若验证成功
if(valid)
// 复杂的handshake:PerformComplexHandshake,主要流程如下:
S0 = 3或6
随机数初始化S1S2
根据C1的public key生成S1的128byets public key
生成S1的32bytes digest
根据C1和S2生成S2的32bytes digest
else
// rtmp spec 1.0定义的握手方式
PerformSimpleHandshake();
其实到后面看明白了,scheme1和scheme2这两种方式,是包结构的调换。
complex的包结构如下:C1/S1 1536bytes
time: 4bytes 开头是4字节的当前时间。(u_int32_t)time(NULL)
peer_version: 4bytes 为程序版本。C1一般是0x80000702。S1是0x04050001。
764bytes: 可能是KeyBlock或者DigestBlock
764bytes: 可能是KeyBlock或者DigestBlock
其中scheme1就是KeyBlock在前面DigestBlock在后面,而scheme0是DigestBlock在前面KeyBlock在后面。
子结构KeyBlock定义:
760bytes: 包含128bytes的key的数据。
key_offset: 4bytes 最后4字节定义了key的offset(相对于KeyBlock开头而言)
子结构DigestBlock定义:
digest_offset: 4bytes 开头4字节定义了digest的offset(相对于第DigestBlock的第5字节而言,offset=3表示digestBlock[7~38]为digest
760bytes: 包含32bytes的digest的数据。DHWrapper dhWrapper(1024);
dhWrapper.Initialize()
dhWrapper.CreateSharedKey(c1_key, 128)
dhWrapper.CopyPublicKey(s1_key, 128)
S2/C2没有key,只有一个digest,是根据C1/S1算出来的:
先用随机数填充S2
s2data=S2[0-1504]; 前1502字节为随机的数据。
s2digest=S2[1505-1526] 后32bytes为digest。
// 计算s2digest方法如下:
ptemphash[512]: HMACsha256(c1digest, 32, FMSKey, 68, ptemhash)
ps2hash[512]: HMACsha256(s2data, 1504, ptemphash, 32, ps2hash)
将ps2hash[0-31]拷贝到s2的后32bytes。5.3.6.代码实现
/*
The MIT License (MIT)
Copyright (c) 2013 winlin
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
the Software, and to permit persons to whom the Software is furnished to do so,
subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
*/
#ifndef SRS_CORE_COMPLEX_HANDSHKAE_HPP
#define SRS_CORE_COMPLEX_HANDSHKAE_HPP
/*
#include
*/
#include
class SrsSocket;
/**
* rtmp complex handshake,
* @see also crtmp(crtmpserver) or librtmp,
* @see also: http://blog.csdn.net/win_lin/article/details/13006803
* @doc update the README.cmd
*/
class SrsComplexHandshake
{
public:
SrsComplexHandshake();
virtual ~SrsComplexHandshake();
public:
/**
* complex hanshake.
* @_c1, size of c1 must be 1536.
* @remark, user must free the c1.
* @return user must:
* continue connect app if success,
* try simple handshake if error is ERROR_RTMP_TRY_SIMPLE_HS,
* otherwise, disconnect
*/
virtual int handshake(SrsSocket& skt, char* _c1);
};
#endif
/*
The MIT License (MIT)
Copyright (c) 2013 winlin
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
the Software, and to permit persons to whom the Software is furnished to do so,
subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
*/
#include
#include
#include
#include
#include
#include
#include
// 68bytes FMS key which is used to sign the sever packet.
u_int8_t SrsGenuineFMSKey[] = {
0x47, 0x65, 0x6e, 0x75, 0x69, 0x6e, 0x65, 0x20,
0x41, 0x64, 0x6f, 0x62, 0x65, 0x20, 0x46, 0x6c,
0x61, 0x73, 0x68, 0x20, 0x4d, 0x65, 0x64, 0x69,
0x61, 0x20, 0x53, 0x65, 0x72, 0x76, 0x65, 0x72,
0x20, 0x30, 0x30, 0x31, // Genuine Adobe Flash Media Server 001
0xf0, 0xee, 0xc2, 0x4a, 0x80, 0x68, 0xbe, 0xe8,
0x2e, 0x00, 0xd0, 0xd1, 0x02, 0x9e, 0x7e, 0x57,
0x6e, 0xec, 0x5d, 0x2d, 0x29, 0x80, 0x6f, 0xab,
0x93, 0xb8, 0xe6, 0x36, 0xcf, 0xeb, 0x31, 0xae
}; // 68
// 62bytes FP key which is used to sign the client packet.
u_int8_t SrsGenuineFPKey[] = {
0x47, 0x65, 0x6E, 0x75, 0x69, 0x6E, 0x65, 0x20,
0x41, 0x64, 0x6F, 0x62, 0x65, 0x20, 0x46, 0x6C,
0x61, 0x73, 0x68, 0x20, 0x50, 0x6C, 0x61, 0x79,
0x65, 0x72, 0x20, 0x30, 0x30, 0x31, // Genuine Adobe Flash Player 001
0xF0, 0xEE, 0xC2, 0x4A, 0x80, 0x68, 0xBE, 0xE8,
0x2E, 0x00, 0xD0, 0xD1, 0x02, 0x9E, 0x7E, 0x57,
0x6E, 0xEC, 0x5D, 0x2D, 0x29, 0x80, 0x6F, 0xAB,
0x93, 0xB8, 0xE6, 0x36, 0xCF, 0xEB, 0x31, 0xAE
}; // 62
#include
#include
int openssl_HMACsha256(const void* data, int data_size, const void* key, int key_size, void* digest) {
HMAC_CTX ctx;
HMAC_CTX_init(&ctx);
HMAC_Init_ex(&ctx, (unsigned char*) key, key_size, EVP_sha256(), NULL);
HMAC_Update(&ctx, (unsigned char *) data, data_size);
unsigned int digest_size;
HMAC_Final(&ctx, (unsigned char *) digest, &digest_size);
HMAC_CTX_cleanup(&ctx);
if (digest_size != 32) {
return ERROR_OpenSslSha256DigestSize;
}
return ERROR_SUCCESS;
}
#include
#define RFC2409_PRIME_1024 \
"FFFFFFFFFFFFFFFFC90FDAA22168C234C4C6628B80DC1CD1" \
"29024E088A67CC74020BBEA63B139B22514A08798E3404DD" \
"EF9519B3CD3A431B302B0A6DF25F14374FE1356D6D51C245" \
"E485B576625E7EC6F44C42E9A637ED6B0BFF5CB6F406B7ED" \
"EE386BFB5A899FA5AE9F24117C4B1FE649286651ECE65381" \
"FFFFFFFFFFFFFFFF"
int __openssl_generate_key(
u_int8_t*& _private_key, u_int8_t*& _public_key, int32_t& size,
DH*& pdh, int32_t& bits_count, u_int8_t*& shared_key, int32_t& shared_key_length, BIGNUM*& peer_public_key
){
int ret = ERROR_SUCCESS;
//1. Create the DH
if ((pdh = DH_new()) == NULL) {
ret = ERROR_OpenSslCreateDH;
return ret;
}
//2. Create his internal p and g
if ((pdh->p = BN_new()) == NULL) {
ret = ERROR_OpenSslCreateP;
return ret;
}
if ((pdh->g = BN_new()) == NULL) {
ret = ERROR_OpenSslCreateG;
return ret;
}
//3. initialize p, g and key length
if (BN_hex2bn(&pdh->p, RFC2409_PRIME_1024) == 0) {
ret = ERROR_OpenSslParseP1024;
return ret;
}
if (BN_set_word(pdh->g, 2) != 1) {
ret = ERROR_OpenSslSetG;
return ret;
}
//4. Set the key length
pdh->length = bits_count;
//5. Generate private and public key
if (DH_generate_key(pdh) != 1) {
ret = ERROR_OpenSslGenerateDHKeys;
return ret;
}
// CreateSharedKey
if (pdh == NULL) {
ret = ERROR_OpenSslGenerateDHKeys;
return ret;
}
if (shared_key_length != 0 || shared_key != NULL) {
ret = ERROR_OpenSslShareKeyComputed;
return ret;
}
shared_key_length = DH_size(pdh);
if (shared_key_length <= 0 || shared_key_length > 1024) {
ret = ERROR_OpenSslGetSharedKeySize;
return ret;
}
shared_key = new u_int8_t[shared_key_length];
memset(shared_key, 0, shared_key_length);
peer_public_key = BN_bin2bn(_private_key, size, 0);
if (peer_public_key == NULL) {
ret = ERROR_OpenSslGetPeerPublicKey;
return ret;
}
if (DH_compute_key(shared_key, peer_public_key, pdh) == -1) {
ret = ERROR_OpenSslComputeSharedKey;
return ret;
}
// CopyPublicKey
if (pdh == NULL) {
ret = ERROR_OpenSslComputeSharedKey;
return ret;
}
int32_t keySize = BN_num_bytes(pdh->pub_key);
if ((keySize <= 0) || (size <= 0) || (keySize > size)) {
//("CopyPublicKey failed due to either invalid DH state or invalid call"); return ret;
ret = ERROR_OpenSslInvalidDHState;
return ret;
}
if (BN_bn2bin(pdh->pub_key, _public_key) != keySize) {
//("Unable to copy key"); return ret;
ret = ERROR_OpenSslCopyKey;
return ret;
}
return ret;
}
int openssl_generate_key(char* _private_key, char* _public_key, int32_t size)
{
int ret = ERROR_SUCCESS;
// Initialize
DH* pdh = NULL;
int32_t bits_count = 1024;
u_int8_t* shared_key = NULL;
int32_t shared_key_length = 0;
BIGNUM* peer_public_key = NULL;
ret = __openssl_generate_key(
(u_int8_t*&)_private_key, (u_int8_t*&)_public_key, size,
pdh, bits_count, shared_key, shared_key_length, peer_public_key
);
if (pdh != NULL) {
if (pdh->p != NULL) {
BN_free(pdh->p);
pdh->p = NULL;
}
if (pdh->g != NULL) {
BN_free(pdh->g);
pdh->g = NULL;
}
DH_free(pdh);
pdh = NULL;
}
if (shared_key != NULL) {
delete[] shared_key;
shared_key = NULL;
}
if (peer_public_key != NULL) {
BN_free(peer_public_key);
peer_public_key = NULL;
}
return ret;
}
// the digest key generate size.
#define OpensslHashSize 512
/**
* 764bytes key结构
* random-data: (offset)bytes
* key-data: 128bytes
* random-data: (764-offset-128-4)bytes
* offset: 4bytes
*/
struct key_block
{
// (offset)bytes
char* random0;
int random0_size;
// 128bytes
char key[128];
// (764-offset-128-4)bytes
char* random1;
int random1_size;
// 4bytes
int32_t offset;
};
// calc the offset of key,
// the key->offset cannot be used as the offset of key.
int srs_key_block_get_offset(key_block* key)
{
int max_offset_size = 764 - 128 - 4;
int offset = 0;
u_int8_t* pp = (u_int8_t*)&key->offset;
offset += *pp++;
offset += *pp++;
offset += *pp++;
offset += *pp++;
return offset % max_offset_size;
}
// create new key block data.
// if created, user must free it by srs_key_block_free
void srs_key_block_init(key_block* key)
{
key->offset = (int32_t)rand();
key->random0 = NULL;
key->random1 = NULL;
int offset = srs_key_block_get_offset(key);
srs_assert(offset >= 0);
key->random0_size = offset;
if (key->random0_size > 0) {
key->random0 = new char[key->random0_size];
for (int i = 0; i < key->random0_size; i++) {
*(key->random0 + i) = rand() % 256;
}
}
for (int i = 0; i < (int)sizeof(key->key); i++) {
*(key->key + i) = rand() % 256;
}
key->random1_size = 764 - offset - 128 - 4;
if (key->random1_size > 0) {
key->random1 = new char[key->random1_size];
for (int i = 0; i < key->random1_size; i++) {
*(key->random1 + i) = rand() % 256;
}
}
}
// parse key block from c1s1.
// if created, user must free it by srs_key_block_free
// @c1s1_key_bytes the key start bytes, maybe c1s1 or c1s1+764
int srs_key_block_parse(key_block* key, char* c1s1_key_bytes)
{
int ret = ERROR_SUCCESS;
char* pp = c1s1_key_bytes + 764;
pp -= sizeof(int32_t);
key->offset = *(int32_t*)pp;
key->random0 = NULL;
key->random1 = NULL;
int offset = srs_key_block_get_offset(key);
srs_assert(offset >= 0);
pp = c1s1_key_bytes;
key->random0_size = offset;
if (key->random0_size > 0) {
key->random0 = new char[key->random0_size];
memcpy(key->random0, pp, key->random0_size);
}
pp += key->random0_size;
memcpy(key->key, pp, sizeof(key->key));
pp += sizeof(key->key);
key->random1_size = 764 - offset - 128 - 4;
if (key->random1_size > 0) {
key->random1 = new char[key->random1_size];
memcpy(key->random1, pp, key->random1_size);
}
return ret;
}
// free the block data create by
// srs_key_block_init or srs_key_block_parse
void srs_key_block_free(key_block* key)
{
if (key->random0) {
srs_freepa(key->random0);
}
if (key->random1) {
srs_freepa(key->random1);
}
}
/**
* 764bytes digest结构
* offset: 4bytes
* random-data: (offset)bytes
* digest-data: 32bytes
* random-data: (764-4-offset-32)bytes
*/
struct digest_block
{
// 4bytes
int32_t offset;
// (offset)bytes
char* random0;
int random0_size;
// 32bytes
char digest[32];
// (764-4-offset-32)bytes
char* random1;
int random1_size;
};
// calc the offset of digest,
// the key->offset cannot be used as the offset of digest.
int srs_digest_block_get_offset(digest_block* digest)
{
int max_offset_size = 764 - 32 - 4;
int offset = 0;
u_int8_t* pp = (u_int8_t*)&digest->offset;
offset += *pp++;
offset += *pp++;
offset += *pp++;
offset += *pp++;
return offset % max_offset_size;
}
// create new digest block data.
// if created, user must free it by srs_digest_block_free
void srs_digest_block_init(digest_block* digest)
{
digest->offset = (int32_t)rand();
digest->random0 = NULL;
digest->random1 = NULL;
int offset = srs_digest_block_get_offset(digest);
srs_assert(offset >= 0);
digest->random0_size = offset;
if (digest->random0_size > 0) {
digest->random0 = new char[digest->random0_size];
for (int i = 0; i < digest->random0_size; i++) {
*(digest->random0 + i) = rand() % 256;
}
}
for (int i = 0; i < (int)sizeof(digest->digest); i++) {
*(digest->digest + i) = rand() % 256;
}
digest->random1_size = 764 - 4 - offset - 32;
if (digest->random1_size > 0) {
digest->random1 = new char[digest->random1_size];
for (int i = 0; i < digest->random1_size; i++) {
*(digest->random1 + i) = rand() % 256;
}
}
}
// parse digest block from c1s1.
// if created, user must free it by srs_digest_block_free
// @c1s1_digest_bytes the digest start bytes, maybe c1s1 or c1s1+764
int srs_digest_block_parse(digest_block* digest, char* c1s1_digest_bytes)
{
int ret = ERROR_SUCCESS;
char* pp = c1s1_digest_bytes;
digest->offset = *(int32_t*)pp;
pp += sizeof(int32_t);
digest->random0 = NULL;
digest->random1 = NULL;
int offset = srs_digest_block_get_offset(digest);
srs_assert(offset >= 0);
digest->random0_size = offset;
if (digest->random0_size > 0) {
digest->random0 = new char[digest->random0_size];
memcpy(digest->random0, pp, digest->random0_size);
}
pp += digest->random0_size;
memcpy(digest->digest, pp, sizeof(digest->digest));
pp += sizeof(digest->digest);
digest->random1_size = 764 - 4 - offset - 32;
if (digest->random1_size > 0) {
digest->random1 = new char[digest->random1_size];
memcpy(digest->random1, pp, digest->random1_size);
}
return ret;
}
// free the block data create by
// srs_digest_block_init or srs_digest_block_parse
void srs_digest_block_free(digest_block* digest)
{
if (digest->random0) {
srs_freepa(digest->random0);
}
if (digest->random1) {
srs_freepa(digest->random1);
}
}
/**
* the schema type.
*/
enum srs_schema_type {
srs_schema0 = 0, // key-digest sequence
srs_schema1 = 1, // digest-key sequence
srs_schema_invalid = 2,
};
void __srs_time_copy_to(char*& pp, int32_t time)
{
// 4bytes time
*(int32_t*)pp = time;
pp += 4;
}
void __srs_version_copy_to(char*& pp, int32_t version)
{
// 4bytes version
*(int32_t*)pp = version;
pp += 4;
}
void __srs_key_copy_to(char*& pp, key_block* key)
{
// 764bytes key block
if (key->random0_size > 0) {
memcpy(pp, key->random0, key->random0_size);
}
pp += key->random0_size;
memcpy(pp, key->key, sizeof(key->key));
pp += sizeof(key->key);
if (key->random1_size > 0) {
memcpy(pp, key->random1, key->random1_size);
}
pp += key->random1_size;
*(int32_t*)pp = key->offset;
pp += 4;
}
void __srs_digest_copy_to(char*& pp, digest_block* digest, bool with_digest)
{
// 732bytes digest block without the 32bytes digest-data
// nbytes digest block part1
*(int32_t*)pp = digest->offset;
pp += 4;
if (digest->random0_size > 0) {
memcpy(pp, digest->random0, digest->random0_size);
}
pp += digest->random0_size;
// digest
if (with_digest) {
memcpy(pp, digest->digest, 32);
pp += 32;
}
// nbytes digest block part2
if (digest->random1_size > 0) {
memcpy(pp, digest->random1, digest->random1_size);
}
pp += digest->random1_size;
}
/**
* copy whole c1s1 to bytes.
*/
void srs_schema0_copy_to(char* bytes, bool with_digest,
int32_t time, int32_t version, key_block* key, digest_block* digest)
{
char* pp = bytes;
__srs_time_copy_to(pp, time);
__srs_version_copy_to(pp, version);
__srs_key_copy_to(pp, key);
__srs_digest_copy_to(pp, digest, with_digest);
if (with_digest) {
srs_assert(pp - bytes == 1536);
} else {
srs_assert(pp - bytes == 1536 - 32);
}
}
void srs_schema1_copy_to(char* bytes, bool with_digest,
int32_t time, int32_t version, digest_block* digest, key_block* key)
{
char* pp = bytes;
__srs_time_copy_to(pp, time);
__srs_version_copy_to(pp, version);
__srs_digest_copy_to(pp, digest, with_digest);
__srs_key_copy_to(pp, key);
if (with_digest) {
srs_assert(pp - bytes == 1536);
} else {
srs_assert(pp - bytes == 1536 - 32);
}
}
/**
* c1s1 is splited by digest:
* c1s1-part1: n bytes (time, version, key and digest-part1).
* digest-data: 32bytes
* c1s1-part2: (1536-n-32)bytes (digest-part2)
*/
char* srs_bytes_join_schema0(int32_t time, int32_t version, key_block* key, digest_block* digest)
{
char* bytes = new char[1536 -32];
srs_schema0_copy_to(bytes, false, time, version, key, digest);
return bytes;
}
/**
* c1s1 is splited by digest:
* c1s1-part1: n bytes (time, version and digest-part1).
* digest-data: 32bytes
* c1s1-part2: (1536-n-32)bytes (digest-part2 and key)
*/
char* srs_bytes_join_schema1(int32_t time, int32_t version, digest_block* digest, key_block* key)
{
char* bytes = new char[1536 -32];
srs_schema1_copy_to(bytes, false, time, version, digest, key);
return bytes;
}
/**
* compare the memory in bytes.
*/
bool srs_bytes_equals(void* pa, void* pb, int size){
u_int8_t* a = (u_int8_t*)pa;
u_int8_t* b = (u_int8_t*)pb;
for(int i = 0; i < size; i++){
if(a[i] != b[i]){
return false;
}
}
return true;
}
/**
* c1s1 schema0
* time: 4bytes
* version: 4bytes
* key: 764bytes
* digest: 764bytes
* c1s1 schema1
* time: 4bytes
* version: 4bytes
* digest: 764bytes
* key: 764bytes
*/
struct c1s1
{
union block {
key_block key;
digest_block digest;
};
// 4bytes
int32_t time;
// 4bytes
int32_t version;
// 764bytes
// if schema0, use key
// if schema1, use digest
block block0;
// 764bytes
// if schema0, use digest
// if schema1, use key
block block1;
// the logic schema
srs_schema_type schema;
c1s1();
virtual ~c1s1();
/**
* get the digest key.
*/
virtual char* get_digest();
/**
* copy to bytes.
*/
virtual void dump(char* _c1s1);
/**
* client: create and sign c1 by schema.
* sign the c1, generate the digest.
* calc_c1_digest(c1, schema) {
* get c1s1-joined from c1 by specified schema
* digest-data = HMACsha256(c1s1-joined, FPKey, 30)
* return digest-data;
* }
* random fill 1536bytes c1 // also fill the c1-128bytes-key
* time = time() // c1[0-3]
* version = [0x80, 0x00, 0x07, 0x02] // c1[4-7]
* schema = choose schema0 or schema1
* digest-data = calc_c1_digest(c1, schema)
* copy digest-data to c1
*/
virtual int c1_create(srs_schema_type _schema);
/**
* server: parse the c1s1, discovery the key and digest by schema.
* use the c1_validate_digest() to valid the digest of c1.
*/
virtual int c1_parse(char* _c1s1, srs_schema_type _schema);
/**
* server: validate the parsed schema and c1s1
*/
virtual int c1_validate_digest(bool& is_valid);
/**
* server: create and sign the s1 from c1.
*/
virtual int s1_create(c1s1* c1);
private:
virtual int calc_s1_digest(char*& digest);
virtual int calc_c1_digest(char*& digest);
virtual void destroy_blocks();
};
/**
* the c2s2 complex handshake structure.
* random-data: 1504bytes
* digest-data: 32bytes
*/
struct c2s2
{
char random[1504];
char digest[32];
c2s2();
virtual ~c2s2();
/**
* copy to bytes.
*/
virtual void dump(char* _c2s2);
/**
* create c2.
* random fill c2s2 1536 bytes
*
* // client generate C2, or server valid C2
* temp-key = HMACsha256(s1-digest, FPKey, 62)
* c2-digest-data = HMACsha256(c2-random-data, temp-key, 32)
*/
virtual int c2_create(c1s1* s1);
/**
* create s2.
* random fill c2s2 1536 bytes
*
* // server generate S2, or client valid S2
* temp-key = HMACsha256(c1-digest, FMSKey, 68)
* s2-digest-data = HMACsha256(s2-random-data, temp-key, 32)
*/
virtual int s2_create(c1s1* c1);
};
c2s2::c2s2()
{
for (int i = 0; i < 1504; i++) {
*(random + i) = rand();
}
for (int i = 0; i < 32; i++) {
*(digest + i) = rand();
}
}
c2s2::~c2s2()
{
}
void c2s2::dump(char* _c2s2)
{
memcpy(_c2s2, random, 1504);
memcpy(_c2s2 + 1504, digest, 32);
}
int c2s2::c2_create(c1s1* s1)
{
int ret = ERROR_SUCCESS;
char temp_key[OpensslHashSize];
if ((ret = openssl_HMACsha256(s1->get_digest(), 32, SrsGenuineFPKey, 62, temp_key)) != ERROR_SUCCESS) {
srs_error("create c2 temp key failed. ret=%d", ret);
return ret;
}
srs_verbose("generate c2 temp key success.");
char _digest[OpensslHashSize];
if ((ret = openssl_HMACsha256(random, 1504, temp_key, 32, _digest)) != ERROR_SUCCESS) {
srs_error("create c2 digest failed. ret=%d", ret);
return ret;
}
srs_verbose("generate c2 digest success.");
memcpy(digest, _digest, 32);
return ret;
}
int c2s2::s2_create(c1s1* c1)
{
int ret = ERROR_SUCCESS;
char temp_key[OpensslHashSize];
if ((ret = openssl_HMACsha256(c1->get_digest(), 32, SrsGenuineFMSKey, 68, temp_key)) != ERROR_SUCCESS) {
srs_error("create s2 temp key failed. ret=%d", ret);
return ret;
}
srs_verbose("generate s2 temp key success.");
char _digest[OpensslHashSize];
if ((ret = openssl_HMACsha256(random, 1504, temp_key, 32, _digest)) != ERROR_SUCCESS) {
srs_error("create s2 digest failed. ret=%d", ret);
return ret;
}
srs_verbose("generate s2 digest success.");
memcpy(digest, _digest, 32);
return ret;
}
c1s1::c1s1()
{
schema = srs_schema_invalid;
}
c1s1::~c1s1()
{
destroy_blocks();
}
char* c1s1::get_digest()
{
srs_assert(schema != srs_schema_invalid);
if (schema == srs_schema0) {
return block1.digest.digest;
} else {
return block0.digest.digest;
}
}
void c1s1::dump(char* _c1s1)
{
srs_assert(schema != srs_schema_invalid);
if (schema == srs_schema0) {
srs_schema0_copy_to(_c1s1, true, time, version, &block0.key, &block1.digest);
} else {
srs_schema1_copy_to(_c1s1, true, time, version, &block0.digest, &block1.key);
}
}
int c1s1::c1_create(srs_schema_type _schema)
{
int ret = ERROR_SUCCESS;
if (_schema == srs_schema_invalid) {
ret = ERROR_RTMP_CH_SCHEMA;
srs_error("create c1 failed. invalid schema=%d, ret=%d", _schema, ret);
return ret;
}
destroy_blocks();
time = ::time(NULL);
version = 0x02070080; // client c1 version
if (_schema == srs_schema0) {
srs_key_block_init(&block0.key);
srs_digest_block_init(&block1.digest);
} else {
srs_digest_block_init(&block0.digest);
srs_key_block_init(&block1.key);
}
schema = _schema;
char* digest = NULL;
if ((ret = calc_c1_digest(digest)) != ERROR_SUCCESS) {
srs_error("sign c1 error, failed to calc digest. ret=%d", ret);
return ret;
}
srs_assert(digest != NULL);
SrsAutoFree(char, digest, true);
if (schema == srs_schema0) {
memcpy(block1.digest.digest, digest, 32);
} else {
memcpy(block0.digest.digest, digest, 32);
}
return ret;
}
int c1s1::c1_parse(char* _c1s1, srs_schema_type _schema)
{
int ret = ERROR_SUCCESS;
if (_schema == srs_schema_invalid) {
ret = ERROR_RTMP_CH_SCHEMA;
srs_error("parse c1 failed. invalid schema=%d, ret=%d", _schema, ret);
return ret;
}
destroy_blocks();
time = *(int32_t*)_c1s1;
version = *(int32_t*)(_c1s1 + 4); // client c1 version
if (_schema == srs_schema0) {
if ((ret = srs_key_block_parse(&block0.key, _c1s1 + 8)) != ERROR_SUCCESS) {
srs_error("parse the c1 key failed. ret=%d", ret);
return ret;
}
if ((ret = srs_digest_block_parse(&block1.digest, _c1s1 + 8 + 764)) != ERROR_SUCCESS) {
srs_error("parse the c1 digest failed. ret=%d", ret);
return ret;
}
srs_verbose("parse c1 key-digest success");
} else if (_schema == srs_schema1) {
if ((ret = srs_digest_block_parse(&block0.digest, _c1s1 + 8)) != ERROR_SUCCESS) {
srs_error("parse the c1 key failed. ret=%d", ret);
return ret;
}
if ((ret = srs_key_block_parse(&block1.key, _c1s1 + 8 + 764)) != ERROR_SUCCESS) {
srs_error("parse the c1 digest failed. ret=%d", ret);
return ret;
}
srs_verbose("parse c1 digest-key success");
} else {
ret = ERROR_RTMP_CH_SCHEMA;
srs_error("parse c1 failed. invalid schema=%d, ret=%d", _schema, ret);
return ret;
}
schema = _schema;
return ret;
}
int c1s1::c1_validate_digest(bool& is_valid)
{
int ret = ERROR_SUCCESS;
char* c1_digest = NULL;
if ((ret = calc_c1_digest(c1_digest)) != ERROR_SUCCESS) {
srs_error("validate c1 error, failed to calc digest. ret=%d", ret);
return ret;
}
srs_assert(c1_digest != NULL);
SrsAutoFree(char, c1_digest, true);
if (schema == srs_schema0) {
is_valid = srs_bytes_equals(block1.digest.digest, c1_digest, 32);
} else {
is_valid = srs_bytes_equals(block0.digest.digest, c1_digest, 32);
}
return ret;
}
int c1s1::s1_create(c1s1* c1)
{
int ret = ERROR_SUCCESS;
if (c1->schema == srs_schema_invalid) {
ret = ERROR_RTMP_CH_SCHEMA;
srs_error("create s1 failed. invalid schema=%d, ret=%d", c1->schema, ret);
return ret;
}
destroy_blocks();
schema = c1->schema;
time = ::time(NULL);
version = 0x01000504; // server s1 version
if (schema == srs_schema0) {
srs_key_block_init(&block0.key);
srs_digest_block_init(&block1.digest);
} else {
srs_digest_block_init(&block0.digest);
srs_key_block_init(&block1.key);
}
if (schema == srs_schema0) {
if ((ret = openssl_generate_key(c1->block0.key.key, block0.key.key, 128)) != ERROR_SUCCESS) {
srs_error("calc s1 key failed. ret=%d", ret);
return ret;
}
} else {
if ((ret = openssl_generate_key(c1->block1.key.key, block1.key.key, 128)) != ERROR_SUCCESS) {
srs_error("calc s1 key failed. ret=%d", ret);
return ret;
}
}
srs_verbose("calc s1 key success.");
char* s1_digest = NULL;
if ((ret = calc_s1_digest(s1_digest)) != ERROR_SUCCESS) {
srs_error("calc s1 digest failed. ret=%d", ret);
return ret;
}
srs_verbose("calc s1 digest success.");
srs_assert(s1_digest != NULL);
SrsAutoFree(char, s1_digest, true);
if (schema == srs_schema0) {
memcpy(block1.digest.digest, s1_digest, 32);
} else {
memcpy(block0.digest.digest, s1_digest, 32);
}
srs_verbose("copy s1 key success.");
return ret;
}
int c1s1::calc_s1_digest(char*& digest)
{
int ret = ERROR_SUCCESS;
srs_assert(schema == srs_schema0 || schema == srs_schema1);
char* c1s1_joined_bytes = NULL;
if (schema == srs_schema0) {
c1s1_joined_bytes = srs_bytes_join_schema0(time, version, &block0.key, &block1.digest);
} else {
c1s1_joined_bytes = srs_bytes_join_schema1(time, version, &block0.digest, &block1.key);
}
srs_assert(c1s1_joined_bytes != NULL);
SrsAutoFree(char, c1s1_joined_bytes, true);
digest = new char[OpensslHashSize];
if ((ret = openssl_HMACsha256(c1s1_joined_bytes, 1536 - 32, SrsGenuineFMSKey, 36, digest)) != ERROR_SUCCESS) {
srs_error("calc digest for s1 failed. ret=%d", ret);
return ret;
}
srs_verbose("digest calculated for s1");
return ret;
}
int c1s1::calc_c1_digest(char*& digest)
{
int ret = ERROR_SUCCESS;
srs_assert(schema == srs_schema0 || schema == srs_schema1);
char* c1s1_joined_bytes = NULL;
if (schema == srs_schema0) {
c1s1_joined_bytes = srs_bytes_join_schema0(time, version, &block0.key, &block1.digest);
} else {
c1s1_joined_bytes = srs_bytes_join_schema1(time, version, &block0.digest, &block1.key);
}
srs_assert(c1s1_joined_bytes != NULL);
SrsAutoFree(char, c1s1_joined_bytes, true);
digest = new char[OpensslHashSize];
if ((ret = openssl_HMACsha256(c1s1_joined_bytes, 1536 - 32, SrsGenuineFPKey, 30, digest)) != ERROR_SUCCESS) {
srs_error("calc digest for c1 failed. ret=%d", ret);
return ret;
}
srs_verbose("digest calculated for c1");
return ret;
}
void c1s1::destroy_blocks()
{
if (schema == srs_schema_invalid) {
return;
}
if (schema == srs_schema0) {
srs_key_block_free(&block0.key);
srs_digest_block_free(&block1.digest);
} else {
srs_digest_block_free(&block0.digest);
srs_key_block_free(&block1.key);
}
}
SrsComplexHandshake::SrsComplexHandshake()
{
}
SrsComplexHandshake::~SrsComplexHandshake()
{
}
int SrsComplexHandshake::handshake(SrsSocket& skt, char* _c1)
{
int ret = ERROR_SUCCESS;
ssize_t nsize;
static bool _random_initialized = false;
if (!_random_initialized) {
srand(0);
_random_initialized = true;
srs_trace("srand initialized the random.");
}
// decode c1
c1s1 c1;
// try schema0.
if ((ret = c1.c1_parse(_c1, srs_schema0)) != ERROR_SUCCESS) {
srs_error("parse c1 schema%d error. ret=%d", srs_schema0, ret);
return ret;
}
// try schema1
bool is_valid = false;
if ((ret = c1.c1_validate_digest(is_valid)) != ERROR_SUCCESS || !is_valid) {
if ((ret = c1.c1_parse(_c1, srs_schema1)) != ERROR_SUCCESS) {
srs_error("parse c1 schema%d error. ret=%d", srs_schema1, ret);
return ret;
}
if ((ret = c1.c1_validate_digest(is_valid)) != ERROR_SUCCESS || !is_valid) {
ret = ERROR_RTMP_TRY_SIMPLE_HS;
srs_info("all schema valid failed, try simple handshake. ret=%d", ret);
return ret;
}
}
srs_verbose("decode c1 success.");
// encode s1
c1s1 s1;
if ((ret = s1.s1_create(&c1)) != ERROR_SUCCESS) {
srs_error("create s1 from c1 failed. ret=%d", ret);
return ret;
}
srs_verbose("create s1 from c1 success.");
c2s2 s2;
if ((ret = s2.s2_create(&c1)) != ERROR_SUCCESS) {
srs_error("create s2 from c1 failed. ret=%d", ret);
return ret;
}
srs_verbose("create s2 from c1 success.");
// sendout s0s1s2
char* s0s1s2 = new char[3073];
SrsAutoFree(char, s0s1s2, true);
// plain text required.
s0s1s2[0] = 0x03;
s1.dump(s0s1s2 + 1);
s2.dump(s0s1s2 + 1537);
if ((ret = skt.write(s0s1s2, 3073, &nsize)) != ERROR_SUCCESS) {
srs_warn("complex handshake send s0s1s2 failed. ret=%d", ret);
return ret;
}
srs_verbose("complex handshake send s0s1s2 success.");
// recv c2
char* c2 = new char[1536];
SrsAutoFree(char, c2, true);
if ((ret = skt.read_fully(c2, 1536, &nsize)) != ERROR_SUCCESS) {
srs_warn("complex handshake read c2 failed. ret=%d", ret);
return ret;
}
srs_verbose("complex handshake read c2 success.");
return ret;
}
5.4. 分块
握手之后,连接开始对一个或多个块流进行合并。创建的每个块都有一个唯一 ID 对其进行关联,这个 ID 叫做 chunk stream ID (块流 ID),即csid。这些块通过网络进行传输。传递时,每个块必须被完全发送才可以发送下一块。在接收端,这些块被根据块流 ID 被组装成消息。分块允许上层协议将大的消息分解为更小的消息,例如,防止体积大的但优先级小的消息 (比如视频) 阻碍体积较小但优先级高的消息 (比如音频或者控制命令)。
分块也让我们能够使用较小开销发送小消息,因为块头包含包含在消息内部的信息压缩提示。
块的大小是可以配置的。它可以使用一个设置块大小的控制消息进行设置 (参考 5.4.1)。更大的块大小可以降低 CPU 开销,但在低带宽连接时因为它的大量的写入也会延迟其他内容的传递。更小的块不利于高比特率的流化。所以块的大小设置取决于具体情况。
5.4.1. 块格式
每个块包含一个头和数据体。块头包含三个部分:
Message Header (消息头,0,3,7,或者 11 个字节):这一字段对正在发送的消息 (不管是整个消息,还是只是一小部分) 的信息进行编码。这一字段的长度可以使用块头中定义的块类型进行决定。
Extended Timestamp (扩展 timestamp,0 或 4 字节):这一字段是否出现取决于块消息头中的 timestamp 或者 timestamp delta 字段。更多信息参考 5.4.1.3 节。
Chunk Data (可变的大小):当前块的有效负载,大小由配置决定。
5.4.1.1. 块基本头
块基本头对块流 ID (chunk stream id=csid)和块类型 (由下图中的 fmt 字段表示) 进行编码。块基本头字段可能会有 1,2 或者 3 个字节,取决于块流 ID。一个 (RTMP) 实现应该使用能够容纳这个 ID 的最小的容量进行表示。
RTMP 协议最多支持 65597 个流,流 ID 范围 3 - 65599。ID 0、1、2 被保留。0 值表示二字节形式,并且 ID 范围 64 - 319 (第二个字节 + 64)。1 值表示三字节形式,并且 ID 范围为 64 - 65599 ((第三个字节) * 256 + 第二个字节 + 64)。3 - 63 范围内的值表示整个流 ID。带有 2 值的块流 ID 被保留,用于下层协议控制消息和命令。
块基本头中的 0 - 5 位 (最低有效) 代表块流 ID。
块流 ID 2 - 63 可以编进这一字段的一字节版本中。



例如:如果csid=288=224+64,那么应该表示成fmt00000011100000(2-byte)或者fmt0000010000000011100000(3-byte)。
csid (六位):这一字段包含有块流 ID,值的范围是 2 - 63。fmt后面紧跟着的6位的值, 0 和 1 用于指示这一字段是 2- 或者 3- 字节版本。
fmt (两个字节):这一字段指示 'chunk message header' 使用的四种格式之一。每种块类型的 'chunk message header' 会在下一小节解释。csid - 64 (8 或者 16 位):这一字段包含了块流 ID 减掉 64 后的值块流 ID,即csid - 64为块流 ID在字节中的表现形式。
块流 ID 64 - 319 可以使用 2-byte 或者 3-byte 的形式在头中表示,块流 ID320-65599只能使用3-byte的形式表示。
5.4.1.2. 块消息头(fmt的值)
块消息头又四种不同的格式,由块基本头中的 "fmt" 字段进行选择。一个 (RTMP) 实现应该为每个块消息头使用最紧凑的表示。
5.4.1.2.1. 类型 0
类型 0 块头的长度是 11 个字节。即AMF0包头为11字节。这一类型必须用在块流的起始位置,和流 timestamp 重来的时候 (比如,重置)。
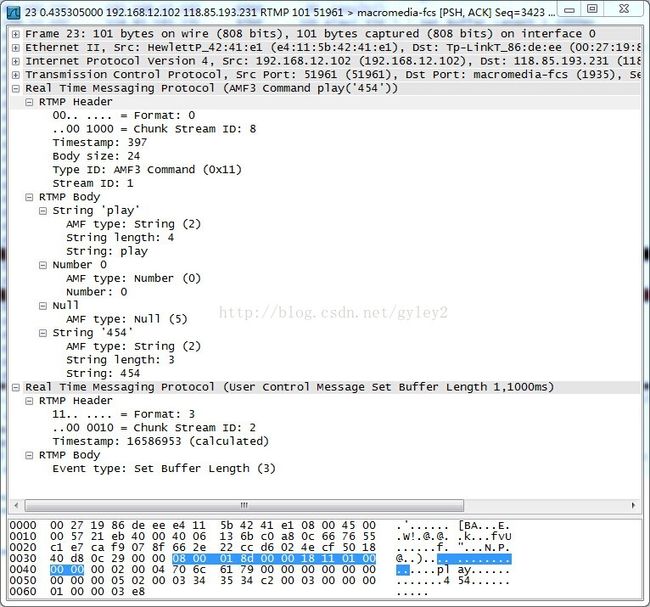
图例1:符合AMF0类型的协议控制包(play&set buffer length)
例如图例1,是一个fmt=0的rtmp的协议控制包(play&set buffer length),csid=8。图中选中字段为包含消息流ID一字节的AMF0包头(12字节,去掉第一个字节的0x08,即为AMF0的11字节包头)。其中timestamp(3个字节,00 01 8d) 为397,message length(body size字段,3个字节,00 00 18)为24.type id(stream id,1个字节)代表body的帧类型为0x11(AMF3 command类型,1字节 0x11),代表是指令帧。msg stream id为1(四个字节,01 00 00 00).

5.4.1.2.2. 类型 1
类型 1 块头长为 7 个字节。即AMF1包头为7字节。不包含消息流 ID;这一块使用前一块一样的流 ID。可变长度消息的流 (例如,一些视频格式) 应该在第一块之后使用这一格式表示之后的每个新消息。
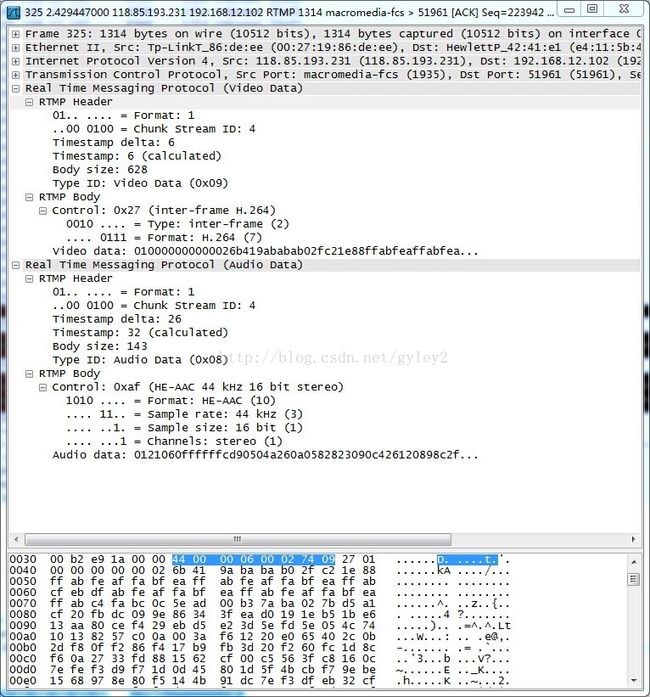
图例2:符合AMF1类型的视频包
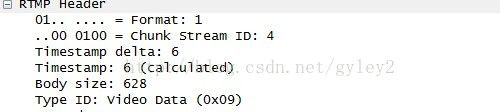
例如图例2,是一个fmt=1的rtmp的视频包。csid=4,图中选中字段为包含消息流ID一字节的AMF1包头(8字节,去掉第一个字节的0x44,即为AMF1的包头)。其中timestamp delta为6,message length(body size字段)为628.type id代表body的帧类型为9,是视频帧。

5.4.1.2.3. 类型 2
类型 2 块头长度为 3 个字节。即AMF2包头为3字节。既不包含流 ID 也不包含消息长度;这一块具有和前一块相同的流 ID 和消息长度。具有不变长度的消息 (例如,一些音频和数据格式) 应该在第一块之后使用这一格式表示之后的每个新消息。

图例3:符合AMF2类型的包
例如图例3,是一个fmt=2的rtmp的固定长度的数据包。csid=37,图中选中字段为不包含消息流ID 1字节的AMF2包头(3字节,消息流ID为0xa5)。其中timestamp delta为4357388,无message length字段,因为默认与前以对应csid包的数据大小相同。没有帧类型,紧跟数据。

5.4.1.2.4. 类型 3
类型 3 的块没有消息头。流 ID、消息长度以及 timestamp delta 等字段都不存在;这种类型的块使用前面块一样的块流 ID。即AMF3无包头。当单一一个消息被分割为多块时,除了第一块的其他块都应该使用这种类型。参考例 2 (5.3.2.2 小节)。组成流的消息具有同样的大小,流 ID 和时间间隔应该在类型 2 之后的所有块都使用这一类型。参考例 1 (5.3.2.1 小节)。如果第一个消息和第二个消息之间的 delta 和第一个消息的 timestamp 一样的话,那么在类型 0 的块之后要紧跟一个类型 3 的块,因为无需再来一个类型 2 的块来注册 delta 了。如果一个类型 3 的块跟着一个类型 0 的块,那么这个类型 3 块的 timestamp delta 和类型 0 块的 timestamp 是一样的。5.4.1.2.5. 通用头字段
块消息头中各字段的描述如下:timestamp delta (三个字节):对于一个类型 1 或者类型 2 的块,前一块的 timestamp 和当前块的 timestamp 的区别在这里发送。如果 delta 大于或者等于 16777215 (十六进制 0xFFFFFF),那么这一字段必须是为 16777215,表示具有扩展 timestamp 字段来对整个 32 位 delta 进行编码。否则的话,这一字段应该是为具体 delta。
message length (三个字节):对于一个类型 0 或者类型 1 的块,消息长度在这里进行发送。注意这通常不同于块的有效载荷的长度。块的有效载荷代表所有的除了最后一块的最大块大小,以及剩余的 (也可能是小消息的整个长度) 最后一块。
message type id (消息类型 id,一个字节):对于类型 0 或者类型 1 的块,消息的类型在这里发送。
message stream id (四个字节):对于一个类型为 0 的块,保存消息流 ID。消息流 ID 以小端格式保存。所有同一个块流下的消息都来自同一个消息流。当可以将不同的消息流组合进同一个块流时,这种方法比头压缩的做法要好。但是,当一个消息流被关闭而其他的随后另一个是打开着的,就没有理由将现有块流以发送一个新的类型 0 的块进行复用了。
5.4.1.3. 扩展 timestamp
扩展 timestamp 字段用于对大于 16777215 (0xFFFFFF) 的 timestamp 或者 timestamp delta 进行编码;也就是,对于不适合于在 24 位的类型 0、1 和 2 的块里的 timestamp 和 timestamp delta 编码。这一字段包含了整个 32 位的 timestamp 或者 timestamp delta 编码。可以通过设置类型 0 块的 timestamp 字段、类型 1 或者 2 块的 timestamp delta 字段 16777215 (0xFFFFFF) 来启用这一字段。当最近的具有同一块流的类型 0、1 或 2 块指示扩展 timestamp 字段出现时,这一字段才会在类型为 3 的块中出现。5.4.2. 例子
5.4.2.1. 例子 1
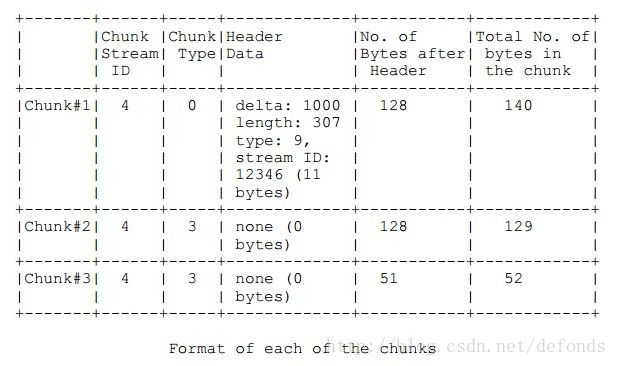
这个例子演示了一个简单地音频消息流。这个例子演示了信息的冗余。
5.4.2.2. 例子 2
这一例子阐述了一条消息太大,无法装在一个 128 字节的块里,被分割为若干块。
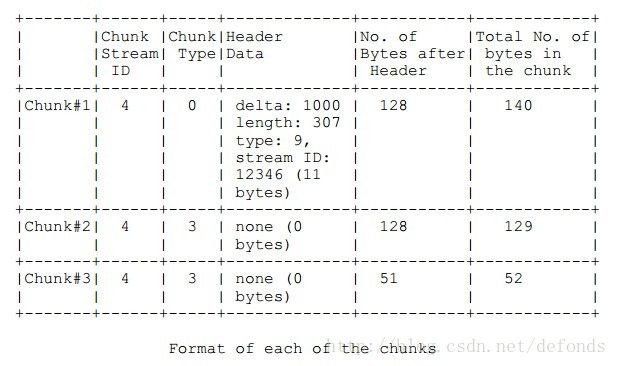
由以上俩例子可以得知,块类型 3 可以被用于两种不同的方式。第一种是用于定义一条消息的配置。第二种是定义一个可以从现有状态数据中派生出来的新消息的起点。
5.5. 协议控制消息
RTMP 块流使用消息类型 ID(stream id) 为 1、2、3、5 和 6 用于协议控制消息。这些消息包含有 RTMP 块流协议所需要的信息。这些协议控制消息必须使用消息流 ID 0 (作为已知控制流) 并以流 ID 为 2 的块发送。协议控制消息一旦被接收到就立即生效;协议控制消息的 timestamp 被忽略。
5.5.1. 设置块类型 (1=set chunk size)
协议控制消息 1,设置块大小,以通知对端一个新的最大块大小(set chunk size)。默认的最大块大小是为 128 字节,但是客户端或者服务器可以改变这个大小,并使用这一消息对对端进行更新。例如,假定一个客户端想要发送一个 131 字节的音频数据,当前块大小是默认的 128。在这种情况下,客户端可以发送这种消息到服务器以通知它块大小现在是 131 字节了。这样客户端就可以在单一块中发送整个音频数据了。
最大块大小设置的话最少为 128 字节,包含内容最少要一个字节。最大块大小由每个方面 (服务器或者客户端) 自行维护。

chunk size (块大小,31 位):这一字段保存新的最大块大小值,以字节为单位,这将用于之后发送者发送的块,直到有更多 (关于最大块大小的) 通知。有效值为 1 到 2147483647 (0x7FFFFFFF,1 和 2147483647 都可取); 但是所有大于 16777215 (0xFFFFFF) 的大小值是等价的,因为没有一个块比一整个消息大,并且没有一个消息大于 16777215 字节。
5.5.2. 终止消息(2,)
协议控制消息 2,终止消息,用于通知对端,如果对端在等待去完成一个消息的块的话,然后抛弃一个块流中已接受到的部分消息。对端接收到块流 ID 作为当前协议消息的有效负载。一些程序可能会在关闭的时候使用这个消息以指示不需要进一步对这个消息的处理了。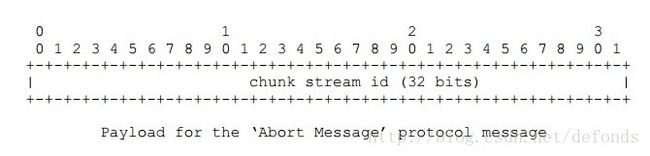
5.5.3. 确认 (3=acknowledgement)
客户端或者服务器在接收到等同于窗口大小的字节之后必须要发送给对端一个确认。窗口大小是指发送者在没有收到接收者确认之前发送的最大数量的字节。这个消息定义了序列号,也就是目前接收到的字节数。
5.5.4. 窗口确认大小 (5=window acknowledgement size)
客户端或者服务器端发送这条消息来通知对端发送和应答之间的窗口大小。发送者在发送完窗口大小字节之后期待对端的确认。接收端在上次确认发送后接收到的指示数值后,或者会话建立之后尚未发送确认,必须发送一个确认 (5.4.3 小节)。
5.5.5. 设置对端带宽 (6=set peer bandwidth)
客户端或者服务器端发送这一消息来限制其对端的输出带宽。对端接收到这一消息后,将通过限制这一消息中窗口大小指出的已发送但未被答复的数据的数量以限制其输出带宽。如果这个窗口大小不同于其发送给 (设置对端带宽) 发送者的最后一条消息,那么接收到这一消息的对端应该回复一个窗口确认大小消息。
0 - Hard:对端应该限制其输出带宽到指示的窗口大小。
1 - Soft:对端应该限制其输出带宽到指示的窗口大小,或者已经有限制在其作用的话就取两者之间的较小值。
2 - Dynamic:如果先前的限制类型为 Hard,处理这个消息就好像它被标记为 Hard,否则的话忽略这个消息。
6. RTMP 消息格式
这一节定义了使用下层传输层 (比如 RTMP 块流协议) 传输的 RTMP 消息的格式。RTMP 协议设计使用 RTMP 块流,可以使用其他任意传输协议对消息进行发送。RTMP 块流和 RTMP 一起适用于多种音频 - 视频应用,从一对一和一对多直播到点播服务,再到互动会议应用。
6.1. RTMP 消息格式
服务器端和客户端通过网络发送 RTMP 消息来进行彼此通信。消息可以包含音频、视频、数据,或者其他消息。RTMP 消息有两部分:头和它的有效载荷。
6.1.1. 消息头
消息头包含以下:Message Type (消息类型):一个字节的字段来表示消息类型。类型 ID 1 - 6 被保留用于协议控制消息。
Length (长度):三个字节的字段来表示有效负载的字节数。以大端格式保存。
Timestamp:四个字节的字段包含了当前消息的 timestamp。四个字节也以大端格式保存。
Message Stream Id (消息流 ID):三个字节的字段以指示出当前消息的流。这三个字节以大端格式保存。

6.1.2. 消息有效载荷
消息的另一个部分就是有效负载,这是这个消息所包含的实际内容。例如,它可以是一些音频样本或者压缩的视频数据。有效载荷格式和解释不在本文档范围之内。
6.2. 用户控制消息 (4=user control message)
RTMP 使用消息类型 ID(message type ID) 4 表示用户控制消息。这些消息包含 RTMP 流传输层所使用的信息。RTMP 块流协议使用 ID 为 1、2、3、5 和 6 (5.4 节介绍)。用户控制消息应该使用消息流 ID(message stream ID) 0 (以被认为是控制流),并且以 RTMP 块流发送时以块流 ID(chunk stream id) 为 2。用户控制消息一旦被接收立马生效;它们的 timestamp 是被忽略的。
客户端或者服务器端发送这个消息来通知对端用户操作事件。这一消息携带有事件类型和事件数据。

事件类型和事件数据格式将在 7.1.7 小节列出。
7. RTMP 命令消息
这一节描述了在服务器端和客户端彼此通信交换的消息和命令的不同的类型。
服务器端和客户端交换的不同消息类型包括用于发送音频数据的音频消息、用于发送视频数据的视频消息、用于发送任意用户数据的数据消息、共享对象消息以及命令消息。共享对象消息提供了一个通用的方法来管理多用户和一台服务器之间的分布式数据。命令消息在客户端和服务器端传输 AMF 编码的命令。客户端或者服务器端可以通过使用命令消息和对端通信的流请求远程方法调用 (RPC)。
7.1. 消息的类型
服务器端和客户端通过在网络中发送消息来进行彼此通信。消息可以是任何类型,包含音频消息,视频消息,命令消息,共享对象消息,数据消息,以及用户控制消息。7.1.1. 命令消息 (20, 17)
命令消息(类似play、connect、closestream)在客户端和服务器端传递 AMF 编码的命令。这些消息被分配以消息类型值为 20 以进行 AMF0(AMF0 command 0x14) 编码,消息类型值为 17(AMF3 command 0x11)以进行 AMF3 编码。这些消息发送以进行一些操作,比如,连接,创建流,发布,播放,对端暂停。命令消息,像 onstatus、result 等等,用于通知发送者请求的命令的状态。一个命令消息由命令名、事务 ID 和包含相关参数的命令对象组成。一个客户端或者一个服务器端可以通过和对端通信的流使用这些命令消息请求远程调用 (RPC)。7.1.2. 数据消息 (18, 15)
客户端或者服务器端通过发送这些消息以发送元数据或者任何用户数据到对端。元数据包括数据 (音频,视频等等) 的详细信息,比如创建时间,时长,主题等等。这些消息被分配以消息类型为 18 以进行 AMF0 编码和消息类型 15 以进行 AMF3 编码。7.1.3. 共享对象消息 (19, 16)
所谓共享对象其实是一个 Flash 对象 (一个名值对的集合),这个对象在多个不同客户端、应用实例中保持同步。消息类型 19 用于 AMF0 编码、16 用于 AMF3 编码都被为共享对象事件保留。每个消息可以包含有不同事件。
| 事件 | 描述 |
|---|---|
| Use(=1) | 客户端发送这一事件以通知服务器端一个已命名的共享对象已创建。 |
| Release(=2) | 当共享对象在客户端被删除时客户端发送这一事件到服务器端。 |
| Request Change (=3) | 客户端发送给服务器端这一事件以请求共享对象的已命名的参数所关联到的值的改变。 |
| Change (=4) | 服务器端发送这一事件已通知发起这一请求之外的所有客户端,一个已命名参数的值的改变。 |
| Success (=5) | 如果请求被接受,服务器端发送这一事件给请求的客户端,以作为 RequestChange 事件的响应。 |
| SendMessage (=6) | 客户端发送这一事件到服务器端以广播一条消息。一旦接收到这一事件,服务器端将会给所有的客户端广播这一消息,包括这一消息的发起者。 |
| Status (=7) | 服务器端发送这一事件以通知客户端异常情况。 |
| Clear (=8) | 服务器端发送这一消息到客户端以清理一个共享对象。服务器端也会对客户端发送的 Use 事件使用这一事件进行响应。 |
| Remove (=9) | 服务器端发送这一事件有客户端删除一个 slot。 |
| Request Remove (=10) | 客户端发送这一事件有客户端删除一个 slot。 |
| Use Success (=11) | 服务器端发送给客户端这一事件表示连接成功。 |
7.1.4. 音频消息 (8=audio data)
客户端或者服务器端发送这一消息以发送音频数据到对端。消息类型 8 为音频消息保留。7.1.5. 视频消息 (9=video data)
客户端或者服务器发送这一消息以发送视频数据到对端。消息类型 9 为视频消息保留。7.1.6. 统计消息 (22)
统计消息是一个单一的包含一系列的使用 6.1 节描述的 RTMP 子消息的消息。消息类型 22 用于统计消息。其实就是0x16大包消息。

统计消息里的 timestamp 和第一个子消息的 timestamp 的不同点在于子消息的 timestamp 被相对流时间标调整了偏移。每个子消息的 timestamp 被加入偏移以达到一个统一流时间。第一个子消息的 timestamp 应该和统计消息的 timestamp 一样,所以这个偏移量应该为 0。
反向指针包含有前一个消息的大小 (包含前一个消息的头)。这样子匹配了 FLV 文件的格式,用于反向查找。
使用统计消息具有以下性能优势:
- 块流可以在一个块中以至多一个单一完整的消息发送。因此,增加块大小并使用统计消息减少了发送块的数量。
- 子消息可以在内存中连续存储。在网络中系统调用发送这些数据时更高效。
7.1.7. 用户控制消息事件
客户端或者服务器端发送这一消息来通知对端用户控制事件。关于这个的消息格式参考 6.2 节。支持以下用户控制事件类型:
| 事件 | 描述 |
| Stream Begin (=0) | 服务器发送这个事件来通知客户端一个流已就绪并可以用来通信。默认情况下,这一事件在成功接收到客户端的应用连接命令之后以 ID 0 发送。这一事件数据为 4 字节,代表了已就绪流的流 ID。 |
| Stream EOF (=1) | 服务器端发送这一事件来通知客户端请求的流的回放数据已经结束。在发送额外的命令之前不再发送任何数据。客户端将丢弃接收到的这个流的消息。这一事件数据为 4 字节,代表了回放已结束的流的流 ID。 |
| StreamDry (=2) | 服务器端发送这一事件来通知客户端当前流中已没有数据。当服务器端在一段时间内没有检测到任何消息,它可以通知相关客户端当前流已经没数据了。这一事件数据为 4 字节,代表了已没数据的流的流 ID。 |
| SetBuffer Length (=3) | 客户端发送这一事件来通知服务器端用于缓存流中任何数据的缓存大小 (以毫秒为单位)。这一事件在服务器端开始处理流之前就发送。这一事件数据的前 4 个字节代表了流 ID 后 4 个字节代表了以毫秒为单位的缓存的长度。 |
| StreamIs Recorded (=4) | 服务器端发送这一事件来通知客户端当前流是一个录制流。这一事件数据为 4 字节,代表了录制流的流 ID。 |
| PingRequest (=6) | 服务器端发送这一事件用于测试是否能够送达客户端。时间数据是为一个 4 字节的 timestamp,代表了服务器端发送这一命令时的服务器本地时间。客户端在接收到这一消息后会立即发送 PingResponse 回复。 |
| PingResponse (=7) | 客户端作为对 ping 请求的回复发送这一事件到服务器端。这一事件数据是为一个 4 字节的 timestamp,就是接收自 PingRequest 那个。 |
7.2. 命令类型
客户端和服务器端交换 AMF 编码的命令。服务器端发送一个命令消息,这个命令消息由命令名、事务 ID 以及包含有相关参数的命令对象组成。例如,包含有 'app' 参数的连接命令,这个命令说明了客户端连接到的服务器端的应用名。接收者处理这一命令并回发一个同样事务 ID 的响应。回复字符串可以是 _result、_error 或者一个方法名的任意一个,比如,verifyClient 或者 contactExternalServer。命令字符串 _result 或者 _error 是响应信号。事务 ID 指示出响应所指向的命令。这和 AMAP 和其他一些协议的标签一样。命令字符串中的方法名表示发送者试图执行接收者一端的一个方法。
以下类的对象用于发送不同的命令:
NetConnection 代表上层的服务器端和客户端之间连接的一个对象。
NetStream 一个代表发送音频流、视频流和其他相关数据的通道的对象。当然,我们也会发送控制数据流的命令,诸如 play、pause 等等。
7.2.1. NetConnection 命令
NetConnection 管理着一个客户端应用和服务器端之间的双相连接。此外,它还提供远程方法的异步调用。NetConnection 可以发送以下命令:
- connect
- call
- close
- createStream
7.2.1.1. connect 命令
客户端发送 connect 命令到服务器端来请求连接到一个服务器应用的实例。由客户端发送到服务器端的 connect 命令结构如下:
| 字段名 | 类型 | 描述 |
| Command Name | 字符串 | 命令的名字。设置给 "connect"。 |
| Transaction ID | 数字 | 总是设置为 1。 |
| Command Object | 对象 | 具有名值对的命令信息对象。 |
| Optional User Arguments | 对象 | 任意可选信息。 |
以下是为 connect 命令中使用的名值对对象的描述。
| 属性 | 类型 | 描述 | 范例 |
| app | 字符串 | 客户端连接到的服务器端应用的名字。 | testapp |
| flashver | 字符串 | Flash Player 版本号。和ApplicationScript getversion() 方法返回的是同一个字符串。 | FMSc/1.0 |
| swfUrl | 字符串 | 进行当前连接的 SWF 文件源地址。例如:app/viewplayer.swf | file://C:/FlvPlayer.swf |
| tcUrl | 字符串 | 服务器 URL。具有以下格式:protocol://servername:port/appName/appInstance,例如rtmp:IP:PORT/live/ | rtmp://localhost:1935/testapp/instance1 |
| fpad | 布尔 | 如果使用了代理就是 true。 | true 或者 false。 |
| audioCodecs | 数字 | 表明客户端所支持的音频编码。 | SUPPORT_SND_MP3 |
| videoCodecs | 数字 | 表明支持的视频编码。 | SUPPORT_VID_SORENSON |
| videoFunction | 数字 | 表明所支持的特殊视频方法。 | SUPPORT_VID_CLIENT_SEEK |
| pageUrl | 字符串 | SWF 文件所加载的网页 URL。可以是undefined | http://somehost/sample.html |
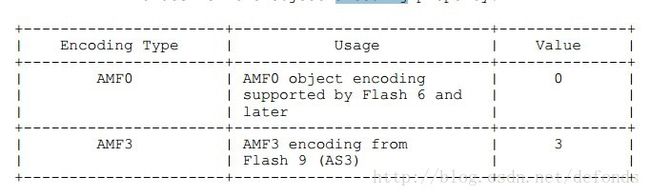
| objectEncoding | 数字 | AMF 编码方法。0、3.一般采用3 | AMF3 |
audioCodecs 属性的标识值:
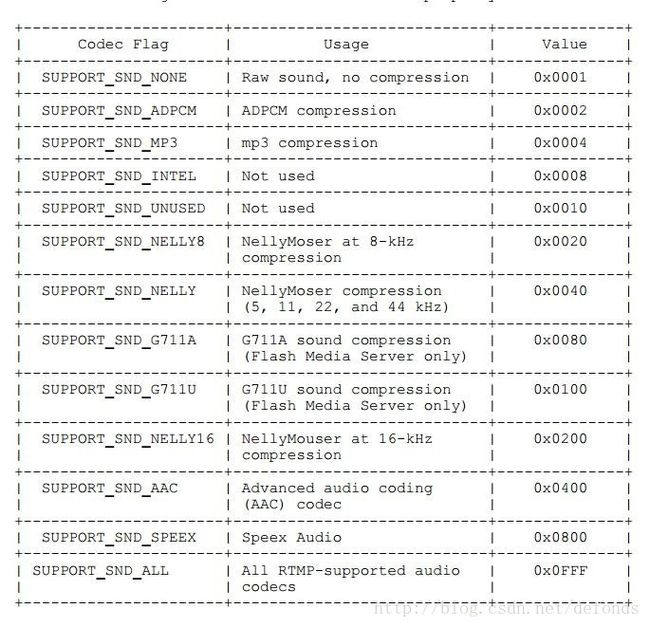
videoCodecs 属性的标识值:

videoFunction 属性的标识值:

encoding 属性值:
服务器端到客户端的命令的结构如下:



命令执行时消息流动如下:
1. 客户端发送 connect 命令到服务器端以请求对服务器端应用实例的连接。
2. 收到 connect 命令后,服务器端发送协议消息 '窗口确认大小' 到客户端。服务器端也会连接到 connect 命令中提到的应用。
3. 服务器端发送协议消息 '设置对端带宽' 到客户端。
4. 在处理完协议消息 '设置对端带宽' 之后客户端发送协议消息 '窗口确认大小' 到服务器端。
5. 服务器端发送另一个用户控制消息 (StreamBegin) 类型的协议消息到客户端。
6. 服务器端发送结果命令消息告知客户端连接状态 (success/fail)。这一命令定义了事务 ID (常常为 connect 命令设置为 1)。这一消息也定义了一些属性,比如 FMS 服务器版本 (字符串)。此外,它还定义了其他连接关联到的信息,比如 level (字符串)、code (字符串)、description (字符串)、objectencoding (数字) 等等。
7.2.1.2. call 方法
NetConnection 对象的 call 方法执行接收端远程方法的调用 (PRC)。被调用的 PRC 名字作为一个参数传给调用命令。发送端发送给接收端的命令结构如下:
| 字段名 | 类型 | 描述 |
| Procedure Name | 字符串 | 调用的远程方法的名字。 |
| Transaction ID | 数字 | 如果期望回复我们要给一个事务 ID。否则我们传 0 值即可。 |
| Command Object | 对象 | 如果存在一些命令信息要设置这个对象,否则置空。 |
| Optional Arguments | 对象 | 任意要提供的可选参数。 |
回复的命令结构如下:
| 字段名 | 类型 | 描述 |
| Command Name | 字符串 | 命令的名字。 |
| Transaction ID | 数字 | 响应所属的命令的 ID。 |
| Command Object | 对象 | 如果存在一些命令信息要设置这个对象,否则置空。 |
| Response | 对象 | 调用方法的回复。 |
7.2.1.3. createStream 命令
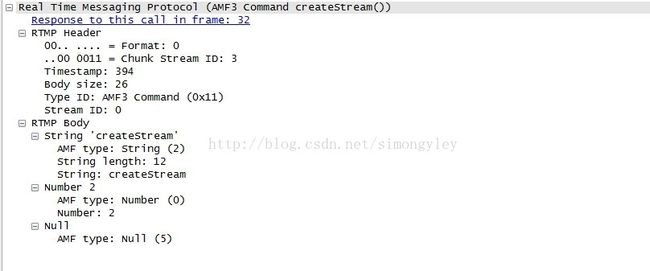
NetConnection 是默认的通信通道,流 ID 为 0。协议和一些命令消息,包括 createStream,使用默认的通信通道。
客户端发送给服务器端的命令结构如下:
| 字段名 | 类型 | 描述 |
| Command Name | 字符串 | 命令名。设置给 "createStream"。 |
| Transaction ID | 数字 | 命令的事务 ID。 |
| Command Object | 对象 | 如果存在一些命令信息要设置这个对象,否则置空。 |
服务器端发送给客户端的命令结构如下:
| 字段名 | 类型 | 描述 |
| Command Name | 字符串 | _result 或者 _error;表明回复是一个结果还是错误。 |
| Transaction ID | 数字 | 响应所属的命令的 ID。 |
| Command Object | 对象 | 如果存在一些命令信息要设置这个对象,否则置空。 |
| Stream ID | 数字 | 返回值要么是一个流 ID 要么是一个错误信息对象。 |
7.2.2. NetStream 命令
NetStream 定义了传输通道,通过这个通道,音频流、视频流以及数据消息流可以通过连接客户端到服务端的 NetConnection 传输。以下命令可以由客户端使用 NetStream 往服务器端发送:
- play
- play2
- deleteStream
- closeStream
- receiveAudio
- receiveVideo
- publish
- seek
- pause
服务器端使用 "onStatus" 命令向客户端发送 NetStream 状态:
| 字段名 | 类型 | 描述 |
| Command Name | 字符串 | 命令名 "onStatus"。 |
| Transaction ID | 数字 | 事务 ID 设置为 0。 |
| Command Object | Null | onStatus 消息没有命令对象。 |
| Info Object | 对象 | 一个 AMF 对象至少要有以下三个属性。"level" (字符串):这一消息的等级,"warning"、"status"、"error" 中的某个值;"code" (字符串):消息码,例如 "NetStream.Play.Start";"description" (字符串):关于这个消息人类可读描述。 |
7.2.2.1. play 命令
客户端发送这一命令到服务器端以播放流。也可以多次使用这一命令以创建一个播放列表。如果你想要创建一个动态的播放列表这一可以在不同的直播流或者录制流之间进行切换播放的话,多次调用 play 方法,并在每次调用时设置Reset的值为 false。相反的,如果你想要立即播放指定流,需要将其他等待播放的流清空,并为将Reset设为 true。
客户端发送到服务器端的命令结构如下:
| 字段名 | 类型 | 描述 |
| Command Name | 字符串 | 命令名。设为 "play"。 |
| Transaction ID | 数字 | 事务 ID 设为 0。 |
| Command Object | Null | 命令信息不存在。设为 null 类型。 |
| Stream Name | 字符串 | 要播放流的名字。要播放视频 (FLV) 文件,使用没有文件扩展名的名字对流名进行定义 (例如,"sample")。要重播 MP3 或者 ID3,你必须在流名前加上 mp3:例如,"mp3:sample"。要播放 H.264/AAC 文件,你必须在流名前加上 mp4:并指定文件扩展名。例如,要播放 sample.m4v 文件,定义 "mp4:sample.m4v"。 |
| Start | 数字 | 一个可选的参数,以秒为单位定义开始时间。默认值为 -2,表示用户首先尝试播放流名字段中定义的直播流。如果那个名字的直播流没有找到,它将播放同名的录制流。如果没有那个名字的录制流,客户端将等待一个新的那个名字的直播流,并当其有效时进行播放。如果你在 Start 字段中传递 -1,那么就只播放流名中定义的那个名字的直播流。如果你在 Start 字段中传递 0 或一个整数,那么将从 Start 字段定义的时间开始播放流名中定义的那个录制流。如果没有找到录制流,那么将播放播放列表中的下一项。 |
| Duration | 数字 | 一个可选的参数,以秒为单位定义了回放的持续时间。默认值为 -1。-1 值意味着一个直播流会一直播放直到它不再可用或者一个录制流一直播放直到结束。如果你传递 0 值,它将只播放单一一帧,因为播放时间已经在录制流的开始的 Start 字段指定了。假定定义在 Start 字段中的值大于或者等于 0。如果你传递一个正数,将播放 Duration 字段定义的一段直播流。之后,变为可播放状态,或者播放 Duration 字段定义的一段录制流。(如果流在 Duration 字段定义的时间段内结束,那么流结束时回放结束)。如果你在 Duration 字段中传递一个 -1 以外的负数的话,它将把你给的值当做 -1 处理。 |
| Reset | 布尔 | 一个可选的布尔值或者数字定义了是否对以前的播放列表进行 flush。 |
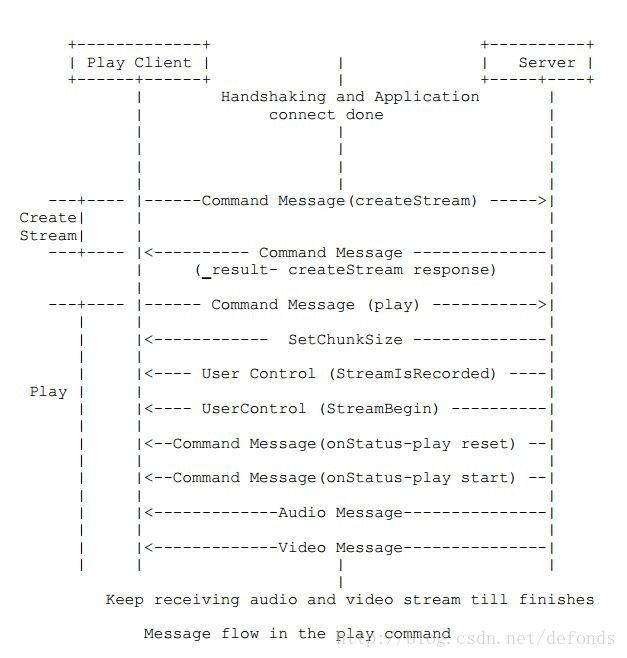
命令执行时的消息流动是为:
1. 当客户端从服务器端接收到 createStream 命令的结果是为 success 时,发送 play 命令。
2. 一旦接收到 play 命令,服务器端发送一个协议消息来设置块大小。
3. 服务器端发送另一个协议消息 (用户控制),这个消息中定义了 'StreamIsRecorded' 事件和流 ID。消息在前两个字节中保存事件类型,在后四个字节中保存流 ID。
4. 服务器端发送另一个协议消息 (用户控制),这一消息包含 'StreamBegin' 事件,来指示发送给客户端的流的起点。
5. 如果客户端发送的 play 命令成功,服务器端发送一个 onStatus 命令消息 NetStream.Play.Start & NetStream.Play.Reset。只有当客户端发送的 play 命令设置了 reset 时服务器端才会发送 NetStream.Play.Reset。如果要播放的流没有找到,服务器端发送 onStatus 消息 NetStream.Play.StreamNotFound。
之后,服务器端发送视频和音频数据,客户端对其进行播放。
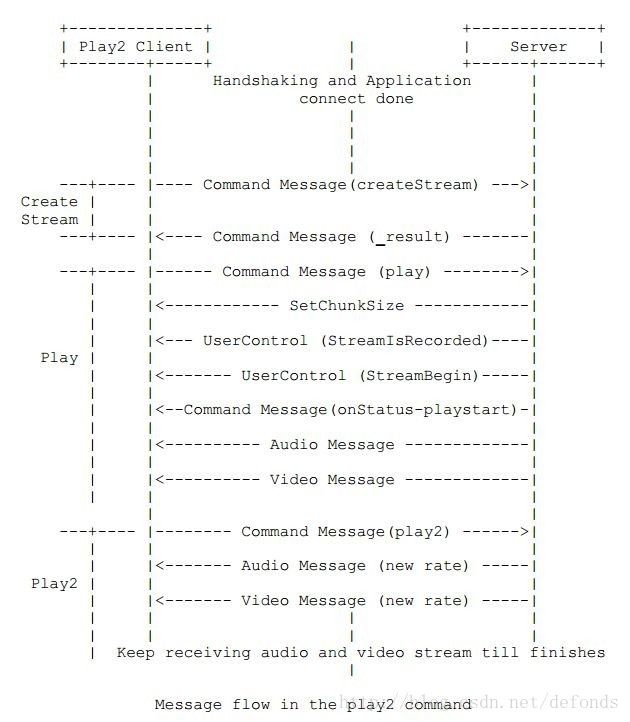
7.2.2.2. play2
不同于 play 命令的是,play2 可以在不改变播放内容时间轴的情况下切换到不同的比特率。服务器端为客户端可以在 play2 中请求所有支持的码率维护了不同的字段。客户端发送给服务器端的命令结构如下:
| 字段名 | 类型 | 描述 |
| Command Name | 字符串 | 命令名,设置为 "play2"。 |
| Transaction ID | 数字 | 事务 ID 设置为 0。 |
| Command Object | Null | 命令信息不存在,设置为 null 类型。 |
| Parameters | 对象 | 一个 AMF 编码的对象,该对象的属性是为公开的 flash.net.NetStreamPlayOptions ActionScript 对象所描述的属性。 |
NetStreamPlayOptions 对象的公开属性在 ActionScript 3 语言指南中 [AS3] 有所描述。
命令执行时的消息流动如下图所示:
7.2.2.3. deleteStream 命令
当 NetStream 对象消亡时 NetStream 发送 deleteStream 命令。客户端发送给服务器端的命令结构如下:
| 字段名 | 类型 | 描述 |
| Command Name | 字符串 | 命令名,设置为 "deleteStream"。 |
| Transaction ID | 数字 | 事务 ID 设置为 0。 |
| Command Object | Null | 命令信息对象不存在,设为 null 类型。 |
| Stream ID | 数字 | 服务器端消亡的流 ID。 |
服务器端不再发送任何回复。
7.2.2.4. receiveAudio 命令
NetStream 通过发送 receiveAudio 消息来通知服务器端是否发送音频到客户端。客户端发送给服务器端的命令结构如下:
| 字段名 | 类型 | 描述 |
| Command Name | 字符串 | 命令名,设置为 "receiveAudio"。 |
| Transaction ID | 数字 | 事务 ID 设置为 0。 |
| Command Object | Null | 命令信息对象不存在,设置为 null 类型。 |
| Bool Flag | 布尔 | true 或者 false 以表明是否接受音频。 |
如果发送来的 receiveAudio 命令布尔字段被设为 false 时服务器端不发送任何回复。如果这一标识被设为 true,服务器端以状态消息 NetStream.Seek.Notify 和 NetStream.Play.Start 进行回复。
7.2.2.5. receiveVideo 命令
NetStream 通过发送 receiveVideo 消息来通知服务器端是否发送视频到客户端。客户端发送给服务器端的命令结构如下:
| 字段名 | 类型 | 描述 |
|---|---|---|
| Command Name | 字符串 | 命令名,设置为 "receiveVideo"。 |
| Transaction ID | 数字 | 事务 ID 设置为 0。 |
| Command Object | Null | 命令信息对象不存在,设置为 null 类型。 |
| Bool Flag | 布尔 | true 或者 false 以表明是否接受视频。 |
如果发送来的 receiveVideo 命令布尔字段被设为 false 时服务器端不发送任何回复。如果这一标识被设为 true,服务器端以状态消息 NetStream.Seek.Notify 和 NetStream.Play.Start 进行回复。
7.2.2.6. publish 命令
客户端发送给服务器端这一命令以发布一个已命名的流。使用这个名字,任意客户端都可以播放这个流,并接受发布的音频、视频以及数据消息。客户端发送给服务器端的命令结构如下:
| 字段名 | 类型 | 描述 |
|---|---|---|
| Command Name | 字符串 | 命令名,设置为 "publish"。 |
| Transaction ID | 数字 | 事务 ID 设置为 0。 |
| Command Object | Null | 命令信息对象不存在,设置为 null 类型。 |
| Publishing Name | 字符串 | 发布的流的名字。 |
| Publishing Type | 字符串 | 发布类型。可以设置为 "live"、"record" 或者 "append"。record:流被发布,数据被录制到一个新的文件。新文件被存储在服务器上包含服务应用目录的子路径。如果文件已存在,将重写。append:流被发布,数据被添加到一个文件。如果该文件没找着,将新建一个。live:直播数据只被发布,并不对其进行录制。 |
服务器端回复 onStatus 命令以标注发布的起始位置。
7.2.2.7. seek 命令
客户端发送 seek 命令以查找一个多媒体文件或一个播放列表的偏移量 (以毫秒为单位)。客户端发送到服务器端的命令结构如下:
| 字段名 | 类型 | 描述 |
|---|---|---|
| Command Name | 字符串 | 命令的名字,设为 "seek"。 |
| Transaction ID | 数字 | 事务 ID 设为 0。 |
| Command Object | Null | 没有命令信息对象,设置为 null 类型。 |
| milliSeconds | 数字 | 播放列表查找的毫秒数。 |
seek 命令执行成功时服务器会发送一个状态消息 NetStream.Seek.Notify。失败的话,服务器端返回一个 _error 消息。
7.2.2.8. pause 命令
客户端发送 pause 命令以告知服务器端是暂停还是开始播放。客户端发送给服务器端的命令结构如下:
| 字段名 | 类型 | 描述 |
|---|---|---|
| Command Name | 字符串 | 命令名,设为 "pause"。 |
| Transaction ID | 数字 | 没有这一命令的事务 ID,设为 0。 |
| Command Object | Null | 命令信息对象不存在,设为 null 类型。 |
| Pause/Unpause Flag | 布尔 | true 或者 false,来指示暂停或者重新播放。 |
| milliSeconds | 数字 | 流暂停或者重新开始所在的毫秒数。这个是客户端暂停的当前流时间。当回放已恢复时,服务器端值发送带有比这个值大的 timestamp 消息。 |
当流暂停时,服务器端发送一个状态消息 NetStream.Pause.Notify。NetStream.Unpause.Notify 只有针对没有暂停的流进行发放。失败的话,服务器端返回一个 _error 消息。
7.3. 消息交换例子
这里有几个解释使用 RTMP 交换消息的例子。7.3.1. 发布录制视频
这个例子说明了一个客户端是如何能够发布一个直播流然后传递视频流到服务器的。然后其他客户端可以对发布的流进行订阅并播放视频。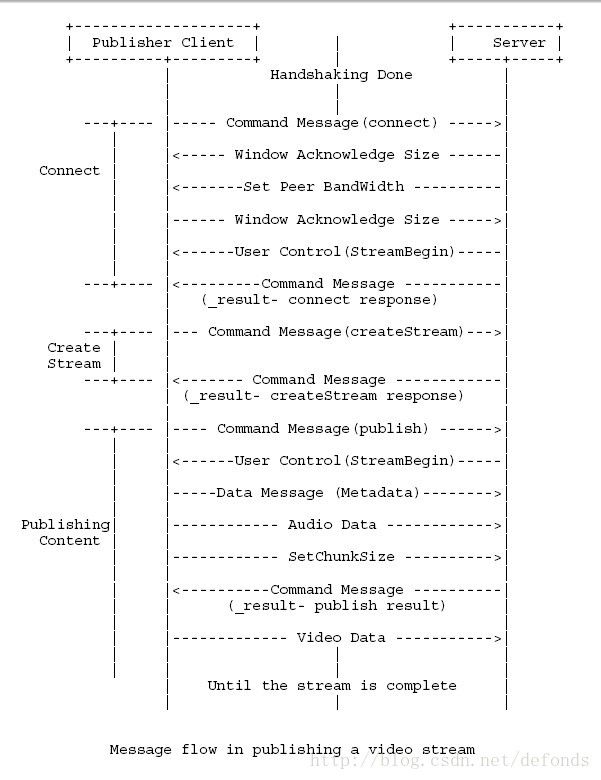
7.3.2. 广播一个共享对象消息
这个例子说明了在一个共享对象的创建和改变期间交换消息的变化。它也说明了共享对象消息广播的处理过程。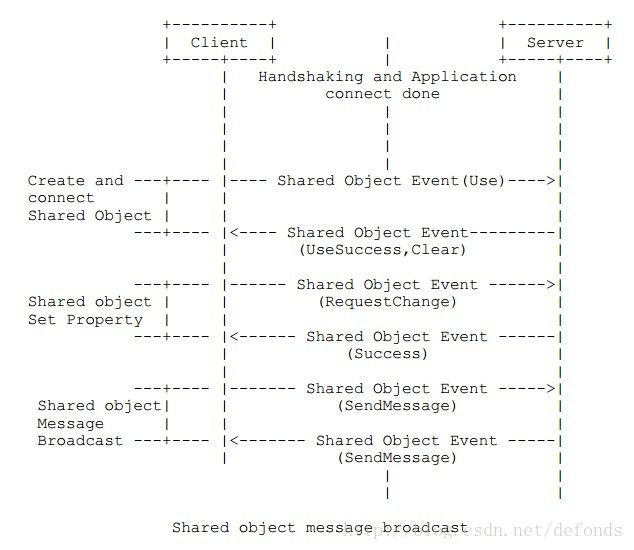
7.3.3. 发布来自录制流的元数据
这个例子描述了用于发布元数据的消息交换。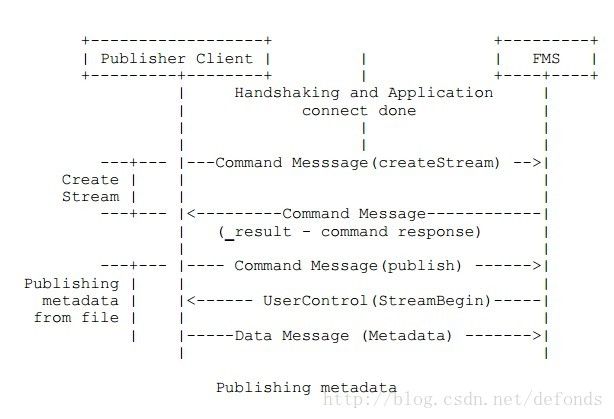
8. 参考文献
[RFC0791] Postel, J., "Internet Protocol", STD 5, RFC 791, September 1981.[RFC0793] Postel, J., "Transmission Control Protocol", STD 7,RFC 793, September 1981.
[RFC1982] Elz, R. and R. Bush, "Serial Number Arithmetic", RFC 1982, August 1996.
[RFC2119] Bradner, S., "Key words for use in RFCs to Indicate Requirement Levels", BCP 14, RFC 2119, March 1997.
[AS3] Adobe Systems, Inc., "ActionScript 3.0 Reference for the Adobe Flash Platform", 2011,
[AMF0] Adobe Systems, Inc., "Action Message Format -- AMF 0", December 2007,
[AMF3] Adobe Systems, Inc., "Action Message Format -- AMF 3", May 2008,
作者地址
Hardeep Singh Parmar (editor)
Adobe Systems Incorporated
345 Park Ave
San Jose, CA 95110-2704
US
Phone: +1 408 536 6000
Email: [email protected]
URI: http://www.adobe.com/
Michael C. Thornburgh (editor)
Adobe Systems Incorporated
345 Park Ave
San Jose, CA 95110-2704
US
Phone: +1 408 536 6000
Email: [email protected]
URI: http://www.adobe.com/
原文链接:http://wwwimages.adobe.com/www.adobe.com/content/dam/Adobe/en/devnet/rtmp/pdf/rtmp_specification_1.0.pdf。