Spring官方文档翻译
一、Spring框架概述
Spring框架是一个轻量级的解决方案,可以一站式地构建企业级应用。Spring是模块化的,所以可以只使用其中需要的部分。可以在任何web框架上使用控制反转(IoC),也可以只使用Hibernate集成代码或JDBC抽象层。它支持声明式事务管理、通过RMI或web服务实现远程访问,并可以使用多种方式持久化数据。它提供了功能全面的MVC框架,可以透明地集成AOP到软件中。
Spring被设计为非侵入式的,这意味着你的域逻辑代码通常不会依赖于框架本身。在集成层(比如数据访问层),会存在一些依赖同时依赖于数据访问技术和Spring,但是这些依赖可以很容易地从代码库中分离出来。
本文档是Spring框架的参考指南,如果你有任何请求、评论或问题,请给我们发邮件,关于框架本身的问题将在StackOverflow上讨论(见https://spring.io.questions)。
1. Spring入门
这篇参考指南提供了Spring框架的详细信息,包括了对所有功能的全面理解,同时也包括一些重要概念的背景(比如,依赖注入)。
如果你才开始使用Spring,可以通过创建一个基于Spring Boot的应用开始使用Spring框架。Spring Boot提供了一种快速创建Spring应用的方式,它基于Spring框架,支持约定优于配置,使你可以尽快启动并运行。
可以使用start.spring.io或遵循入门指南(比如,构建RESTful web应用入门)生成一个基本的项目。除了易于理解,这些指南聚集于一个个任务,它们大部分都是基于Spring Boot的,同时也包含了Spring包下的其它项目,以便你可以考虑何时使用它们解决特定的问题。
2. Spring框架简介
Spring框架是基于Java平台的,它为开发Java应用提供了全方位的基础设施支持,并且它很好地处理了这些基础设施,所以你只需要关注你的应用本身即可。
Spring可以使用POJO(普通的Java对象,plain old Java objects)创建应用,并且可以将企业服务非侵入式地应用到POJO。这项功能适用于Java SE编程模型以及全部或部分的Java EE。
那么,做为开发者可以从Spring获得哪些好处呢?
- 不用关心事务API就可以执行数据库事务;
- 不用关心远程API就可以使用远程操作;
- 不用关心JMX API就可以进行管理操作;
- 不用关心JMS API就可以进行消息处理。
译者注:①JMX,Java Management eXtension,Java管理扩展,是一个为应用程序、设备、系统等植入管理功能的框架。JMX可以跨越一系列异构操作系统平台、系统体系结构和网络传输协议,灵活的开发无缝集成的系统、网络和服务管理应用。②JMS,Java Message Service,Java消息服务,是Java平台上有关面向消息中间件(MOM)的技术规范,它便于消息系统中的Java应用程序进行消息交换,并且通过提供标准的产生、发送、接收消息的接口简化企业应用的开发。
2.1 依赖注入(DI)和控制反转(IoC)
一个Java应用程序,从受限制的嵌入式应用到n层的服务端应用,典型地是由相互合作的对象组成的,因此,一个应用程序中的对象是相互依赖的。
Java平台虽然提供了丰富的应用开发功能,但是它并没有把这些基础构建模块组织成连续的整体,而是把这项任务留给了架构师和开发者。你可以使用设计模式,比如工厂模式、抽象工厂模式、创建者模式、装饰者模式以及服务定位器模式等,来构建各种各样的类和对象实例,从而组成整个应用程序。这些设计模式是很简单的,关键在于它们根据最佳实践起了很好的名字,它们的名字可以很好地描述它们是干什么的、用于什么地方、解决什么问题,等等。这些设计模式都是最佳实践的结晶,所以你应该在你的应用程序中使用它们。
Spring的控制反转解决了上述问题,它提供了一种正式的解决方案,你可以把不相干组件组合在一起,从而组成一个完整的可以使用的应用。Spring根据设计模式编码出了非常优秀的代码,所以可以直接集成到自己的应用中。因此,大量的组织机构都使用Spring来保证应用程序的健壮性和可维护性。
背景
2004年Martin Fowler在他的网站上提出了关于控制反转(IoC,Inversion of Control)的问题,“The question is, what aspect of control are [they] inverting?”,后来,他又建议重新命名这项原则,使其可以自我解释,从而提出了依赖注入(DI,Dependency Injection)的概念。
2.2 模块
Spring大约包含了20个模块,这些模块组成了核心容器(Core Container)、数据访问/集成(Data Access/Integration)、Web、AOP(面向切面编程,Aspect Oriented Programming)、Instrumentation、消息处理(Messaging)和测试(Test),如下图:
图 2.1. Spring框架概述
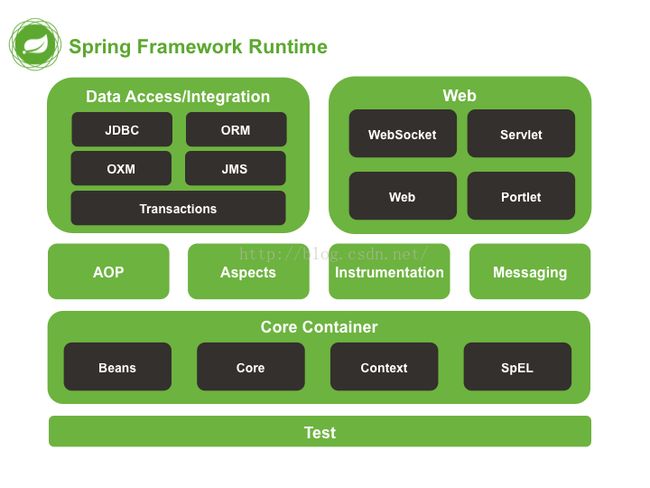
下面列出了每项功能对应的模块及其主题,它们都有人性的名字(artifact name),这些名字与依赖管理工具中的 artifact id 是相互对应的。
2.2.1 核心容器(Core Container)
核心容器包括spring-core,spring-beans,spring-context,spring-context-support和spring-expression(SpEL,Spring表达式语言,Spring Expression Language)等模块。
spring-core和spring-beans模块是Spring框架的基础,包括控制反转和依赖注入等功能。BeanFactory是工厂模式的微妙实现,它移除了编码式单例的需要,并且可以把配置和依赖从实际编码逻辑中解耦。
Context(spring-context)模块是在Core和Bean模块的基础上建立起来的,它以一种类似于JNDI注册的方式访问对象。Context模块继承自Bean模块,并且添加了国际化(比如,使用资源束)、事件传播、资源加载和透明地创建上下文(比如,通过Servelet容器)等功能。Context模块也支持Java EE的功能,比如EJB、JMX和远程调用等。ApplicationContext接口是Context模块的焦点。spring-context-support提供了对第三方库集成到Spring上下文的支持,比如缓存(EhCache, Guava, JCache)、邮件(JavaMail)、调度(CommonJ, Quartz)、模板引擎(FreeMarker, JasperReports, Velocity)等。
spring-expression模块提供了强大的表达式语言用于在运行时查询和操作对象图。它是JSP2.1规范中定义的统一表达式语言的扩展,支持set和get属性值、属性赋值、方法调用、访问数组集合及索引的内容、逻辑算术运算、命名变量、通过名字从Spring IoC容器检索对象,还支持列表的投影、选择以及聚合等。
2.2.2 AOP和检测(Instrumentation)
spring-aop模块提供了面向切面编程(AOP)的实现,可以定义诸如方法拦截器和切入点等,从而使实现功能的代码彻底的解耦出来。使用源码级的元数据,可以用类似于.Net属性的方式合并行为信息到代码中。
spring-aspects模块提供了对AspectJ的集成。
spring-instrument模块提供了对检测类的支持和用于特定的应用服务器的类加载器的实现。spring-instrument-tomcat模块包含了用于tomcat的Spring检测代理。
2.2.3 消息处理(messaging)
Spring 4 包含的spring-messaging模块是从Spring集成项目的关键抽象中提取出来的,这些项目包括Message、MessageChannel、MessageHandler和其它服务于消息处理的项目。这个模块也包含一系列的注解用于映射消息到方法,这类似于Spring MVC基于编码模型的注解。
2.2.4 数据访问与集成
数据访问与集成层包含JDBC、ORM、OXM、JMS和事务模块。
(译者注:JDBC=Java Data Base Connectivity,ORM=Object Relational Mapping,OXM=Object XML Mapping,JMS=Java Message Service)
spring-jdbc模块提供了JDBC抽象层,它消除了冗长的JDBC编码和对数据库供应商特定错误代码的解析。
spring-tx模块支持编程式事务和声明式事务,可用于实现了特定接口的类和所有的POJO对象。
(译者注:编程式事务需要自己写beginTransaction()、commit()、rollback()等事务管理方法,声明式事务是通过注解或配置由spring自动处理,编程式事务粒度更细)
spring-orm模块提供了对流行的对象关系映射API的集成,包括JPA、JDO和Hibernate等。通过此模块可以让这些ORM框架和spring的其它功能整合,比如前面提及的事务管理。
spring-oxm模块提供了对OXM实现的支持,比如JAXB、Castor、XML Beans、JiBX、XStream等。
spring-jms模块包含生产(produce)和消费(consume)消息的功能。从Spring 4.1开始,集成了spring-messaging模块。
2.2.5 Web
Web层包括spring-web、spring-webmvc、spring-websocket、spring-webmvc-portlet等模块。
spring-web模块提供面向web的基本功能和面向web的应用上下文,比如多部分(multipart)文件上传功能、使用Servlet监听器初始化IoC容器等。它还包括HTTP客户端以及Spring远程调用中与web相关的部分。
spring-webmvc模块(即Web-Servlet模块)为web应用提供了模型视图控制(MVC)和REST Web服务的实现。Spring的MVC框架可以使领域模型代码和web表单完全地分离,且可以与Spring框架的其它所有功能进行集成。
spring-webmvc-portlet模块(即Web-Portlet模块)提供了用于Portlet环境的MVC实现,并反映了spring-webmvc模块的功能。
2.2.6 Test
spring-test模块通过JUnit和TestNG组件支持单元测试和集成测试。它提供了一致性地加载和缓存Spring上下文,也提供了用于单独测试代码的模拟对象(mock object)。
2.3 使用场景
前面提及的构建模块使得Spring在很多场景成为一种合理的选择,不管是资源受限的嵌入式应用还是使用了事务管理和web集成框架的成熟的企业级应用。
图2.2. 典型的成熟的Spring web应用程序

Spring的声明式事务管理可以使web应用完成事务化,就像使用EJB容器管理的事务。所有客制的业务逻辑都可以使用简单的POJO实现,并用Spring的IoC容器进行管理。另外,还包括发邮件和验证功能,其中验证功能是从web层分离的,由你决定何处执行验证。Spring的ORM可以集成JPA、hibernate和JDO等,比如,使用Hibernate时,可以继续使用已存在的映射文件和标准的Hibernate的SessionFactory配置。表单控制器无缝地把web层和领域模型集成在一起,移除了ActionForms和其它把HTTP参数转换成领域模型的类。
图2.3. 使用第三方web框架的Spring中间件

一些场景可能不允许你完全切换到另一个框架。然而,Spring框架不强制你使用它所有的东西,它不是非此即彼(all-or-nothing)的解决方案。前端使用Struts、Tapestry、JSF或别的UI框架可以和Spring中间件集成,从而使用Spring的事务管理功能。仅仅只需要使用ApplicationContext连接业务逻辑,并使用WebApplicationContext集成web层即可。
图2.4. 远程调用使用场景

当需要通过web服务访问现有代码时,可以使用Spring的Hessian-,Burlap-,Rmi-或者JaxRpcProxyFactory类,远程访问现有的应用并非难事。
图2.5. EJB-包装现有的POJO

Spring框架也为EJB提供了访问抽象层,可以重新使用现有的POJO并把它们包装到无状态的会话bean中,以使其用于可扩展的安全的web应用中。
2.3.1 依赖管理和命名约定
依赖管理和依赖注入是两码事。为了让应用程序拥有这些Spring的非常棒的功能(如依赖注入),需要导入所需的全部jar包,并在运行时放在classpath下,有可能的话编译期也应该放在classpath下。这些依赖并不是被注入的虚拟组件,而是文件系统上典型的物理资源。依赖管理的处理过程涉及到定位这些资源、存储并添加它们到classpath下。依赖可能是直接的(比如运行时依赖于Spring),也可能是间接的(比如依赖于commons-dbcp,commons-dbcp又依赖于commons-pool)。间接的依赖又被称作“传递”,它们是最难识别和管理的。
如果准备使用Spring,则需要拷贝一份所需模块的Spring的jar包。为了便于使用,Spring被打包成一系列的模块以尽可能地减少依赖,比如,如果不是在写一个web应用,那就没必要引入spring-web模块。这篇文档中涉及到的Spring模块,我们使用spring-*或spring-*.jar的命名约定,其中,*代表模块的短名字(比如,spring-core、spring-webmvc、spring-jms等等)。实际使用的jar包正常情况下都是带有版本号的(比如,spring-core-4.3.0.RELEASE.jar)。
每个版本的Spring都会在以下地方发布artifact:
- Maven中央仓库,默认的Maven查询仓库,并且不需要特殊的配置就可以使用。许多Spring依赖的公共库也可以从Maven中央仓库获得,并且大部分的Spring社区也使用Maven作为依赖管理工具,所以很方便。Maven中的jar包命名格式为spring-*-
.jar ,其groupId是org.springframework。 - 特别为托管Spring的公共的Maven仓库。除了最终的GA版本,这个仓库也托管了开发的快照版本和里程碑版本。jar包和Maven中央仓库中的命名一致,所以这也是一个获取Spring的开发版本的有用地方,可以和Maven中央仓库中部署的其它库一起使用。这个仓库也包含了捆绑了所有Spring jar包的发行版的zip文件,以便于下载。
因此,首先要做的事就是决定如何管理依赖关系,我们一般推荐使用自动管理的系统,比如Maven、Gradle或Ivy,当然你也可以手动下载所有的jar包。
下面列出了Spring的artifact,每个模块更完整的描述,参考 2.2 模块 章节。
表2.1. Spring框架的artifact
| groupId | artifactId | 描述 |
|---|---|---|
| org.springframework | spring-aop | 基于代理的AOP |
| org.springframework | spring-aspects | 基于切面的AspectJ |
| org.springframework | spring-beans | bean支持,包括Groovy |
| org.springframework | spring-context | 运行时上下文,包括调度和远程调用抽象 |
| org.springframework | spring-context-support | 包含用于集成第三方库到Spring上下文的类 |
| org.springframework | spring-core | 核心库,被许多其它模块使用 |
| org.springframework | spring-expression | Spring表达式语言 |
| org.springframework | spring-instrument | JVM引导的检测代理 |
| org.springframework | spring-instrument-tomcat | tomcat的检测代理 |
| org.springframework | spring-jdbc | JDBC支持包,包括对数据源设置和JDBC访问支持 |
| org.springframework | spring-jms | JMS支持包,包括发送和接收JMS消息的帮助类 |
| org.springframework | spring-messaging | 消息处理的架构和协议 |
| org.springframework | spring-orm | 对象关系映射,包括对JPA和Hibernate支持 |
| org.springframework | spring-oxm | 对象XML映射 |
| org.springframework | spring-test | 单元测试和集成测试组件 |
| org.springframework | spring-tx | 事务基础,包括对DAO的支持及JCA的集成 |
| org.springframework | spring-web | web支持包,包括客户端及web远程调用 |
| org.springframework | spring-webmvc | REST web服务及web应用的MVC实现 |
| org.springframework | spring-webmvc-portlet | 用于Portlet环境的MVC实现 |
| org.springframework | spring-websocket | WebSocket和SockJS实现,包括对STOMP的支持 |
Spring的依赖和被依赖
Spring对大部分企业和其它外部工具提供了集成和支持,把强制性的外部依赖降到了最低,这样就不需要为了简单地使用Spring而去寻找和下载大量的jar包了。基本的依赖注入只有一个强制性的外部依赖,那就是日志管理(参考下面关于日志管理选项的详细描述)。
下面列出依赖于Spring的应用的基本配置步骤,首先使用Maven,然后Gradle,最后Ivy。在所有案例中,如果有什么不清楚的地方,参考所用的依赖管理系统的文档或查看一些范例代码——Spring构建时本身使用Gradle管理依赖,所以我们的范例大部分使用Gradle或Maven。
Maven依赖关系管理
如果使用Maven作为依赖管理工具,甚至不需要明确地提供日志管理的依赖。例如,创建应用上下文并使用依赖注入配置应用程序,Maven的依赖关系看起来像下面一样:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
就这样,注意如果不需要编译Spring API,可以把scope声明为runtime,这是依赖注入使用的典型案例。
上面的示例使用Maven中央仓库,如果使用Spring的Maven仓库(例如,里程碑或开发快照),需要在Maven配置中指定仓库位置。
release版本:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
里程碑版本:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
快照版本:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Maven的“物料清单式”依赖
使用Maven时可能会不小心混合了Spring不同版本的jar包。例如,你可能会发现第三方库或其它的Spring项目存在旧版本的传递依赖。如果没有明确地声明直接依赖,各种各样不可预料的情况将会出现。
为了解决这个问题,Maven提出了“物料清单式”(BOM)依赖的概念。可以在dependencyManagement部分导入spring-framework-bom以保证所有的Spring依赖(不管直接还是传递依赖)使用相同的版本。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
使用BOM的另外一个好处是不再需要指定
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Gradle依赖关系管理
为了在Gradle构建系统中使用Spring仓库,需要在repositories部分包含合适的URL:
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
可以酌情把repositories URL中的/release修改为/milestone或/snapshot。一旦仓库配置好了,就可以按Gradle的方式声明依赖关系了。
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
Ivy依赖关系管理
使用Ivy管理依赖关系有相似的配置选项。
在ivysettings.xml中添加resolver配置使Ivy指向Spring仓库:
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
可以酌情把root URL中的/release修改为/milestone或/snapshot。一旦配置好了,就可以按照惯例添加依赖了(在ivy.xml中):
- 1
- 2
- 1
- 2
发行版的Zip文件
虽然使用支持依赖管理的构建系统是获取Spring框架的推荐方法,但是也支持通过下载Spring的发行版zip文件获取。
发行版zip文件发布在了Sprng的Maven仓库上(这只是为了方便,不需要额外的Maven或其它构建系统去下载它们)。
浏览器中打开http://repo.spring.io/release/org/springframework/spring,并选择合适版本的子目录,就可以下载发行版的zip文件了。发行文件以-dist.zip结尾,例如,spring-framework-{spring-version}-RELEASE-dist.zip。发行文件也包含里程碑版本和快照版本。
2.3.2 日志管理
对于Spring来说日志管理是非常重要的依赖关系,因为a)它是唯一的强制性外部依赖,b)每个人都喜欢从他们使用的工具看到一些输出,c)Spring集成了许多其它工具,它们都选择了日志管理的依赖。应用程序开发者的目标之一通常是在整个应用程序(包括所有的外部组件)的中心位置统一配置日志管理,这是非常困难的因为现在有很多日志管理的框架可供选择。
Spring中强制的日志管理依赖是Jakarta Commons Logging API(JCL)。我们编译了JCL,并使JCL的Log对象对继承了Spring框架的类可见。对用户来说所有版本的Spring使用相同的日志管理库很重要:迁移很简单因为Spring保存了向后兼容,即使对于扩展了Spring的应用也能向后兼容。我们是怎么做到的呢?我们让Spring的一个模块明确地依赖于commons-logging(JCL的典型实现),然后让所有其它模块都在编译期依赖于这个模块。例如,使用Maven,你想知道哪里依赖了commons-logging,其实是Spring确切地说是其核心模块spring-core依赖了。
commons-logging的优点是不需要其它任何东西就可以使应用程序运转起来。它拥有一个运行时发现算法用于在classpath中寻找其它日志管理框架并且适当地选择一个使用(或者告诉它使用哪个)。如果不需要其它的功能了,你就可以从JDK(java.util.logging或JUL)得到一份看起来很漂亮的日志了。你会发现大多数情况下你的Spring应用程序工作得很好且日志很好地输出到了控制台,这很重要。
不使用Commons Logging
不幸的是,commons-logging的运行时发现算法虽然对于终端用户很方便,但存在一定的问题。如果我们能让时光倒流,重新开始Spring项目,我们会使用不同的日志管理依赖。首要选择可能是Simple Logging Facade for Java(SLF4J),它也被用于了其它一些使用Spring的工具中。
有两种方式关掉commons-logging:
- 从spring-core模块中去除对commons-logging的依赖(因为这是唯一明确依赖于commons-logging的地方)
- 依赖于一个特定的commons-logging且把其jar包换成一个空jar包(具体做法参考SLF4J FAQ)
如下,在dependencyManagement中添加部分代码就可以排除掉commons-logging了:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
现在这个应用可能是残缺的,因为在classpath上没有JCL API的实现,所以需要提供一个新的去修复它。下个章节我们将以SLF4J为例子为JCL提供一个替代实现。
使用SLF4J
SLF4J是一个更干净的依赖,且运行时比commons-logging更有效率,因为它使用编译期而非运行时绑定其它日志管理框架。这也意味着你不得不明确地指出运行时想做什么,并定义和配置它。SLF4J可以绑定许多公共的日志管理框架,所以通常你可以选择一个已经使用的,绑定它并配置和管理。
SLF4J可以绑定许多公共的日志管理框架,包括JCL,同时也是其它日志管理框架和它本身的桥梁。所以为了在Spring中使用SLF4J,需要用SLF4J-JCL桥梁代替commons-logging依赖。一旦这样做了然后日志记录从Spring内部调用转变成调用SLF4J API,因此,如果应用中的其它库使用了这个API,然后将有一个统一的地方用于配置和管理日志。
通常的选择是把Spring桥接到SLF4J,然后从SLF4J到Log4J提供明确的绑定。需要提供4个依赖关系(且排除掉commons-logging):桥梁、SLF4J API、绑定到Log4J和Log4J的实现本身。在Maven中看起来像下面一样:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
似乎这么多依赖仅仅用于获取日志。在类加载器问题上,它应该表现得比commons-logging更好,尤其是在像OSGi这样严格的容器中。而且,它也有性能优势因为绑定发生在编译期而非运行时。
对于SLF4J用户更普遍的选择是直接绑定Logback,这需要更少的步骤,生成更少的依赖。这样移除了额外的绑定因为Logback直接实现了SLF4J,所以仅仅需要两个库即可而不用四个库(jcl-over-slf4j和logback)。这样做的话还需要把slf4j-api依赖从其它外部依赖(不是Spring)中排除掉,因为在classpath下仅仅需要一个版本的API。
使用Log4J
许多人使用Log4J作为日志管理框架。它是高效和完善的,实际上在构建和测试Spring的时候我们运行时就是使用它。Spring也提供了一些工具用于配置和初始化Log4J,所以某些模块在编译期可以选择依赖于Log4J。
为了使Log4J代替默认的JCL依赖(commons-logging),仅仅提供一个配置文件(log4j.properties或log4j.xml)放在classpath根目录下即可。Maven中的配置如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
下面是log4j.properties的样例,用于打印日志到控制台:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
带有本地JCL的运行时容器
许多人在一个容器中运行Spring应用程序,而这个容器本身又提供了JCL的实现。IBM的Websphere Application Server(WAS)是一个原型。这经常引起一些问题,而且不幸的是没有很好的解决方案,简单地从应用中排除掉commons-logging在大部分情况下还不够。
更清楚地描述:这个问题通常并不与JCL本身有关,甚至是commons-logging,而是他们绑定了commons-logging到另一个框架(通常是Log4J)。这会失败是因为commons-logging改变了在旧版本(1.0)和新版本(1.1)中执行运行时发现算法的方式,其中,旧版本在一些容器中还在使用,新版本是现在大部分人使用的。Spring没有使用JCL API的其它部分,所以不会有什么问题,但是一旦Spring或你的应用试图记录日志就会发现Log4J不能工作了。(译者注:此处的意思是即使发生了上面的冲突,Spring也不会去检查,直接运行的时候需要打印日志的时候才会出错)
在WAS这个案例中,最简单的方法就是倒置类加载器的继承(IBM称作“parent last”,即把父类放后面),以便应用程序而不是容器控制JCL依赖。这种选择并不总是管用的,在公共领域有很多其它建议的替代方案,且你的里程可能会随着确切的版本和容器的特性而改变。(译者注:此处的意思是上面介绍的方法并不是唯一的,需要根据不同的版本和容器作出相应的方案)
二、Spring 4.x中的新特性
3. Spring 4.0的新特性和增强功能
Spring最初发行于2004年,从那以后有过几次重大的修改,Spring 2.0提供了XML命名空间和AspectJ,Spring 2.5包含了注解驱动的配置,Spring 3.0以Java 5+为框架的代码基础,并使用其新特性,诸如以@Configuration注解的模型等。
4.0版本是最近一次重大的修改,且首次全面支持Java 8的新特性。你仍然可以继续使用Java的旧版本,但是最低要求提升到了Java SE 6。我们也利用这次重大修改移除了很多过时的类和方法。
升级到Spring 4.0的指导手册参见Spring Framework GigHub Wiki。
3.1 改进了入门体验
新的spring.io网址提供了完整的入门指南帮你学习Spring。更多的指南请参考本文档的 1. Spring入门。新网址也提供了对发布在Spring下的许多项目的深入理解。
如果你是Maven用户,你可能会对现在发布在每个Spring版本中的物料清单POM文件感兴趣。
3.2 移除了过时的包和方法
4.0版本移除了所有过时的包以及许多过时的类和方法。如果从之前的版本升级过来,则需要保证修复所有对过时API的调用。
完整的改变请参考API Differences Report。
注意,可选的第三方依赖已经升级到2010/2011的版本(也就是说,Spring 4只支持发布在2010年之后的版本),尤其是,Hibernate 3.6+,EhCache 2.1+,Quartz 1.8+,Groovy 1.8+,Joda-Time 2.0+。有一个例外,Spring 4需要Hibernate Validator 4.3+和Jackson2.0+(Spring 3.2保留了对Jackson1.8/1.9的支持,但现在过时了)。
3.3 Java 8(以及6和7)
Spring 4.0对Java 8的几个新特性提供了支持,允许使用lambda表达式,在Spring回调接口中使用方法引用。对java.time(JSR-310)有很好地支持,把几个已存在的注解改造为@Repeatable,还可以使用java 8的参数名称发现作为替代方案来编译启用了调试信息的代码(基于-parameters的编译器标志,译者注:参数名称发现是通过反射获取参数的名称,而不是类型)。
Spring保留了对旧版本Java和JDK的兼容,具体地说是Java SE 6和更高版本都全面支持(最低JDK6.18,发布于2010年1月)。尽管如此,我们依然建议基于Spring 4的新项目使用Java 7或者8。
3.4 Java EE 6和7
Java EE 6+及其相关的JPA 2.0和Servlet 3.0,被认为是Spring 4的基线。为了兼容Google App Engine和旧的应用服务器,可能要在Servlet 2.5环境中部署Spring 4。然而,Servlet 3.0+是我们强烈推荐的,并且它也是Spring测试的先决条件,也是模拟软件包测试开发环境设置的先决条件。
如果你是WebSphere 7用户,请一定要安装JPA 2.0包,如果是WebLogic 10.3.4或更高版本,还要安装JPA 2.0补丁,这样Spring 4才能兼容这两个服务器。
更有远见的主意,Spring 4.0现在支持Java EE 7适用的规范,尤其是JMS 2.0、JTA 1.2、JPA 2.1、Bean Validation 1.1和JSR-236 Concurrency Utilities。像往常一样,这种支持只针对个人的使用,比如在Tomcat或独立的环境中。尽管如此,当Spring应用部署在Java EE 7的服务器上依然运行良好。
注意,Hibernate 4.3是JPA 2.1的提供者,因此只在Spring 4.0中支持。同样地,Hibernate Validator 5.0是Bean Validation 1.1的提供者。因此,这两项并不被Spring 3.2官方支持。
3.5 Groovy Bean定义DSL
从Spring 4.0开始,可以使用Groovy DSL定义外部bean了。在概念上,这与使用XML配置bean类似,但是可以使用更简洁的语法。使用Groovy还可以很容易地把bean定义直接嵌入到引导代码中。例如:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
更多信息请查阅GroovyBeanDefinitionReader的javadocs。
3.6 核心容器的改进
核心容器有以下几点改进:
- Spring注入Bean时把泛型当作一种限定符。例如,使用Spring的Repository时,可以注入特定的实现:
@Autowired RepositorycustomerRepository 。 - 使用Spring的元注解,可以开发暴露特定属性的自定义注解。
- Bean可以在被装配到list或数组中时排好序。通过@Order注解和Ordered接口支持。
- @Lazy注解可以用于注入点,也可用于@Bean定义上。
- 引入了@Description注解以便开发者使用基于Java的配置。
- 通过@Conditional注解可以定义有条件过滤的bean。这与@Profile类似但允许用户自定义开发策略。
- 基于CGLIB的代理类不再需要默认的构造方法。通过objenesis库进行支持,它被重新打包到Spring中并作为Spring框架的一部分发布。使用这种策略,生成代理实例时没有构造方法将被调用。
- 添加了管理时区的支持。例如LocaleContext。
3.7 Web的改进
保留了Servlet 2.5服务器的部署,但Spring 4.0现在主要关注Servlet 3.0+环境的部署。如果使用Spring MVC测试框架,需要保证在test classpath上包含Servlet 3.0的兼容JAR包。
除了下面要讲的WebSocket方面的支持,在Spring的Web模块还包含以下几点改进:
- 可以添加新的@RestController注解到Spring MVC应用上,而不用再添加@ResponseBody到每个@RequestMapping方法上。
- 添加了AsyncRestTemplate类,当开发REST客户端时允许非阻塞异步支持。
- 当开发Spring MVC应用时提供了全面的时区支持。
3.8 WebSocket、SockJS 和STOMP Messaging
新的spring-websocket模块全面支持在web应用中客户端与服务端基于WebSocket双向通信。它兼容JSR-356、Java WebSocket API,另外还提供了基于SockJS的后退选项(例如,WebSocket仿真)用于不支持WebSocket协议的浏览器(例如,IE < 10)。
新的spring-messaging模块支持STOMP作为WebSocket的子协议与一个注解程序模型一起用于路由并处理来自WebSocket客户端的STOMP消息。因此,一个@Controller可以同时包含@RequestMapping和@MessageMapping方法用于处理HTTP请求和来自WebSocket客户端的消息。新的spring-messaging模块还包含从以前Spring集成项目提取出来的关键抽象作为基于消息处理的应用的基础,如Message、MessageChannel、MesaageHandler等。
更详细的内容请参考 25 WebSocket支持 章节。
3.9 测试的改进
除了移除了spring-test模块过时的代码,Spring 4.0还引入了几个新特性用于单元测试和集成测试:
- 几乎spring-test模块的所有注解(例如,@ContextConfiguration、@WebAppConfiguration、@ContextHierarchy、@ActiveProfiles等)都可以作为元注解用于创建自定义注解并减少测试套件中的重复配置。
- 有效的bean定义配置文件可以通过编程解析,只要简单地实现自定义的ActiveProfilesResolver并注册@ActiveProfiles的resolver属性即可。
- spring-core模块引入了新的SocketUtils类,用于扫描本地空闲的TCP和UDP服务端口。这项功能并不特定用于测试,但是当写需要socket的集成测试时非常有用,例如,启动内存中的SMTP服务器、FTP服务器、Servlet容器等的测试。
- 自Spring 4.0起,org.springframework.mock.web包中模拟集合以Servlet 3.0为基础。此外,一些Servlet API模拟(例如,MockHttpServletRequest,MockServletContext等)有少许增强并可通过配置改进。
4. Spring 4.1的新特性和增强功能
4.1 JMS的改进
Spring 4.1引入了一个更简单的方法来注册JMS监听器,那就是使用@JmsListener注解bean的方法。XML的命名空间也得到了增强以支持这项新特性(jms:annotation-driven),也可以通过Java配置来完全使用这项新特性(@EnableJms,JmsListenerContainerFactory),还可以使用JmsListenerConfigurer来编程式地注册监听器。
Spring 4.1还可以与4.0中引入的spring-messaging合作使用:
- 消息监听器可以拥有更弹性的签名,并且可以受益于标准的消息处理注解,比如,@Payload, @Header, @Headers, @SendTo,等等,也可以使用标准的Message代替javax.jms.Message作为方法的参数。
- 新的JmsMessageOperation接口可以被使用,并且允许JmsTemplate像使用Message一样操作。
最后,Spring 4.1还提供了以下各种各样的改进:
- JmsTemplate支持同步的请求应答操作。
- 每个
- 通过BackOff实现可以配置消息监听容器的恢复选项。
- JMS 2.0支持共享消费者。
4.2 缓存的改进
Spring 4.1支持JCache(JSR-107)注解,直接使用Spring已存在的缓存配置和基础架构即可,不需要其它的改变。
Spring 4.1也极大地改进了它的缓存策略:
- 可以在运行时使用CacheResolver解析缓存。因此,不再强制使用value参数来定义缓存的名称。
- 更多自定义的操作:缓存解析,缓存管理,键生成器。
- 新的@CacheConfig注解允许通用设置在类级别共享,而不需要启用任何缓存操作。
- 使用CacheErrorHandler更好地处理缓存的异常。
Spring 4.1还为了添加putIfAbsent方法对CacheInterface做了重大改变。
4.3 Web的改进
- 新的抽象ResourceResolver, ResourceTransformer和ResourceUrlProvider扩展了已存在的基于ResourceHttpRequestHandler的资源处理程序。一些内置的实现提供了对带版本的资源URL(为了有效的HTTP缓存)、定位gzip资源、生成HTML 5 AppCache清单等的支持。参考21.16.9 资源服务。
- JDK 1.8的java.util.Optional现在支持@RequestParam, @RequestHeader和@MatrixVariable控制器方法的参数。
- ListenableFuture作为返回值替代了DeferredResult,在这方面一项基础服务(或者说对AsyncRestTemplate的调用)已经返回了ListenableFuture。
- @ModelAttribute方法现在按照依赖间的顺序依次被调用。
- Jackson的@JsonView直接作用于@ResponseBody和ResponseEntity控制器方法,用于序列化同一个POJO的不同形式(比如,汇总和详情)。这可以通过为模型属性添加指定key的序列化视图类型来渲染视图。参考Jackson序列化视图支持。
- Jackson现在支持JSONP。参考Jackson JSONP支持。
- 新的生命周期选项可用于在控制器方法返回后且响应写出前拦截@ResponseBody和ResponseEntity方法,声明一个@ControllerAdvice bean实现ResponseBodyAdvice即可,内置的@JsonView和JSONP恰恰利用了这点。参考21.4.1 使用HandlerInterceptor拦截请求。
- 有三个HttpMessageConverter选项:
- Gson——比Jackson更轻的足迹,已用于Spring Android中。
- Google协议缓冲——企业内部有效的服务间通信数据协议,但是也可以作为JSON和XML暴露于浏览器中。
- 通过jackson-dataformat-xml扩展支持基于XML的Jackson。当使用@EnableWebMvc或
- 类似JSP的视图现在可以通过引用控制器映射的名称与控制器建立链接。默认的名称将被赋给每一个@RequestMapping。例如,FooController拥有方法handleFoo,它的名称为“FC#handleFoo”。命名策略是可插拔的,也可以通过name属性为@RequestMapping明确地命名。在Spring JSP标签库中新的mvcUrl功能可以让使用JSP页面变得更方便。参考21.7.2 从视图为Controller及其方法创建URI。
- ResponseEntity提供了创建者风格的API用于引导控制器方法为服务端响应做准备。例如,ResponseEntity.ok()。
- RequestEntity是一种新类型,它提供了创建者风格的API用于引导客户端REST代码为HTTP请求做准备。
- MVC Java配置与XML命名空间:
- 视图解析器可以被配置,包含对内容协商的支持。参考21.16.8 视图解析器。
- 视图控制器内置了对重定向及设置响应状态的支持。应用程序可以使用它配置重定向的URL,用视图渲染 404 响应,发送“无内容”响应,等等。一些用例请点击这里。
- 内置了自定义的路径匹配。参考21.16.11 路径匹配。
- 支持Groovy标记模板(基于Groovy 2.3)。参考GroovyMarkupConfigurer和各自的ViewResolver及视图实现 。
4.4 WebSocket 消息处理的改进
- 支持SockJS(Java)客户端。参考SockJsClient和同包下的类。
- 当STOMP客户端订阅和取消订阅时新的应用上下文事件SessionSubscribeEvent和SessionUnsubscribeEvent会被触发。
- 新的作用域“websocket”。参考25.4.14 WebSocket作用域。
- @SendToUser只能把单会话作为目标,而且不需要用户身份验证。
- @MessageMapping方法可以使用点“.”代替斜杠“/”作为分割符。参考SPR-11660。
- STOMP/WebSocket监测信息收集和日志管理。参考25.4.16 运行时监测。
- 得到极大优化和改进的日志管理保留了可读性和简洁性,甚至是在DEBUG水平。
- 优化了消息的创建,包含了对临时消息可变性的支持,并避免自动消息id和时间戳的创建。参考Javadoc中的MessageHeaderAccessor。
- 在WebSocket会话创建60秒后没有活动则将会关闭STOMP/WebSocket连接。参考SPR-11884。
4.5 测试的改进
- Groovy脚本现在可用于配置ApplicationContext,其中ApplicationContext在测试上下文框架中被加载用于集成测试。参考带有Groovy脚本的上下文配置。
- 在事务测试方法中可以通过TestTransaction API编程式地开始和结束测试事务。参考编程式事务管理。
- SQL脚本执行可以通过在每个类或方法上添加新的@Sql和@SqlConfig注解声明式地配置。参考14.5.7执行SQL脚本。
- 可以通过新的@TestPropertySource注解配置用于测试的property源文件,它能够自动地重写系统和应用的property源文件。参考带有测试property源文件的上下文配置。
- 默认的TestExecutionListeners能够被自动地发现。参考自动发现默认的TestExecutionListeners。
- 自定义的TestExecutionListeners能够被自动地合并到默认的监听器中。参考合并TestExecutionListeners。
- 测试上下文框架中事务测试的文档提供了更多深入的解释和附加的案例。参考14.5.6 事务管理。
- 对MockServletContext, MockHttpServletRequest和其它Servlet API模拟的各种各样的改进。
- AssertThrows被重构了用于支持Throwable而不是Exception。
- 在Spring MVC测试中,JSON Assert作为使用JSONPath的额外选项,可以为JSON响应断言,这就像使用XMLUnit为XML断言一样。
- 可以通过MockMvcConfigurer创建MockMvcBuilder。这使得应用Spring安全设置变得很容易,也可用于把通用设置压缩进任何第三方框架或项目中。
- MockRestServiceServer现在支持AsyncRestTemplate用于客户端测试。
5. Spring 4.2的新特性和增强功能
5.1 核心容器的改进
- 类似@Bean的注解被发现并用于处理Java 8的默认方法,允许实现接口的配置类带有默认的@Bean方法。(译者注:@Bean注解可以用到Java 8接口的默认方法上,然后配置类实现这个接口一样可以得到bean)
- 配置类现在可以声明@Import引入普通的组件类了,允许混合引入配置类和组件类。(译者注:@Import以前只能引入配置类,现在也可以引入没有任何注解的组件类)
- 配置类可以声明一个@Order值,按照一定的顺序处理(比如,按名称重写bean),甚至是在classpath扫描的时候。(译者注:@Order值大的会覆盖小的)
- @Resource注入的元素支持@Lazy声明,像@Autowired一样,对请求目标的bean接受延迟初始化的代理。
- 应用程序事件现在提供基于注解的模型了,也可以发布任何事件。
- bean中的任何公共方法都能够通过@EventListener注解来消费事件。
- @TransactionalEventListener提供了事务绑定的事件支持。
-
Spring 4.2提供了一流的支持用于声明和查找注解属性的别名。新的@AliasFor注解可以用来在单个注解内声明一对别名属性,或者声明一个从自定义注解属性到元注解属性的别名。
- 以下注解都通过@AliasFor翻新过了,以便为value属性提供更有意义的别名:@Cacheable, @CacheEvict, @CachePut, @ComponentScan, @ComponentScan.Filter, @ImportResource, @Scope, @ManagedResource, @Header, @Payload, @SendToUser, @ActiveProfiles, @ContextConfiguration, @Sql, @TestExecutionListeners, @TestPropertySource, @Transactional, @ControllerAdvice, @CookieValue, @CrossOrigin, @MatrixVariable, @RequestHeader, @RequestMapping, @RequestParam, @RequestPart, @ResponseStatus, @SessionAttributes, @ActionMapping, @RenderMapping, @EventListener, @TransactionalEventListener。
-
例如,来自spring-test模块的@ContextConfiguration现在定义如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-
类似地,重写了元注解属性的注解现在也可以使用@AliasFor细粒度地控制那些在注解层次结构中被重写的属性。实际上,现在可以为元注解的value属性声明一个别名。
-
例如,现在可以像下面一样开发一种重写了自定义属性的组合注解。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
参考Spring注解编程模型。
- Spring在发现元注解的搜索算法上做了很多改进。例如,在注解继承体系中可以声明局部的组合注解。
- 重写了元注解属性的组合注解现在可以用在接口、抽象类、桥接和接口方法上,也可以用在类、标准方法、构造方法和字段上。
- 代表注解属性的Map(和AnnotationsAttributes实例)可以被合成(或者转换)到一个注解中。
- 基于字段的数据绑定(DirectFieldAccessor)可以与当前基于属性的数据绑定(BeanWrapper)一起使用。特别地,基于字段的绑定现在支持为集合、数据和Map导航。
- DefaultConversionService为Steam、Charset、Currency和TimeZone提供了可以直接使用的转换器。这些转换器也可以被添加到任意的ConversionService中。
- DefaultFormattingConversionService为JSR-354中的货币提供了支持(如果javax.money存在于classpath下),即MonetaryAmount和CurrencyUnit。这也包含对@NumberFormat的支持。
- @NumberFormat现在可以作为元注解使用。
- JavaMailSenderImpl有一个新的方法testConnection()用于检查与服务器间的连接。
- ScheduledTaskRegistrar暴露计划的任务。
- Apache的commons-pool2现在支持AOP池CommonsPool2TargetSource。
- 为脚本化bean引入了StandardScriptFactory作为一个基于JSR-223的机制,暴露于XML中的lang:std元素。对JavaScript和JRuby的支持。(注意:JRubyScriptFactory和lang:jruby现在过时了,请使用JSR-223)
5.2 数据访问的改进
- AspectJ现在支持javax.transactional.Transactional。
- SimpleJdbcCallOperations现在支持命名绑定。
- 全面支持Hibernate ORM 5.0,作为JPA提供者(自动适配),也支持其原生API(被新的org.springframework.orm.hibernate5包覆盖)。
- 嵌入的数据库现在可以被自动赋值不同的(unique)名字,且
5.3 JMS的改进
- autoStartup属性可以通过JmsListenerContainerFactory控制。
- 每个监听器容器都能配置应答Destination的类型。
- @SendTo注解的值现在可以使用SpEL表达式。
- 响应目标可以使用JmsResponse在运行时计算。
- @JmsListener是一个可重复性的注解,可以在同一个方法上声明多个JMS容器(如果你还没有使用Java 8,请使用新引入的@JmsListeners)。
5.4 Web的改进
- 支持HTTP流和服务器发送事件。参考HTTP流。
- 支持内置CORS的全局(MVC Java配置和XML命名空间)和局部(例如,@CrossOrign)配置。参考26 CORS支持。
- HTTP缓存更新:
- 新的创建者CacheControl,嵌入到ResponseEntity, WebContentGenerator, ResourceHttpRequestHandler中。
- 在WebRequest中改进了ETag/Last-Modified的支持。
- 自定义映射注解,使用@RequestMapping作为元注解。
- AbstractHandlerMethodMapping中的公共方法用于在运行时注册和取消注册请求映射。
- AbstractDispatcherServletInitializer中的保护方法createDispatcherServlet进一步自定义DispatcherServlet的实例。
- HandlerMethod作为@ExceptionHandler方法的参数,特别在@ControllerAdvice组件中非常便利。
- java.util.concurrent.CompletableFuture作为@Controller方法的返回类型。
- HttpHeaders支持字节范围的请求,并提供静态资源。
- @ResponseStatus检测嵌套异常。
- RestTemplate中的UriTemplateHandler扩展点。
- DefaultUriTemplateHandler暴露了baseUrl属性和路径段编码选项。
- 此扩展点可嵌入到URI模板库中。
- OkHTTP与RestTemplate集成。
- 自定义的baseUrl可以替代MvcUriComponentsBuilder中的方法。
- 序列化/反序列化的异常信息在WARN级别被记录。
- 默认的JSON前缀从“{}&&”改成了更安全的”)]}’,”中的一个(译者注:此处可能官方文档有误)。
- 新的扩展点RequestBodyAdvice和内置实现支持@RequestBody方法参数上的Jackson的@JsonView。
- 使用GSON或Jackson 2.6+时,处理器方法的返回类型被用于改进参数化类型的序列化,比如List
。 - 引入了ScriptTemplateView作为JSR-223用于处理脚本web视图的机制,主要关注于Nashorn(JDK 8)上的JavaScript视图模板。
5.5 WebSocket消息处理的改进
- 暴露关于已连接用户和订阅存在的信息。
- 新的SimpUserRegistry暴露为叫作“userRegistry”的bean。
- 在服务器集群间共享已存在的信息(参考代理中继配置选项)。
- 解决用户在服务器集群中的目的地(参考代理中继配置选项)。
- StompSubProtocolErrorHandler扩展点用来定制和控制STOMP错误帧到客户端。
- 通过@ControllerAdvice组件声明的全局方法@MessageExceptionHandler。
- SpEL表达式“selector”头用于SimpleBrokerMessageHandler的订阅。
- 通过TCP和WebSocket使用STOMP客户端。参考25.4.13 STOMP客户端。
- @SendTo和@SendToUser可以包含多个占位符。
- Jackson的@JsonView支持在@MessageMapping和@SubscribeMapping方法上返回值。
- ListenableFuture和CompletableFuture可以作为@MessageMapping和@SubscribeMapping方法的返回值类型。
- MarshallingMessageConverter用于XML负载。
5.6 测试的改进
- 基于JUnit的集成测试现在可以使用JUnit规则执行而不是SpringJUnit4ClassRunner。这使得基于Spring的集成测试可以使用替代runner运行,比如JUnit的Parameterized或第三方的runner如MockitoJUnitRunner。参考Spring JUnit规则。
- Spring MVC测试框架现在对HtmlUnit提供了一流的支持,包括集成Selenium的WebDriver,允许基于页面的web应用测试不再需要部署到一个Servlet容器上。参考14.6.2, HtmlUnit的集成。
- AopTestUtils是一个新的测试工具类,它允许开发者可以获取到底层的隐藏在一个或多个Spring代理类下的目标对象。参考13.2.1 通用测试工具类。
- ReflectionTestUtils现在支持为static字段设值和取值,包括常量。
- 通过@ActiveProfiles声明的bean定义配置文件的原始顺序现在保留了,这是为了使用一些案例,比如Spring Boot的ConfigFileApplicationListener,它通过有效的名称来加载配置文件。
- @DirtiesContext现在支持新的模式BEFORE_METHOD, BEFORE_CLASS和BEFORE_EACH_TEST_METHOD用于在测试之前关闭ApplicationContext——例如,在大型测试套件中的一些劣质的测试毁坏了对ApplicationContext的原始配置。
- @Commit这个新注解可以直接替代@Rollback(false)。
- @Rollback现在可以用来配置类级别默认的回滚语义。
- 因此,@TransactionConfiguration现在过时了,并且会在后续版本中移除。
- 通过statements这个新的属性@Sql现在支持内联SQL语句的执行。
- 用于在测试期间缓存应用上下文的ContextCache现在是公共的API,它有默认的实现,可以替代自定义的缓存需求。
- DefaultTestContext, DefaultBootstrapContext和DefaultCacheAwareContextLoaderDelegate现在是support子包下的公共类,允许自定义扩展。
- TestContextBootstrappers现在负责创建TestContext。
- 在Spring MVC测试框架中,MvcResult的详细日志现在可以在DEBUG级别被打印,或者写出到自定义的OutputStream或Writer中。参考MockMvcResultHanlder中的新方法log(), print(OutputStream)和print(Writer)。
- JDBC XML的命名空间支持一个新的属性database-name,位于
- 嵌入的数据库现在可以被自动赋予不同的名字,允许在同一测试套件不同的应用上下文中重复使用通用的测试数据库配置。参考18.8.6 为嵌入的数据库生成不同的名字。
- MockHttpServletRequest和MockHttpServletResponse现在通过getDateHeader和setDateHeader方法提供了更好的支持用于格式化日期头。
6. Spring 4.3的新特性和增强功能
6.1 核心容器的改进
- 核心容器提供了更丰富的元数据用于编程式评估。
- Java8的默认方法可以作为bean属性的getter/setter方法被检测。
- 如果目标bean仅仅定义了一个构造方法,就不必指定@Autowired注解了。
- @Configuration类支持构造方法注入。
- 任何用于指定@EventLIstener条件的SpEL表达式现在可以引用bean了(例如,@beanName.method())。
- 组合注解现在可以重写元注解的数组属性。例如,@RequestMapping的String[] path可以使用组合注解的String path重写。
- @Scheduled和@Schedules可以作为元注解,用来创造组合注解并可重写其属性。
- @Scheduled支持任何作用域的bean。
6.2 数据访问的改进
- jdbc:initialize-database和jdbc:embedded-database支持一个可配置的分隔符应用于任何脚本。
6.3 缓存的改进
spring 4.3 允许并发调用给定的key,从而使得值只被计算一次。这是一项可选功能,通过@Cacheable的新属性sync启用。这项功能也使Cache接口做了重大改变,增加了get(Object key, Callable
spring 4.3 也改进了以下缓存方面的内容:
- 缓存相关的注解中的SpEL表达式现在可以引用bean了(比如,@beanName.method())。
- ConcurrentMapCacheManager和ConcurrentMapCache现在可以通过新的属性storeByValue序列化缓存的entry。
- @Cacheable, @CacheEvict, @CachePut和@Caching现在可以作为元注解,用来创造组合注解并可重写其属性。
6.4 JMS的改进
- @SendTo现在可应用于类级别上,以便共享共同的目标。
- @JmsListener和@JmsListeners现在可作为元注解,用来创造组合注解并可重写其属性。
6.5 Web的改进
- 内置了对Http头和Http选项的支持。
- 新的组合注解@GetMapping, @PostMapping, @PutMapping, @DeleteMapping和@PatchMapping,它们来源于@RequestMapping。
- 参考@RequestMapping的变种。
- 新的组合注解@RequestScope, @SessionScope和@ApplicationScope用于web作用域。
- 参考Request scope, Session scope和Application scope。
- 新的注解@RestControllerAdvice,它是@ControllerAdvice和@ResponseBody的组合体。
- @ResponseStatus现在可用于类级别并可以被所有方法继承。
- 新的@SessionAttribute注解用于访问session的属性。
- 新的@RequestAttribute注解用于访问request的属性。
- @ModelAttribute可以设置其属性binding=false阻止数据绑定。
- 错误和自定义的异常可一致地暴露给MVC的异常处理器。
- Http消息转换器中一致地处理字符集,默认地使用UTF-8处理多部分文本内容。
- 使用已配置的ContentNegotiationManager处理媒体类型等静态资源。
- RestTemplate和AsyncRestTemplate可通过DefaultUriTemplateHandler支持严格的URI编码。
- AsyncRestTemplate支持请求拦截。
6.6 WebSocket消息处理的改进
- @SendTo和@SendToUser现在可应用于类级别上,以便共享共同的目标。
6.7 测试的改进
- spring测试上下文中的JUnit现在需要 4.12 及其更高版本。
- SpringJUnit4ClassRunner的新别名SpringRunner。
- 测试相关的注解现在可用于接口上,从而可以使用Java 8 中接口的默认方法。
- 空声明的@ContextConfiguration现在可以完全省略了,如果默认的XML文件、Groovy脚本或@Configuration类被检测到。
- @Transactional测试方法不再必需是public了(例如,在TestNG和JUnit 5 中)。
- @BeforeTransaction和AfterTransaction方法不再必需是public了,并且现在也可能用在Java 8 接口的默认方法上。
- spring测试上下文中的ApplicationContext缓存现在是有界的,默认最大值为32,并按最近最少原则回收。其最大值可以通过JVM的系统属性或spring的属性spring.test.context.cache.maxSize进行设置。
- 用于自定义测试ApplicationContext的新API ContextCustomizer在bean定义之后且上下文刷新之前被加载到上下文中。Customizer可以通过第三方注册,但需要实现自定义的ContextLoader。
- @Sql和@SqlGroup现在可作为元注解,用来创造组合注解并可重写其属性。
- ReflectionTestUtils现在会自动解除代理当set或get一个字段时。
- 服务器端的springmvc测试支持响应头带有多个值。
- 服务器端的springmvc测试解析表单数据请求内容并填充请求参数。
- 服务器端的springmvc测试支持对已调用的处理器方法模拟断言。
- 客户端的REST测试允许指明希望发送多少次请求并决定是否请求的顺序可被忽略。
- 客户端的REST测试支持在请求体中添加表单数据。
6.8 支持新库和服务器
- Hibernate ORM 5.2(仍然能很好地支持4.2/4.3和5.0/5.1,但是3.6已经过时了)
- Jackson 2.8(至少需要2.6以上版本)
- OkHttp 3.x(同时仍然支持OkHttp 2.x)
- Netty 4.1
- Undertow 1.4
- Tomcat 8.5.2 及 9.0 M6
另外,spring 4.3的spring-core.jar中集成了更新的ASM 5.1和Objenesis 2.4。
三、核心技术
这部分的文档覆盖了spring完整的技术。
在这些技术中最重要的要属Spring的控制反转(IoC)容器了,紧随其后的是全面覆盖的面向切面编程(AOP)技术。Spring有它自己的AOP框架,它很容易理解,而且成功解决了Java企业编程中80%的AOP需求。
Spring也集成了AspectsJ(目前在Java领域使用最丰富最成熟的AOP实现 )。
- 7. IoC容器
- 8. 资源
- 9. 数据检验、数据绑定、类型转换
- 10. Spring表达式语言
- 11. Spring的面向切面编程
- 12. Spring AOP的API
7. IoC容器
7.1 Spring的IoC容器和bean的简介
本章主要介绍Spring关于控制反转的实现。控制反转(IoC)又被称作依赖注入(DI)。它是一个对象定义其依赖的过程,它的依赖也就是与它一起合作的其它对象,这个过程只能通过构造方法参数、工厂方法参数、或者被构造或从工厂方法返回后通过settter方法设置其属性来实现。然后容器在创建bean时注入这些依赖关系。这个过程本质上是反过来的,由bean本身控制实例化,或者直接通过类的结构或Service定位器模式定位它自己的依赖,因此得其名曰控制反转。
org.springframework.beans和org.springframework.context两个包是Spring IoC容器的基础。BeanFactory接口提供了一种先进的管理任何类型对象的配置机制。ApplicationContext是BeanFactory的子接口,它使得与Spring AOP特性集成更简单,添加了消息资源处理(用于国际化)、事件发布,还添加了应用层特定的上下文,比如用于web应用的WebApplicationContext。
简而言之,BeanFactory提供了配置框架和基础功能,ApplicationContext在此基础上添加了更多的企业级特定功能。ApplicationContext是BeanFactory的完整超集,且仅用于本章描述Spring的IoC容器。更多使用BeanFactory代替ApplicationContext的信息请参考7.16 BeanFactory“。
在Spring中,形成应用主干且被Spring IoC容器管理的对象称为beans。一个bean就是被Spring IoC容器实例化、装配和管理的对象。简单来说,一个bean就是你的应用中众多对象中一个。Beans和它们之间的依赖被容器中配置的元数据反射。
7.2 容器概述
org.springframework.context.ApplicationContext代表了Spring的IoC容器,并且负责实例化、配置和装配前面提及的bean。容器通过读取配置元数据获取指令来决定哪些对象将被实例化、配置和装配。配置元数据反映在XML、Java注解或者Java代码中。它允许你表达组合成应用的对象及它们之间丰富的依赖关系。
Spring提供了几个可以直接使用的ApplicationContext接口的实现。在独立的应用中通常创建ClassPathXmlApplicationContext或者FileSystemXmlApplicationContext的实例。XML是定义配置元数据的传统形式,也可以通过添加一小段XML配置让容器声明式地支持Java注解或Java代码配置元数据的形式。
在大部分应用场景中,显式的代码不需要实例化一个或多个Spring IoC容器。例如,在web应用中,在web.xml中引用简单的八行(大约)样板XML描述符足够了(参考7.15.4 web应用中方便地实例化ApplicationContext](#context-create))。如果使用Spring工具套件Eclipse开发环境,样板配置只需要简单地点击几次鼠标或键盘就可以被创建。
下面的图表展示了Spring是怎么工作的。应用程序的类文件和配置元数据是绑定在一起的,所以在ApplicationContext被创建和初始化后,你将拥有完整的已配置好的和可执行的系统或应用。
图7.1 Spring的IoC容器
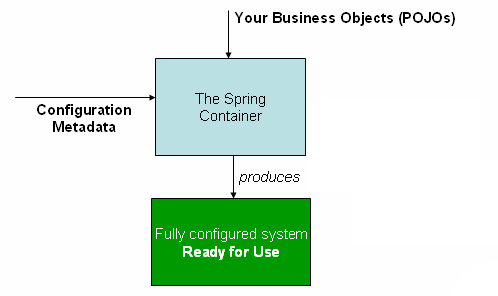
7.2.1 配置元数据
如前述图表所述,Spring IoC容器是消费配置元数据的一种形式,配置元数据代表开发者告诉Spring容器怎么去实例化、配置和装配应用中的对象。
配置元数据习惯上使用简单直观的XML形式,本章大部分地方也使用这种形式来传达Spring IoC容器的关键概念和特性。
- 基于XML的元数据不是配置元数据的唯一方式,Spring IoC容器本身是与实际写配置元数据的形式完全解耦的,现在许多开发者选择基于Java的配置形式来配置Spring应用程序。
关于使用其它形式配置元数据,参考:
- 基于注解的配置,Spring 2.5引入了基于注解配置元数据的形式。
- 基于Java的配置,从Spring 3.0开始,Spring JavaConfig项目提供的许多特性成为了Spring框架核心的一部分。因引,可以在应用程序类的外部通过Java定义bean而不是在XML文件中。使用这些新特性,请参考@Configuration, @Bean, @Import和@DepensOn注解。
Spring配置包含了至少一个必须容器管理的bean定义。基于XML的配置元数据显示为被顶级
这些bean定义与组成应用的实际对象通信。典型地,可以定义service层对象、数据访问对象(DAO)、诸如Struts Action实例的视图层对象、基础对象如hibernate SessionFactories、JMS Queues,等等,也不需要在容器中定义细粒度的领域对象,因为通常由DAO层和业务逻辑来创建和加载领域对象。然而,可以使用与AspectJ的集成来配置在IoC容器控制之外创建的对象。参考使用AspectJ依赖注入领域对象。
下面展示了XML配置的基础结构:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
id属性是一个字符串,它唯一标识一个bean的定义,class属性定义了bean的类型并且需要使用全路径。id属性的值指向了合作的对象。XML指定合作者XML并没有显示在上述例子中,具体可参考依赖。
7.2.2 实例化容器
实例一个Spring IoC容器很简单,提供给ApplicationContext构造方法的一个或多个路径是实际的资源字符串,这使得容器可以从不同的外部文件加载配置元数据,比如本地的文件系统,Java的CLASSPATH,等等。
- 1
- 1
- 在学习Spring IoC容器之后,你可能想更多地了解Spring的Resource概念,它提供了一种很便利的机制以URI语法的形式读取输入流,参考7 资源。特别地,Resource路径可被用于构造应用上下文,请参考7.7 应用上下文与资源路径。
下面的例子展示了service层的对象配置文件(services.xml):
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
下面的例子展示了数据访问对象daos.xml文件:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
在前面的例子中,service层包含类PetStoreServiceImpl和两个数据访问对象JpaAccountDao和JpaItemDao(基于JPA 对象关系映射标准)。property元素的name属性指向了JavaBean属性的名字,ref属性指向另一个bean定义的名字。id和ref之间的链接表达了两个合作者间的依赖关系。详细的配置和对象依赖请参考依赖。
组合基于XML的配置元数据
跨越多个XML文件配置bean定义是很有用的,通常一个独立的XML配置文件代表架构中的一个逻辑层或模块。
可以使用ApplicationContext的构造方法加载所有这些XML片段的bean定义。构造方法传入多个Resource路径即可,就像前面章节介绍的那样。替代方案,也可以使用一个或多个
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
上面的例子中,外部的bean定义从三个文件中加载进来:services.xml, messageSource.xml和themeSource.xml。所有的路径对于当前文件都是相对路径,所以services.xml必须在同一个目录或当前路径所在的classpath下,而messageSource.xml和themeSource.xml则必须在resources路径下,resources必须当前文件目录的下一级。如你所见,开头的斜杠被忽略了,即使给了路径也是相对的,不使用开头的斜杠格式还更好点。被导入文件的内容,包括顶级的
- 可以使用“../”路径的形式引用父目录的文件,但这是不推荐的。这样做会在当前应用之外的文件上创建一个依赖。尤其是这种引用不推荐放在“classpath:”URL中(例如,“classpath:../services.xml”),在运行时会选择最近的classpath的根目录,然后再在其父目录中寻找。classpath配置改变可能会导致选择了不同的错误的目录。
可以总是使用全路径定位资源代替相对路径,例如“file:C:/config/services.xml”或“classpath:/config/services.xml”。然而,注意这样会把应用程序的配置与特定的绝对路径耦合了。一般地,可以间接配置那个绝对路径,例如,通过JVM系统属性“${…}”占位符在运行时加载。
7.2.3 使用容器
ApplicationContext接口是一个先进的工厂,用于维护不同的bean及其依赖关系的注册。使用T getBean(String name, Class requiredType)方法可以获取bean实例。
ApplicationContext允许你可以像下面这样读取bean定义并访问它们:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
使用getBean()获取bean实例。ApplicationContext接口还有几个其它方法用于获取bean,但是理想状态下应用程序代码应该从来都不会用到它们。应用程序代码的解应该不会调用getBean()方法,而且不应该依赖于Spring的API。例如,Spring的web框架集成为不同的web框架类提供了依赖注入,比如controller和JSF管理的bean。
7.3 Bean概述
Spring IoC容器管理了至少一个bean,这些bean通过提供给容器的配置元数据来创建,例如,XML形式的
在容器本身内部,这些bean定义表示为BeanDefinition对象,它包含以下元数据:
- 包限定的类名:被定义bean的实际实现类。
- bean行为的配置元素,在容器中bean以哪种状态表现(scope,lifecycle,callback,等等)。
- 需要一起工作的其它对象的引用,这些引用又被称作合作者(collaborator)或依赖。
- 设置到新创建对象中的其它配置,例如,在bean中使用的连接数,用于管理连接池或池的大小。
元数据转化成了一系列的属性,组成了每个bean的定义。
表 7.1. bean定义
| 属性 | 参考 |
|---|---|
| class | 7.3.2 实例化bean |
| name | 7.3.1 命名bean |
| scope | 7.5 bean的作用域 |
| 构造方法的参数 | 7.4.1 依赖注入 |
| 属性 | 7.4.1 依赖注入 |
| 自动装配的模式 | 7.4.5 自动装配合作者 |
| 延迟初始化的模式 | 7.4.4 延迟初始化bean |
| 初始化的模式 | 初始化回调 |
| 销毁方法 | 销毁回调 |
除了包含创建指定bean的信息的bean定义外,ApplicationContext实现也允许注册用户在容器外创建的已存在的对象。可以通过ApplicationContext的getBeanFactory()方法获取其BeanFactory的实现DefaultListableBeanFactory。DefaultListableBeanFactory通过registerSingleton(…)和registerBeanDefinition(..)方法支持这样的注册。然而,典型的应用都是通过元数据定义bean。
- bean元数据和手动提供的单例实例需要尽早注册,为了容器在自动装配时正确推断它们和其它内省的步骤。在一定程度上支持重写已存在的元数据和已存在的单例实例,然而在运行时注册新bean(并发访问工厂)并不正式地支持,并且可能在容器中导致并发访问异常和/或不一致的状态。
7.3.1 命名bean
每一个bean都有一个或多个标识符。这些标识符在托管bean的容器中必须唯一。一个bean通常只有一个标识符,但如果需要更多标识符,可以通过别名来实现。
在XML中,可以使用id和/或name属性来指定bean的标识符。id属性允许显式地指定一个id。按照约定,这些名字是字母数字的(’myBean’, ‘fooService’, 等),但是也可以包含一些特殊字符。如果你想引入其它别名,也可以在name属性中指定,用逗号(,)、分号(;)或空格分割。作为历史记录,Spring 3.1之前的版本,id属性被定义为xsd:ID,它会限制一些可能的字符。3.1开始,它被定义为xsd:string类型。注意id的唯一性是被容器强制执行的,而不再是XML解析器。
给bean指定一个名字或id并不是必需的。如果没有显式地指定名字或id,容器会为那个bean生成一个唯一的名字。但是,如果要根据名字引用那个bean,比如通过ref元素或Service定位器查找,那么必须指定一个名字。不提供名字一般用于内部bean和自动装配合作者。
- bean命名的约定
命名bean时采用标准Java对字段的命名约定。bean名字以小写字母开头,然后是驼峰式。例如,(不带引号)‘accountManager’, ‘accountService’, ‘userDao’, ‘loginController’, 等等。
按统一的规则命名bean更易于阅读和理解,而且,如果使用Spring AOP,当通过名字应用advice到一系列bean上将会非常有帮助。
在bean定义外给bean起别名
在bean的定义中,可以为其提供多个名字,通过与id属性指定的名字或name属性里的其它名字组合起来。这些名字对同一个bean是等价的,在有些情况下很有用,比如,允许应用中的每个组件通过其本身指定的名字引用共同的依赖。
在bean定义的地方指定所有的别名并不足够。有时候希望在其它地方为bean指定一个别名。这在大型系统中很常见,它们的配置被很多子系统分割,每个子系统有它自己的一系列bean定义。在XML配置中,可以使用
- 1
- 1
在上述这个案例中,同一个容器中这个bean叫fromName,在使用了别名定义也可以叫toName。
例如,子系统A中的配置元数据通过subsystemA-datasource引用一个数据源,子系统B中的配置元数据通过subsystemB-datasource引用这个数据源,使用这两个子系统的主应用通过myApp-datasource引用这个数据源。为了使用这三个名字引用相同的对象,可以在MyApp配置中添加如下的别名定义:
- 1
- 2
- 1
- 2
现在每个组件和主应用都可以通过不同的名字引用这个数据源了,并且可以保证不会与任何其它的定义冲突(有效地创建了一个命名空间),它们还引用了同一个bean。
- Java配置
如果使用Java配置,@Bean注解可以用于提供别名,参考7.12.3 使用@Bean注解。
7.3.2 实例化bean
一个bean的定义本质上就是创建一个或多个对象的食谱。容器查看这个食谱并使用被bean定义封装的配置元数据来创建(或获取)实际的对象。
如果使用XML配置,在
- 典型地,容器直接通过反射调用bean的构造方法来创建一个bean,这个Java代码中使用new操作符是等价的。
- 容器通过调用工厂类中的static工厂方法来创建一个bean。通过调用static工厂方法返回的对象类型可能是同一个类,也可能是完全不同的另一个类。
- 内部类名字。如果为一个static嵌套类配置bean定义,必须使用嵌套类的二进制名字。
例如,如果在com.example包中有一个类叫Foo,并且Foo类中有一个static嵌套类叫Bar,那么bean定义中的class属性的值应该是com.example.Foo$Bar。
注意使用$字符分割嵌套类和外部类。
- 内部类名字。如果为一个static嵌套类配置bean定义,必须使用嵌套类的二进制名字。
使用构造方法实例化
用构造方法创建bean的方式,在Spring中所有正常的类都可以使用并兼容。也就是说,被开发的类不需要实现任何特定的接口或以特定的形式编码。仅仅指定bean类就足够了。但是,依靠什么样的类型来指定bean,你可能需要默认的空构造方法。
Spring的IoC窗口几乎可以管理所有的类,并不仅限于真的JavaBean。大部分用户更喜欢带有默认(无参)构造方法和适当setter/getter方法的JavaBean。你也可以拥有不同的非bean风格的类。例如,如果你需要使用不是JavaBean格式的连接池,Spring一样可以管理它。
在XML中,可以像下面这样指定bean类:
- 1
- 2
- 3
- 1
- 2
- 3
关于如何为构造方法提供参数(如果需要的话)及在对象被构造之后为其设置属性,请参考注入依赖。
使用静态工厂方法实例化
当使用静态工厂方法创建一个bean时,需要使用class属性指定那个包含静态工厂方法的类,并使用factory-method属性指定工厂方法的名字。应该可以调用这个方法(带参数的稍后讨论)并返回一个有效的对象,之后它就像用构造方法创建的对象一样对待。一种这样的bean定义的使用方法是在代码调用静态工厂。
下面的bean定义指定了通过调用工厂方法创建这个bean。这个定义没有指定返回类型,仅仅指定了包含工厂方法的类。在这个例子中,createInstance()方法必须是静态的。
- 1
- 2
- 3
- 1
- 2
- 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
关于如何为工厂方法提供参数及在对象从工厂返回之后为其设置属性,请参考依赖与配置详解。
使用实例的工厂方法实例化(非静态)
与使用静态工厂方法实例化类似,使用实例的工厂方法实例化是调用一个已存在的bean的非静态方法来创建一个新的bean。为了使用这种机制,请把class属性置空,在factory-bean属性中指定被调用的用来创建对象的包含工厂方法的那个bean的名字,并factory-method属性中设置工厂方法的名字。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
一个工厂类可以拥有多个工厂方法,如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
工厂bean本身也可以通过依赖注入管理和配置,参考依赖与配置详解。
- 在Spring的文档中,工厂bean引用Spring容器配置的通过实例或静态工厂方法创建对象的bean。相比之下,FactoryBean引用的是Spring特定的FactoryBean。
7.4 依赖
一个典型的企业级应用包含了不止一个对象(或者用Spring的说法叫bean)。即使是最简单的应用也需要几个对象一起工作以展现给最终用户看到的连贯应用。下一节介绍怎么样定义一系列独立的bean使它们相互合作实现一个共同的目标。
7.4.1 依赖注入
依赖注入是一个对象定义其依赖的过程,它的依赖也就是与它一起合作的其它对象,这个过程只能通过构造方法参数、工厂方法参数、或者被构造或从工厂方法返回后通过setter方法设置其属性来实现。然后容器在创建这个bean时注入这些依赖。这个过程本质上是反过来的,由bean本身控制实例化,或者直接通过类的结构或Service定位器模式定位它自己的依赖,因此得其名曰控制反转。
使用依赖注入原则代码更干净,并且当对象提供了它们的依赖时解耦更有效。对象不查找它的依赖,且不知道依赖的位置或类。比如,类变得更容易测试,尤其是当依赖是基于接口或抽象基类时,这允许在单元测试时模拟实现。
依赖注入有两种主要的方式,基于构造方法的依赖注入和基于setter方法的依赖注入。
基于构造方法的依赖注入
基于构造方法的依赖注入,由容器调用带有参数的构造方法来完成,每个参数代表一个依赖。调用带有特定参数的静态工厂方法创建bean几乎是一样的,这里把构造方法的参数与静态工厂方法的参数同等对待。下面的例子展示了一个只能通过构造方法注入依赖的类。注意,这个类并没有什么特殊的地方,它仅仅只是一个没有依赖容器的特定接口、基类或注解的POJO。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
构造方法参数的解决
构造方法参数的解决匹配时使用参数的类型。如果没有潜在的歧义存在于bean定义的构造方法参数中,那么在bean实例化时bean定义中参数的顺序与构造方法中的顺序保持一致。例如,下面这个类:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
没有潜在的歧义,假设Bar和Baz类没有继承关系。然后下面这样配置就可以了,不需要在
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
当另一个bean被引用时,类型是已知的并且匹配可能出现(像上例一样)。
当使用简单类型时,比如
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
在上述场景中,如果使用type属性指定了参数的类型则容器会使用类型匹配。例如:
(译者注:如果不指定类型,spring分不清把7500000赋给year还是42赋给year,因为constructor-arg并不是按它们出现的顺序与参数匹配)
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
使用index属性显式地指定参数的顺序。例如:
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
除了解决多个简单值的起义,使用索引还可以解决构造方法中存在多个相同类型的参数的问题。注意索引从0开始。
也可以使用参数的名字来消除起义:
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
注意,为了使其可以立即使用,代码必须开启调试标记来编译,这样Spring才能从构造方法中找到参数的名字。如果没有开启调试标记(或不想)编译,可以使用JDK的注解@ConstructorProperties显式地指定参数的名字。类看起来不得不像下面这样:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
基于setter方法的依赖注入
基于setter方法的依赖注入,由容器在调用无参构造方法或无参静态工厂方法之后调用setter方法来实例化bean。
下面的例子展示了一个只能通过纯净的setter方法注入依赖的类。这个类符合Java的约定,它是一个没有依赖容器的特定接口、基类或注解的POJO。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
ApplicationContext对它管理的bean支持基于构造方法和基于setter方法的依赖注入,也支持在使用构造方法注入依赖之后再使用setter方法注入依赖。以BeanDefinition的形式配置依赖,可以与PropertyEditor实例一起把属性从一种形式转化为另一种形式。但是,大多数Spring用户不直接(编程式地)使用这些类,而是使用XML bean定义、注解的组件(例如,以@Component、@Controller注解的类)或基于Java的@Configuration类的@Bean方法。这些资源然后都被内部转化为了BeanDefinition的实例,并用于加载完整的Spring IoC容器的实例。
- 基于构造方法或基于setter方法的依赖注入?
因为可以混合使用基于构造方法和基于setter方法的依赖注入,所以使用构造方法注入强制依赖并使用setter方法或配置方法注入可选依赖是一个不错的原则。注意,在setter方法上使用@Required注解可以使属性变成必需的依赖。
Spring团队一般倡导使用构造方法注入,因为它会使应用程序的组件实现为不可变的对象,并保证必需的依赖不为null。另外,构造方法注入的组件总是以完全初始化的状态返回给客户端(调用)代码。注意,大量的构造方法参数是代码的坏味道,这意味着类可能有很多责任,应该被重构为合适的部分以实现关注点的分离。
setter方法应该仅仅只用于可选依赖,这些可选依赖应该在类中被赋值合理的默认值。否则,在使用这项依赖的任何地方都要做非null检查。setter方法注入的好处之一是可以使那个类的对象稍后重新配置或重新注入。使用JMX MBeans的管理是使用setter注入很好的案例。
特定的类选择最合适的依赖注入方式。有时你并没有第三方类的源码,你就需要选择使用哪种方式。例如,如果一个第三方类没有暴露任何setter方法,那么只能选择构造方法注入了。
依赖注入的过程
容器按如下方式处理依赖注入:
- ApplicationContext被创建并初始化描述所有bean的配置元数据。配置元数据可以是XML、Java代码或注解。
- 对于每一个bean,它的依赖以属性、构造方法参数或静态工厂方法参数的形式表示。这些依赖在bean实际创建时被提供给它。
- 每一个属性或构造方法参数都是将被设置的值的实际定义,或容器中另一个bean的引用。
- 每一个值类型的属性或构造方法参数都会从特定的形式转化为它的实际类型。默认地,Spring可以把字符串形式的值转化为所有的内置类型,比如int, long, String, boolean,等等。
Spring容器在创建时会验证每个bean的配置。但是,bean的属性本身直到bean实际被创建时才会设置。单例作用域的或被设置为预先实例化(默认)的bean会在容器创建时被创建。作用域的定义请参考7.5 bean的作用域。否则,bean只在它被请求的时候才会被创建。创建一个bean会潜在地引起一系列的bean被创建,因为bean的依赖及其依赖的依赖(等等)会被创建并赋值。注意,那些不匹配的依赖可能稍后创建,比如,受影响的bean的首次创建(译者注:这句可能翻译的不到位,有兴趣的自己翻译下,原文为 Note that resolution mismatches among those dependencies may show up late, i.e. on first creation of the affected bean)。
- 循环依赖
如果你主要使用构造方法注入,很有可能创建一个无法解决的循环依赖场景。
例如,类A使用构造方法注入时需要类B的一个实例,类B使用构造方法注入时需要类A的一个实例。如果为类A和B配置bean互相注入,Spring IoC容器会在运行时检测出循环引用,并抛出异常BeanCurrentlyInCreationException。
一种解决方法是把一些类配置为使用setter方法注入而不是构造方法注入。作为替代方案,避免构造方法注入,而只使用setter方法注入。换句话说,尽管不推荐,但是可以通过setter方法注入配置循环依赖。
不像典型的案例(没有循环依赖),A和B之间的循环依赖使得一个bean在它本身完全初始化之前被注入了另一个bean(经典的先有鸡/先有蛋问题)。
你通常可以相信Spring做正确的事。它会在容器加载时检测配置问题,比如引用不存在的bean和循环依赖。Spring尽可能晚地设置属性和解决依赖,在bean实际被创建之后。这意味着Spring正确加载了,之后如果在创建对象或它的依赖时出现问题那么Spring又会产生异常。例如,因为一个缺少或失效的属性导致bean抛出了异常。这潜在地会推迟一些配置问题的可视性,这就是为什么ApplicationContext的实现类默认预先实例化单例bean。在bean实际需要之前会花费一些时间和内存成本,因此在ApplicationContext创建时会发现配置问题,而不是之后。你也可以重写默认的行为让单例bean延迟初始化,而不是预先实例化。
如果不存在循环依赖,当一个或多个合作的bean被注入依赖的bean时,每个合作的bean都将在注入依赖的bean之前被完全实例化。这意味着如果A依赖于B,那么在调用A的setter方法注入B之前会完全实例化B。换句话说,bean被实例化(如果不是预先实例化的单例),它的依赖被设置,然后相关的生命周期方法被调用(比如,配置的初始化方法或初始化bean的回调方法)。
依赖注入的示例
下面的例子使用XML配置setter方法注入。XML的部分配置如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
上面的例子中,XML中setter方法与属性匹配,下面的例子使用构造方法注入:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
bean定义中指定的构造方法参数将用作ExampleBean的构造方法参数。
现在考虑使用另外一种方式,调用静态工厂方法代替构造方法返回这个对象的实例:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
通过
7.4.2 依赖与配置详解
如前所述,可以定义bean的属性和构造方法的参数引用其它的bean(合作者),或设置值。在XML配置中,可以使用
直接设置值(原始类型,String,等等)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
下面的例子使用p命名空间可以更简洁的表示:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
上述XML更简洁了,但是错误只能在运行时被发现,而不是设计的时候,除非使用类似IntelliJ IDEA或Spring工具套件(STS)的开发工具,它们可以在创建bean定义时自动完成属性的拼写。强烈推荐使用这类IDE。
也可以像下面这样配置java.util.Properties:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Spring容器会使用JavaBean的PropertyEditor机制把
idref元素
idref元素是一种很简单的错误检查方式,可以把容器中另一个bean的id(字符串值-不是引用)传递给
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
上面的片段在运行时与下面的片段完成一样:
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
第一种形式比第二种形式更好,因为使用idref标签时容器会在部署时验证引用的命名的bean是否实际存在。第二种形式不会对client bean的targetName属性的值执行任何验证。错误只能在client bean实际实例化时才能发现(可能导致致命的结果)。如果client bean是一个prototype类型的bean。那么错误很可能会在容器启动很久之后才能发现。
- idref元素的local属性在4.0版本的xsd中不再支持了,因为它不提供对普通bean的引用。在升级的4.0的schema时只要把已存在的idref local改成idref bean即可。(译者注:idref local只能引用同一个文件中的bean,所以不建议使用了,改成idref bean即可。)
引用其它bean(合作者)
ref是
通过bean的标签指定目标bean是最常用的形式,并且可以引用同一个或父容器中的任何bean,不论是否在同一个XML文件中。引用的值可能是目标bean的id属性,或name属性中的一个(译者注:因为name属性可以指定多个name)。
- 1
- 1
通过parent属性可以指定对当前容器的父容器中的bean的引用。parent属性的值可能是目标bean的id属性或name属性中的一个,而且目标bean必须在当前容器的父容器中。这种引用形式主要出现在有容器继承并且想把父容器中存在的bean包装成同样名字的代理用于子容器的时候。
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- ref元素的local属性在4.0版本的xsd中不再支持了,因为它不提供对普通bean的引用。在升级的4.0的schema时只要把已存在的ref local改成ref bean即可。(译者注:ref local只能引用同一个文件中的bean,所以不建议使用了,改成ref bean即可。)
内部bean
在
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
内部bean不需要定义id或name,即使指定了,容器也不会使用它作为标识符。容器在创建内部bean时也会忽略其作用域标志,内部bean总是匿名的且总是随着外部bean一起创建。不可能把内部bean注入到除封闭bean以外的合作bean,也不可能单独访问它们。
有一种边界情况,可以从自定义作用域中接收销毁方法的回调,例如,对于包含在一个单例bean中的request作用域的内部bean,它的创建依赖于包含它的bean,但是销毁方法的回调允许它参与到request作用域的生命周期中。这并不是一种常见的情况,内部bean一般共享包含它的bean的作用域。
集合
在,
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
map的键值或set的值也可以是以下任何元素:
- 1
- 1
集合的合并
Spring容器同样支持集合的合并。开发者可以定义一个父类型的,
这节主要讨论父子集合的合并机制,读者如果对父子bean的定义不太熟悉,可以先读相关章节再继续。
下面的例子展示了集合的合并:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
注意子bean的adminEmails属性上的props元素的merge=true。当child被实例化时,它拥有一个adminEmails Properties集合,这个集合包含了父子两个集合adminEmails合并的结果。
- 1
- 2
- 3
- 1
- 2
- 3
子集合Properties的值集继承了所有父集合的元素,并且子集合中的support值重写了父集合的值。
, 和
元素合并的时候,因为List集合维护的是有序的值,所以父集合的值在子集合值的前面。在Map, Set和Properties中的值则不存在顺序。没有顺序的集合类型更有效,因此容器内部更倾向于使用Map, Set和Properties。
集合合并的局限性
不能合并不同的集合类型(比如,Map和List),如果试图这么做将会抛出异常。merge属性必须指定在子集合的定义上,在父集合上指定merge属性将是多余的且不会合并集合。
强类型集合
Java5引入了泛型类型,所以可以使用强类型的集合。也就是说,例如,可以声明一个只能包含String元素的集合类型。如果使用Spring把强类型的集合注入到一个bean,可以利用Spring的类型转换以便元素在被添加到集合之前转换成合适的类型。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
当foo的accounts属性准备注入的时候,会通过反射获得强类型Map
null和空字符串值
Spring把对属性的空参数作为空字符串。下面的XML片段把email属性的值设置成了空字符串值(”“)。
- 1
- 2
- 3
- 1
- 2
- 3
上面的例子与下面的Java代码是等价的:
- 1
- 1
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
上面的配置与下面的Java代码等价:
- 1
- 1
使用p命名空间简写XML
p命名空间使你可以使用bean元素的属性,而不是内置的
Spring支持使用命名空间扩展配置,这是基于XML的schema定义的。本章讨论的bean的配置形式是定义在XML schema文档中的。然而,p命名空间不是定义在XSD文件中的,它存在于Spring的核心包中。
下面例子中的两段XML是一样的结果,第一段使用标准的XML形式,第二段使用p命名空间形式。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这个例子展示了p命名空间中一个叫做email的属性。这会告诉Spring包含了一个属性声明。如前所述,p命名空间没有schema定义,所以可以把xml的属性名设置成java的属性名。
下面的例子包含两个引用了其它对象的bean定义:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
如你所见,此例不仅使用p命名空间定义属性值,还使用特定的形式声明了属性的引用。第一个bean定义使用
- p命名空间并没有标准的XML形式灵活。例如,属性如果以Ref结尾则会与属性的引用冲突,标准的XML形式就不会有这样的问题。我们推荐仔细地选择自己的方式,并和团队成员交流,以避免XML文档中同时出现三种不同的方式。
使用c命名空间简写XML
与使用p命名空间简写XML类似,c命名空间是Spring3.1新引入的,允许使用内联属性配置构造方法的参数,而不用嵌套constructor-arg元素。
让我们一起回顾下基于构造方法的依赖注入这节,使用c: 命名空间如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
c: 命名空间与p: 命名空间使用一样的转换(后面的-ref用于bean引用),通过名字设置构造方法的参数。同样地,c命名空间也没有定义在XSD文件中(但是存在于Spring核心包中)。
对于极少数的情况,不能获得构造方法参数名时(通常不使用调试信息编译字节码),可以退而求其次使用参数的索引。
- 1
- 2
- 1
- 2
- 由于XML语法,索引符号需要以 _ 开头作为XML属性名,而不能以数字开头(即使在一些IDE中允许)。
经过实践,构造方法的解决机制在匹配参数方面很有效率,所以除非真的需要,我们推荐在所有配置的地方都使用名字符号。
合成属性名
可以使用合成或嵌套的属性名设置bean的属性,只要路径中除了最后的属性值的所有的组件都不为null,考虑使用如下bean定义:
- 1
- 2
- 3
- 1
- 2
- 3
foo有一个属性叫fred,fred有一个属性叫bob,bob有一个属性叫sammy,并且最后的sammy属性的值被设置为123。其中,foo的fred属性和fred的bob属性在bean构造后必须不为null,否则将会抛出空指针异常。
7.4.3 使用depends-on
如果一个bean是另一个bean的依赖,那通常意味着这个bean被设置为另一个bean的属性。典型地,在XML配置中使用元素来完成这件事。但是,有时bean之间的依赖并不是直接的,例如,一个静态的初始化器需要被触发,比如在数据库驱动注册时。depends-on属性可以明确地强制一个或多个bean在使用它(们)的bean初始化之前被初始化。
下面的例子使用depends-on属性表示对一个单例bean的依赖:
- 1
- 2
- 1
- 2
要表示对多个bean的依赖,可以为depends-on属性的值提供多个名字,使用逗号,空格或分号分割:
- 1
- 2
- 3
- 4
- 5
- 6
- 1
- 2
- 3
- 4
- 5
- 6
depends-on属性能够同时指定初始化时依赖和通信销毁时依赖,这只能运用在单例bean的情况中。依赖的bean在给定的bean销毁之前被销毁。因此,depends-on也能够控制关闭的顺序。(译者注,初始化的时候依赖的对象先初始化才能注入,销毁时需要依赖的对象先销毁才能解绑)
7.4.4 延迟初始化的bean
默认地,ApplicationContext的实现创建和配置所有单例bean作为初始化过程的一部分。通常这种预初始化是令人满意的,因为配置或环境中的错误可以立即被发现,相反则可能需要数小时甚至数天才能发现错误。如果不需要预初始化,可以把bean定义为延迟初始化来阻止预初始化。延迟初始化的bean会告诉IoC容器在第一次请求到这个bean时才初始化,而不是启动的时候。
在XML中,这种行为是通过
- 1
- 2
- 1
- 2
当ApplicationContext使用上面的配置启动时时,名为lazy的bean并不急着预初始化,而not.lazy则会预初始化。
但是,当一个延迟初始化的bean是另一个非延迟初始化的单例bean的依赖时,ApplicationContext会在启动时创建这个延迟初始化的bean,因为它必须用来满足那个单例的依赖。这个延迟初始化的bean被注入到非延迟初始化的单例bean中。
也可以在
- 1
- 2
- 3
- 1
- 2
- 3
7.4.5 自动装配合作者
Spring容器可以相互合作的bean间自动装配其关系。你可让让Spring通过检查ApplicationContext的内容自动为你解决bean之间的依赖。自动装配有以下优点:
- 自动装配将极大地减少指定属性或构造方法参数的需要(在这点上,其它机制比如本章其它小节讲解的bean模板也是有价值的)。
- 自动装配可以更新配置当你的对象进化时。例如,如果你需要为一个类添加一个依赖,那么不需要修改配置就可以自动满足。因此,自动装配在开发期间非常有用,但不否定在代码库变得更稳定的时候切换到显式的装配。
使用XML配置时,可以为带有autowire属性的bean定义指定自动装配的模式。自动装配的功能有四种模式。可以为每个自动装配的bean指定一种模式。
表7.2 自动装配的模式
| 模式 | 解释 |
|---|---|
| no | 默认地没有自动自动装配。bean的引用必须通过ref元素定义。对于大型部署,不推荐更改默认设置,因为显式地指定合作者能够更好地控制且更清晰。在一定程度上,这也记录了系统的结构。 |
| byName | 按属性名称自动装配。Spring为待装配的属性寻找同名的bean。例如,如果一个bean被设置为按属性名称自动装配,且它包含一个属性叫master(亦即,它有setMaster(…)方法),Spring会找到一个名叫master的bean并把它设置到这个属性中。 |
| byType | 按属性的类型自动装配,如果这个属性的类型在容器中只存在一个bean。如果多于一个,则会抛出异常,这意味着不能为那个bean使用按类型装配。如果一个都没有,则什么事都不会发生,这个属性不会被装配。 |
| constructor | 与按类型装配类似,只不过用于构造方法的参数。如果这个构造方法的参数类型在容器中不存在明确的一个bean,将会抛出异常。 |
使用按类型装配或构造方法自动装配模式,可以装配数组和集合类型。在这个情况下,容器中所有匹配期望类型的候选者都将被提供用来满足此依赖。你可以自动装配强类型的Map如果其键的类型是String。自动装配Map的值将包含所有匹配期望类型的bean实例,并且Map的键将包含对应的bean的名字。
可以联合使用自动装配行为和依赖检查,其中依赖检查会在自动装配完成后执行。
自动装配的局限性和缺点
如果一个项目一直使用自动装配,它会运行得很好。如果只是用在一两个bean上,则会出现混乱。
自动装配有如下局限性和缺点:
- 在property和constructor-arg上显式设置的依赖总是覆盖自动装配。而且,不能自动装配所谓的简单属性,如基本类型、String和Classes(也包括简单属性的数组)。这是设计层面的局限性。
- 自动装配没有显式装配精确。如上表所述,尽管Spring很小心地避免了模棱两可的猜测,但其管理的对象之间的关系并不会被明确地记录。
- 从Spring容器生成文档的工具可能找不到装配信息。
- 容器中的多个bean定义可能会匹配setter方法或构造方法参数指定的类型。对于数组、集合或Map,这未必是个问题。但是,对于那些需要单个值的依赖,这种歧义并不能随意解决。如果没有各自不同的bean定义,将会抛出异常。
在上述场景中,有如下几种选择:
- 放弃自动装配,改为显式地装配。
- 设置bean的autowire-candidate属性为false以避免自动装配,这会在下一章节讲解。
- 设置
标签的primary属性为true,从而为其指定一个单独的bean作为主要的候选者。 - 使用基于注解的配置实现更细粒度的控制,参考7.9 基于注解的容器配置。
避免bean自动装配
在单个bean上,可以避免自动装配。在xml形式中,设置
也可以通过定义bean名称的匹配模式避免自动装配。顶级元素
这项技术对于那些你不想它们被自动注入到其它bean的bean非常有用。这并不意味着它自己不能使用自动装配,而是,它不是其它bean自动装配的候选者。
7.4.6 方法注入
在大部分应用场景中,容器中的大多数bean都是单例的。当一个单例bean需要与另一个单例bean合作,或者一个非单例bean需要与另外一个非单例bean合作的时候,仅仅定义一个bean作为另一个的属性就能解决它们的依赖关系。如果bean的生命周期不一致就会出现问题。假如,一个单例bean A 需要使用一个非单例bean B,也许在每次调用A的方法时都需要。容器仅仅创建这个单例bean A 一次,所以只有一次机会设置其属性。容器不能在 A 每次调用的时候都提供一个新的 B 的实例。
一种解决方法是放弃控制反转。你可以通过实现ApplicationContextAware接口使 A 能连接到容器,并在每次 A 需要 B 的实例的时候调用容器的getBean(“B”)方法取得新的 B 的实例。下面是这种方式的一种案例:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
上面这种方式并不推荐使用,因为业务代码跟spring耦合了。方法注入,从某种角度来看是spring IoC容器的高级特性,允许以一种干净的方式处理这种用例。
- 可以在这篇博客找到更多关于方法注入的信息。
查找方法注入
查找方法注入是容器的一项能力,它可以重写容器管理的bean的方法,并返回另一个bean的查找结果。查找往往涉及到前面描述的那种原型(prototype)bean。spring利用CGLIB库动态地生成字节码子类,从而重写方法以实现查找方法注入。
- 为了能使动态的子类有效,被继承的类不能是final,且被重写的方法也不能是final。
- 单元测试一个具有抽象方法的类时,需要手动继承此类并重写其抽象方法。
- 组件扫描的具体方法也需要具体类。
- 一项关键限制是查找方法不能使用工厂方法和配置类中的@Bean方法,因为容器不会在运行时创建一个子类及其实例。
- 最后,方法注入的目标对象不能被序列化。
查看前面关于CommandManager类的代码片段,可以发现spring容器会动态生成createCommand()方法的实现。CommandManager不会有任何的spring依赖,如下所示:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
客户端类包含了将被注入的方法(本例中的CommandManager),被注入的方法需要如下签名:
- 1
- 1
如果方法是抽象的,动态生成的子类会实现这个方法。另外,动态生成的子类也会重写原类中的具体方法。例如:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
commandManager这个bean会在任何它需要command实例的时候调用其createCommand()方法。如果实际需要,则必须把command声明为原型(prototype)。如果被声明为单例(singleton),则每次返回的都是同一个command实例。
- 有兴趣的读者可能会发现ServiceLocatorFactoryBean(位于包org.springframework.beans.factory.config中)就是这么用的。ServiceLocatorFactoryBean中用法与其它工具类一样,ObjectFactoryCreatingFactoryBean,但是它允许你使用自己的查找接口而不是spring指定的查找接口。请参考附加信息中这些类的javadoc文档。
任意的方法替换
方法注入的一种很少使用的形式,它是使用另外的方法实现替换目标bean中的任意方法。读者可以跳过本章的剩余部分直到这项功能真正需要的时候再回来看。
以xml形式为例,可以使用replaced-method元素指定用另一种实现替换bean中已存在的方法。如下例,我们希望重写其computeValue方法:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
一个实现了org.springframework.beans.factory.support.MethodReplacer接口的类提供了一个新的方法定义。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
原类的bean定义可能看起来像这样:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
可以使用一个或多个
- 1
- 2
- 3
- 1
- 2
- 3
因为参数的个数往往就能够区分每一种可能了,这种简写方法可以少打几个字,所以你可以只输入最短的字符就能够匹配参数类型。
7.5 bean的作用域
当创建一个bean定义时,就给了一份创建那个类的实例的食谱。bean定义是一份食谱,这个想法很重要,因为那意味着,可以根据一份食谱创建很多实例。
不仅可以控制bean实例的各种各样的依赖关系和配置值,还可以控制这些实例的作用域(scope)。这种方式很强大且是弹性的,因为可以通过配置选择实例的作用域,而不需要在类级别控制其作用域。bean可以被部署成多个作用域之一,spring支持很多作用域,对于web应用可以使用5种。
下面的作用域都是可以直接使用的,也可以创建自定义作用域。
表 7.3. bean的作用域
| 作用域 | 描述 |
|---|---|
| singleton(单例) | 默认值,每个spring的IoC容器中只保留一份bean定义对应的实例。 |
| prototype(原型) | 一份bean定义对应多个实例。 |
| request(请求) | 依赖于Http请求的生命周期,也就是说,每个Http请求都有它自己实例。这只在web应用上下文中有效。 |
| session(会话) | 依赖于Http会话的生命周期。这只在web应用上下文中有效。 |
| globalSession(全局会话) | 依赖于全局Http会话的生命周期。典型地仅当使用在Portlet上下文中有效。这只在web应用上下文中有效。 |
| application(应用) | 依赖于ServletContext的生命周期。这只在web应用上下文中有效。 |
| websocket | 依赖于WebSocket的生命周期。这只在web应用上下文中有效。 |
- 从Spring 3.0开始,还有一个thread作用域,但默认并没有被注册。更多信息请参考SimpleThreadScope的文档。关于怎么注册这个作用域及任何自定义作用域,请参考使用自定义作用域。
7.5.1 单例作用域
一个单例bean仅共享同一个实例,并且所有的请求都只返回同一个实例。
换句话说,当把一个bean定义为单例时,spring容器严格地只创建那个bean定义的一个实例。这个单独的实例被存储在单例bean的缓存中,并且所有后来的请求及引用都会返回这个缓存的对象。

spring中单例bean的概念不同于GoF设计模式中关于单例模式的定义。GoF的单例模式硬编码了对象的作用域,所以一个特定的类有且只有一个实例在一个类加载器中被创建。spring单例的作用域被更好地描述 为每个容器及每个bean。这意味着如果在一个spring容器中定义了一个特定类的bean,那么spring容器会且仅会创建一个那个bean定义对应的类的实例。单例作用域是spring默认的作用域。在xml形式中,按如下方式定义一个单例bean:
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
7.5.2 原型作用域
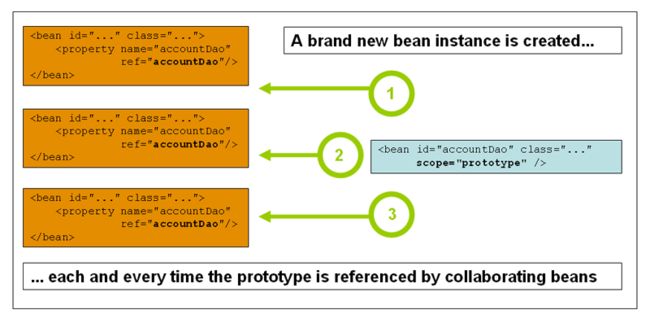
非单例的原型作用域的bean将会导致每次请求时都创建一个新的实例。也就是说,在这个bean被注入到另一个bean时,或通过容器的getBean()方法请求它时都会创建一个新的实例。通常来说,对于所有有状态的bean使用原型作用域,对于无状态的bean使用单例作用域。
下面的图表描绘了spring的原型作用域。一个DAO对象无需配置成原型的,因为它不具有状态,这里仅仅是作者为了重用单例作用域那节的图表。
在xml形式中,按如下方式定义一个原型bean:
- 1
- 1
与其它作用域相比,spring不会管理一个原型bean的完整生命周期:容器实例化、配置、装配原型对象,然后把它交给客户端,没有更多原型实例的记录了。因此,尽管初始化的回调方法在所有对象上被调用,但是对于原型对象,销毁的回调方法并未被调用。客户端代码必须自己清除原型作用域的对象并释放其占用的资源。为了让spring容器释放原型对象占用的资源,试着使用自定义的bean后置处理器,它拥有将要被清除的bean的引用。
在某些方面,spring容器关于原型对象的角色就相当于Java中的new操作。从传递点之后所有的生命周期都有客户端自己处理(关于spring容器中bean的生命周期的详细信息,请参考7.6.1 生命周期回调)。
7.5.3 依赖于原型bean的单例bean
当使用依赖于原型bean的单例bean的时候,注意依赖关系是在实例化的时候被解决的。因此,如果依赖注入一个原型bean到单例bean,一个新的原型bean会被实例化,然后注入到单例bean中。这个原型实例是唯一一个提供给这个单例bean的实例。
但是,假设需要在运行时单例bean每次都获得一个新的原型bean,没有办法做到注入一个新的原型bean到单例bean,因为注入仅仅发生一次,当容器实例化单例bean的时候已经解决了它的依赖的注入。如果需要在运行时获取新的原型实例,请参考7.4.6 方法注入。
7.5.4 请求、会话、全局会话、应用及WebSocket作用域
请求、会话、全局会话、应用及WebSocket作用域仅仅当使用在web上下文中才有效(比如XmlWebApplicationContext)。如果在其它spring容器中使用这些作用域,比如ClassPathXmlApplicationContext,将会抛出IllegalStateException,因为未知的作用域。
初始化web配置
为了支持请求、会话、全局会话、应用及WebSocket作用域,一些小小的初始化配置是必须的(对于单例和原型作用域,初始化配置并不是必须的)。
怎么完成这个初始化配置依赖于特定的Servlet环境。
如果使用Spring Web MVC,使用Spring的DispatcherServlet或DispatcherPortlet处理请求,那么就需要什么配置了,因为DispatcherServlet和DispatcherPortlet已经帮你配置好了。
如果使用Servlet 2.5 Web容器,不使用Spring的DispatcherServlet处理请求(例如,使用JSF或Struts时),则需要注册org.springframework.web.context.request.RequestContextListener ServletRequestListener。对于Servlet 3.0+,这项配置可以通过WebApplicationInitializer接口编程式处理。对于更老的容器,只能在web.xml文件中添加如下声明了:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果使用上述配置,考虑使用Spring的RequestContextFilter。过滤器映射依赖于其web应用配置,所以应该合适地调整之。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
DispatcherServlet, RequestContextListener和RequestContextFilter其实是做了同一件事,也就是绑定Http请求对象到服务于那个请求的线程。这样才能使得请求或会话作用域的bean能够更深入到调用链中。
请求作用域
考虑如下xml形式的bean定义:
- 1
- 1
spring容器为每次Http请求创建了一个新的LoginAction的实例。也就是说,loginAction的作用域是Http请求级别的。可以尽情地改变这个实例的内部状态,因为从同一份bean定义创建的其它实例不会发现这些状态的改变,它们只与特定的请求相关。当请求处理完成了,它绑定的bean就会被丢弃。
当使用注解驱动的组件或Java配置时,@RequestScope注解可以被用来赋值给一个组件的请求作用域。
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
会话作用域
考虑如下xml形式的bean定义:
- 1
- 1
spring容器为一个单独的Htpp会话创建一个新的UserPreferences实例。也就是说userPreferences的作用域是Http会话级别的。与请求作用域的bean一样,可以尽情地改变这个实例的内部状态,因为从同一份bean定义创建的其它实例不会发现这些状态的改变,它们只与特定的Http会话相关。当这个Http会话被丢弃的时候,它绑定的bean也就被丢弃了。
当使用注解驱动的组件或Java配置时,@SessionScope 注解可以被用来赋值给一个组件的会话作用域。
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
全局会话作用域
考虑下面的定义:
- 1
- 1
全局会话作用域与标准的Http会话作用域类似,不过它只用在基于portlet的web应用上下文中。portlet规范中定义了全局会话的概念,那就是共享了同一个portlet应用中所有的组件的全局的会话。定义为全局会话作用域的bean的生命周期与全局的portlet会话相关。
如果在标准的Servlet应用中定义一个或多个拥有全局会话作用域的bean,那么标准的Http会话作用域将被使用,并不会报错。
应用作用域
考虑如下xml形式的bean定义:
- 1
- 1
对于一个完整的web应用spring容器会创建一个新的AppPreferences实例。也就是说,appPreferences的作用域是ServletContext级别的,作为一个ServletContext普通属性被存储。这与spring的单例bean很类似,但有两种非常重要的区别:它在每个ServletContext中是单例,而不是spring的“ApplicationContext”(ApplicationContext在任何给定的web应用中可能存在多个)。另外,它实际上是作为ServletContext的属性被暴露并可见。
当使用注解驱动的组件或Java配置时,@ApplicationScope 注解可以被用来赋值给一个组件的应用作用域。
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
有作用域的bean作为依赖项
spring容器不仅管理对象(bean)的实例化,也连接合作者(依赖)。例如,如果注入一个Http请求作用域的bean到另一个更长周期的bean,可能会在原bean的位置选择使用AOP代理。也就是说,需要注入一个代理对象,这个代理对象暴露了与原对象相同的公共接口,但是它能从相关的作用域获取真实的目标对象,并以委托的方式调用真实对象的方法。
- 你可能也会在单例bean之间使用
当在原型对象上使用
另外,有作用域的代理并不是唯一一种生命周期安全的访问更短作用域的bean的方式。也可以简单地声明注入点(构造方法、setter方法的参数或自动装配的字段)作为ObjectFactory,在每次需要的时候调用getObject()获取当前实例——这种方式不用占有实例或分开存储它。
这种方式在JSR-330中的变种叫作Provider,使用Provider声明并在每次需要时调用get()方法。更多关于JSR-330的详细信息请点击这里。
下面的配置中仅仅只有一行,便更重要地是要理解“为什么”和“怎么样”。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
为了创建那么个代理,在bean定义中插入子元素
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
在这个例子中,单例userManager被注入了一个Http会话作用域的对象userPreferences。这里的显著点是userManager是一个单例:它将在每个容器中严格地实例化一次,并且它的依赖(此例中仅仅userPreferences一个)也只会注入一次。这就意味着userManager将只会操作同一个userPreferences对象,也就是一开始注入的那个。
这并不是我们把短周期的bean注入长周期的bean想要的结果,例如,注入一个Http会话bean到一个单例bean中。不如说,我们只需要一个userManager对象,但是需要与特定会话关联的userPreferences对象。这样,容器创建一个与UserPreferences类相同的公共接口的对象(理想状态是UserPreferences的一个实例),它可以从作用域机制(Http请求、会话等)中获取真实的UserPreferences对象。然后把这个代理对象注入到userManager中,且userManager不会意识到这是一个代理。在这个案例中,当UserManager实例调用依赖注入的UserPreferences对象的方法时,实际上是调用的这个代理的方法。这个代理然后从Http会话中获取真实的UserPreferences对象,并在这个真实的UserPreferences对象上委托方法调用。
因此,当注入请求、会话和全局会话作用域的bean到合作对象时,需要下面这样正确和完整的配置:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
选择代理的类型
默认地,当spring容器创建一个标记了
- CGLIB代理只能拦截公共方法调用!不要在那个代理上调用非公共方法,那样不会委托给真实的目标对象。
替代方案,可以配置spring容器创建标准的JDK基于接口的代理,通过指定
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
更多关于选择基于类的代理还是选择基于接口的代理的详细信息,请参考[11.6 代理机制](#proxying mechanisms)。
自定义作用域
作用域机制是可以扩展的,我们可以定义自己的作用域,甚至可以重新定义已存在的作用域,不过后者被认为是坏的实践,并且不能重写内置的单例和原型作用域。
创建自定义作用域
为了让自定义的作用域集成到spring容器中,需要实现org.springframework.beans.factory.config.Scope接口,这个接口会在接下来讲到。关于怎么实现自己的作用域,请参考spring自己提供的关于Scope的实现和Scope的javadocs,这里更详细地解释了需要实现的方法。
Scope接口有四个方法,从作用域中获取对象、移除对象和允许它们被销毁。
下面的方法用来从作用域中返回对象。例如,会话作用域的实现返回会话作用域的bean(如果不存在,则会返回一个新的实例,并绑定到会话中,为了将来使用)。
- 1
- 1
下面的方法用来从作用域中移除对象。例如,会话作用域的实现从会话中移除会话作用域的bean。对象应该被返回,但是如果指定名字的对象未找到可以返回null。
- 1
- 1
下面的方法用来注册作用域在销毁时或其中对象被销毁时应该执行的回调。参考javadocspring的作用域的一个实现获取关于销毁回调的更多信息。
- 1
- 1
下面的方法用来从作用域中获取会话(conversation,非session)标识。每个作用域的标识都不一样。对于会话作用域的实现,这个标识可以是会话id(session id)。
- 1
- 1
使用自定义作用域
在写完或测试完一个或多个自定义作用域的实现后,需要让spring容器识别到新的作用域。下面的方法是注册一个新的作用域到spring容器的核心方法。
- 1
- 1
这个方法定义在ConfigurableBeanFactory接口中,它允许大部分ApplicationContext的具体实现,这些实现通过BeanFactory属性与Spring联系在一起。
registerScope(..)方法的第一个参数是唯一与一个作用域关联的名字,例如,spring容器自己的singleto和prototype。它的第二个参数是具体的自定义的Scope的实现的一个实例,也就是希望注册并使用的。
假设你写了自定义的Scope实现,并像下面这样注册了它。
- 下面的例子使用了已经包含在spring中但默认未注册的SimpleThreadScope。这种方式同样适用于自定义的Scope实现。
- 1
- 2
- 1
- 2
然后就可以按照作用域的规则使用自定义的作用域了:
- 1
- 1
使用自定义的Scope实现,并不一定要编程式地注册,也可以像下面这样声明,使用CustomScopeConfigurer类:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 当放置
7.6 bean的特性
7.6.1 生命周期回调
为了与容器中bean的生命周期管理交互,可以实现Spring的InitializingBean和DisposableBean接口。容器会在初始化和销毁bean时调用前者的afterPropertiesSet()和后者destroy()方法执行相应的动作。
- 在现代spring应用中,JSR-250的@PostConstruct和@PreDestroy注解通常被认为是接收生命周期回调更好的实践。使用这些注解意味着bean不会与spring的接口耦合。更详细的信息请参考7.9.8 @PostConstruct和@PreDestroy。
如果不想使用JSR-250的注解,但又不想不与spring耦合,可以在bean定义时使用init-method和destroy-method指定其初始化和销毁方法。
spring内部使用BeanPostProcessor的实例处理它能找到的任何回调接口并调用合适的方法。如果需要定制一些spring未提供的又可以立即使用的功能或生命周期行为,可以直接实现自己的BeanPostProcessor 。更多信息请参考7.8 容器扩展点。
除了初始化和销毁回调,spring管理的对象也可以实现Lifecycle接口,从而参与到容器本身的生命周期的启动和关闭中。
生命周期回调接口将在下面描述。
初始化回调
org.springframework.beans.factory.InitializingBean接口允许bean的所有必要属性都被容器设置好后执行初始化操作。InitializingBean接口只有一个方法:
- 1
- 1
其实并不建议使用InitializingBean 接口因为没有必要把代码与spring耦合起来。可以使用@PostConstruct注解或在bean定义中指定初始化方法作为替代方案。在xml配置中,可以使用init-method属性指定一个无参的方法。在Java配置中,可以使用@Bean的initMethod属性,参考接收生命周期回调。例如,下面这种方式不会与spring耦合:
- 1
- 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
上面这种方式严格来说与下面的方式是一样的:
- 1
- 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
销毁回调
实现了org.springframework.beans.factory.DisposableBean接口的bean允许在包含这的容器被销毁时获取一个回调。DisposableBean接口只有一个方法:
- 1
- 1
其实并不建议使用DisposableBean回调接口,因为没必要把代码与spring耦合。可以使用@PreDestroy注解或在bean定义中指定销毁方法作为替代方案。在xml配置中,可以使用
- 1
- 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
上面这种方式严格来说与下面是一样的:
- 1
- 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
元素的destroy-method属性可以被赋予一个特殊的值“inferred”,它可以引导spring自动检测类中的公共close或shutdown方法(任何实现了java.lang.AutoCloseable和java.io.Closeable接口的类会匹配)。这个特殊的值“inferred”也可以设置在 元素的default-destroy-method属性上,这样会使所有的bean都执行这种行为(参考默认的初始化和销毁方法)。注意,这在Java配置中是默认行为。
默认的初始化和销毁方法
当不使用spring指定的InitializingBean和DisposableBean回调接口编写初始化和销毁回调方法时,我们一般会把这些方法命名为init(), initialize(), dispose()等等。理想状态下,在整个项目中这些方法的名字都是标准化的,以便所有的开发者都使用相同的名字并保证一致性。
可以配置spring容器在每个bean上自动寻找初始化和销毁的回调方法。这意味着,开发者可以直接使用init()作为初始化方法而不用为每一个bean配置init-method=”init”了。容器会在bean创建后调用这个方法(而且,这与标准的生命周期回调是一致的)。这个特性也需要为初始化和销毁方法定义统一的命名约定。
假设你的初始化方法叫init(),销毁方法叫destroy(),那么你的类将与下面的类很相似:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
顶级元素
同样地,可以配置顶级元素
当bean存在与上述约定不一样的回调方法名称时,可以使用
spring容器保证在bean的所有依赖都注入完毕时立马调用初始化回调方法。因此,初始化方法是调用在原生(非原生即代理)的bean引用上,这意味着AOP的拦截器还没开始生效。目标bean首先被完全创建,然后AOP代理及其拦截器链才被应用。如果目标bean与代理是分开定义的,我们甚至可以绕过代理直接与原生bean进行交互。因此,在初始化方法上应用拦截器是矛盾的,因为,这样做会把目标bean的生命周期与它的代理或拦截器耦合在一起,在直接使用原生bean时就会有很奇怪的语法。
组合使用生命周期机制
从spring 2.5 开始,有三种方式可以控制bean的生命周期行为:InitializingBean和DisposableBean回调接口;自定义的init()和destroy()方法;@PostConstruct和@PreDestroy注解。可以混合使用这些方式来控制给定的bean。
- 如果一个bean上配置了多种方式,并且每一种方式都配置为不同的方法名称,那么每一个配置的方法将按下面的顺序执行。但是,如果配置的相同的方法名称,那么只会执行一次。
同一个bean配置了多种方式,对于初始化方法将按以下顺序调用:
- @PostConstruct注解的方法
- InitializingBean接口定义的afterPropertiesSet()方法
- 自定义的init()方法
销毁方法也是同样的顺序:
- @PreDestroy注解的方法
- DisposableBean接口定义的destroy()方法
- 自定义的destroy()方法
启动和停止回调
Lifecycle接口为任何有自己生命周期需求的对象定义了一些基本的方法(例如,启动和停止一些后台进程)。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
所有spring管理的对象都可以实现这个接口。然后,当ApplicationContext接收到启动和停止的信号时,例如,运行时的stop/restart场景,它会级联调用此上下文内所有的Lifecycle实现。它是通过委托LifecycleProcessor实现的:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
注意,LifecycleProcessor本身扩展了Lifecycle接口,同时添加了两个另外的方法用于在上下文刷新和关闭时做出响应。
- 注意,org.springframework.context.Lifecycle接口只能显式地接收启动和停止的通知,而不会在因上下文刷新导致自动启动时接收到通知。考虑使用org.springframework.context.SmartLifecycle接口实现更细粒度的控制,它可以检测到自动启动(当然,也包括启动阶段)。同样地,请注意停止通知并不保证在销毁之前来临:正常停止时,所有的Lifecycle bean将会在销毁回调前首先接收到停止通知,在上下文生命周期内的热刷新或强制刷新,仅仅销毁方法会被调用。
启动和停止的调用顺序可能是很重要的。如果两个对象存在依赖关系,那么依赖方将在其依赖启动之后启动,并在其依赖停止之前停止。但是,有些时候依赖并不是直接的。你可能只知道一些特定类型的对象将在另外一些类型的对象之前启动。在这种情形中,SmartLifecycle接口有另外一种选择,它的父接口Phased中定义了一个getPhase()方法。
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
启动时,低相位(phase)的对象先启动;停止时,顺序反过来。因此,实现了SmartLifecycle接口并且getPahse()返回Integer.MIN_VALUE的对象将先启动后停止。反过来,带有Integer.MAX_VALUE相位的对象将会后启动先停止(可能是因为它依赖于其它进程运行)。对于那些正常的未实现SmartLifecycle接口的Lifecycle对象,它们的相位默认值为0。因此,负相位的对象将在这些正常对象启动之前启动,停止之后停止,反之亦然。
可以发现SmartLifecycle中的stop方法可以接受一个回调。任何实现必须在其停止线程完成以后调用回调(Runnable)的run()方法。在必须的时候可以异步停止,因为LifecycleProcessor接口默认的实现DefaultLifecycleProcessor会等到超时直到每个相位的对象都调用了那个回调。默认每个相位的超时时间是30秒。可以在上下文中定义一个名叫“lifecycleProcessor”的bean重写默认的生命周期处理器。如果仅仅只修改超时时间,那么下面的定义就足够了:
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
如前所述,LifecycleProcessor接口也定义了上下文刷新(onRefresh())和关闭(onClose())的方法。后者会简单地驱动关闭进程即使stop()方法被显式地调用了,但是它会发生在上下文关闭的时候。另一方面,刷新方法会带来SmartLifecycle bean的另一个功能。在上下文被刷新时(在所有对象都被实例化和初始化之后),这个方法会被调用,并且那时默认的生命周期处理器会检查每个SmartLifecycle对象的isAutoStartup()方法返回的布尔值。如果为true,那么这个对象会在那时被启动而不会等待上下文显式地调用或它自己的start()方法(不像上下文的刷新,标准的上下文实现并不会自动启动)。相位的值及依赖关系将会按与上面描述相同的方式检查启动顺序。
在非web应用中优雅地关闭spring的IoC容器
- 这节只针对非web应用。spring中基于web的ApplicationContext的实现已经可以优雅地关闭容器了当相关的web应用停止时。
如果在非web应用环境中使用spring的IoC容器,例如,在富客户端桌面环境中,注册一个JVM的关闭钩子(shutdown hook)。这样做可以保证优雅地关闭并调用相关单例bean的销毁方法从而使得所有的资源都被释放。当然,你必须要正确地配置并实现这些销毁方法。
为了注册一个关闭钩子,调用ConfigurableApplicationContext接口的registerShutdownHook()方法。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
ApplicationContextAware和BeanNameAware
当ApplicationContext创建了一个实现了org.springframework.context.ApplicationContextAware接口的对象实例时,这个实例就拥有了ApplicationContext的引用。
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
因此,bean可以编程式地操作创建了它的ApplicationContext,可以通过ApplicationContext接口,也可以把它强制转换成它的子类,比如ConfigurableApplicationContext,这样可以暴露更多的功能。一种使用方式是提取其它bean。有时这个能力很有用,但是,通常来说应该避免这样操作,因为这会使得代码与spring耦合,并且不符合控制反转的原则,而控制反转中合作者是以属性的方式提供的。ApplicationContext还提供了一些诸如访问文件资源、发布应用事件、访问消息源的方法。关于附加功能的描述请参考7.15 ApplicationContext的附加功能。
从spring 2.5 开始,自动装配就是另外一种获取ApplicationContext引用的方式。传统的constructor和byType装配模式(参考7.4.5 自动装配合作者)能够分别为构造方法参数或setter方法参数提供一个ApplicationContext类型的依赖。另外,也可以使用注解方式自动装配字段或方法参数。如果这样做了,ApplicationContext就会被注入到一个字段、构造方法参数或者其它需要ApplicationContext类型的方法参数,当然这些字段或参数得带有@Autowired注解。更多信息请参考7.9.2 @Autowired。
当ApplicationContext创建了一个实现了org.springframework.beans.factory.BeanNameAware接口的类时,这个类就拥有了一个定义在它关联的对象定义中的名字的引用。
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
这个方法会在操作了正常的属性之后但是在初始化方法之前运行,不管是InitializingBean的afterPropertiesSet()方法还是自定义的init()方法
7.6.3 其它Aware接口
除了上面讨论的ApplicationContextAware和BeanNameAware接口,spring还提供了一系列的Aware接口使得bean可以从容器获取需要的资源(依赖)。大部分重要的Aware接口汇总在下面了——通常,它们的名字已经可以很好地解释它们的依赖类型了。
表7.4 Aware接口
| 名称 | 注入的依赖 | 描述 |
|---|---|---|
| ApplicationContextAware | 声明ApplicationContext | 7.6.2 ApplicationContextAware和BeanNameAware |
| ApplicationEventPublisherAware | 封闭的ApplicationContext的事件发布者 | 7.15 ApplicatinContext的附加功能 |
| BeanClassLoaderAware | 用于加载bean的类加载器 | 7.3.2 实例化bean |
| BeanFactoryAware | 声明BeanFactory | 7.6.2 ApplicationContextAware和BeanNameAware |
| BeanNameAware | 定义的bean的名字 | 7.6.2 ApplicationContextAware和BeanNameAware |
| BootstrapContextAware | 容器运行于其中的资源适配器BootstrapContext。一般只用于JCA所在的上下文中。 | 32 JCA CCI |
| LoadTimeWeaverAware | 加载时处理类定义的织入者 | 11.8.4 加载时使用AspectJ织入 |
| MessageSourceAware | 配置的用于解决消息的策略(用于支持参数化及国际化) | 7.15 ApplicatinContext的附加功能 |
| NotificationPublisherAware | spring中JMX通知发布者 | 31.7 通知 |
| PortletConfigAware | 当前容器运行于其中的PortletConfig。仅用于web上下文中。 | 25 Portlet MVC 框架 |
| PortletContextAware | 当前容器运行于其中的PortletContext。仅用于web上下文中。 | 25 Portlet MVC 框架 |
| ResourceLoaderAware | 配置的用于低级别访问资源的加载器 | 8 资源 |
| ServletConfigAware | 当前的容器运行于其中的ServletConfig。仅用于web上下文中。 | 22 Web MVC 框架 |
| ServletContextAware | 当前的容器运行于其中的ServletContext。仅用于web上下文中。 | 22 Web MVC 框架 |
再次注意,使用这些接口将使你的代码与spring的API耦合,并且不会遵循控制反转的原则。因此,他们被推荐用于需要编程式访问容器的基础设施bean。
7.7 bean定义的继承
bean的定义中可以包含大量的配置信息,包括构造方法参数、属性值以及容器指定的信息,比如初始化方法、静态工厂方法名等等。子bean定义可以从父定义中继承配置信息。子定义可以重写这些值,也可以在需要的时候添加新的。使用父子定义可以少码几个字,这是模板的一种形式。
如果编程式地使用ApplicationContext,子定义可以使用ChildBeanDefinition类。不过大部分用户并不这样使用,而是以类似ClassPathXmlApplicationContext的形式声明式地配置。在xml中,可以使用子定义的parent属性指定父bean。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
如果没有指定子定义的class,则会使用父定义的class,不过也可以重写它。后者必须保证子定义中的class与父定义中的class兼容,即它可以接受父定义中的属性值。
子定义可以从父定义继承作用域、构造方法参数值、属性值以及方法,也可以为它们添加新值。任何在子定义中定义的作用域、初始化方法、销毁方法或者静态工厂方法都会覆盖父定义中的配置。
其余的配置总是取决于子定义:依赖、自动装配模式、依赖检查、单例、延迟初始化。
上面的例子中在父定义中显式地使用了abstract属性。如果父定义不指定类,那么必须显式地标记abstract属性,如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
父bean不能被实例化,因为它本身并不完整,并且被显式地标记为abstract了。当一个bean被定义为abstract,则它只能用做定义子bean的模板。如果试着使用abstract的父bean,比如通过另一个bean引用它或调用getBean()方法获取它,都会报错。同样,容器内部的preInstantiateSingletons()方法也会忽略定义为abstract的bean。
- ApplicationContext默认预实例化所有的单例。因此,如果有一个仅用于模板的bean,并且指定了类,请保证把abstract属性设置为true,否则容器会尝试预实例化它。
7.8 容器扩展点
通常,开发者不需要自己实现ApplicationContext。然而,Spring提供了一些特殊的集成接口,实现这些接口可以扩展Spring。下面几个章节将介绍这些集成接口。
7.8.1 使用BeanPostProcessor自定义bean
可以实现BeanPostProcessor接口定义的回调方法,从而提供自己的实例化逻辑、依赖注入逻辑等。如果想要在spring容器完成了实例化、配置及初始化bean前后实现自定义的逻辑,那么可以插入一个或多个BeanPostProcessor的实现。
可以配置多重BeanPostProcessor实例,并且可以设置它们的order属性控制它们的执行顺序,不过只有当这些实例也实现了Ordered接口才可以。更多信息请参考BeanPostProcessor和Ordered接口的javadoc,也可以参考下面关于BeanPostProcessor的编程式注册的说明。
- BeanPostProcessor操作对象实例,也就是说IoC容器实例化bean实例后BeanPostProcessor才工作。
BeanPostProcessor是每个容器作用域的,即使使用容器继承也不行。声明在一个容器内的BeanPostProcessor只能处理那个容器内的bean。换句话说,一个容器内的bean不会被另一个容器的BeanPostProcessor处理,即使两个容器处于同一继承体系中。
为了改变实际的bean定义,需要使用BeanFactoryPostProcessor,参考7.8.2 使用BeanFactoryPostProcessor自定义配置元数据。
org.springframework.beans.factory.config.BeanPostProcessor接口包含两个回调方法。如果容器中一个类被注册为后处理器,那么对于容器创建的每一个bean实例,在它们初始化前后都会获得这个后处理器的一个回调。这个后处理器可以对bean实例采取任何行动,也可以完全忽略回调。一个bean后处理器一般用于检查回调接口或用代理包装bean。一些Spring的AOP基础类为了提供代理包装的逻辑都被实现为后处理器。
(译者注:此处要理解实例化(instantiation)和初始化(initialization)的区别,bean是先实例化再初始化的,后(置)处理器是针对实例化来说的,它是在bean实例化后起作用,但是它内部的两个方法分别在bean初始化前后执行拦截的作用)
ApplicationContext会自动检测所有实现了BeanPostProcessor接口的所有bean,接着把它们注册为后处理器,以便在其它bean创建的时候调用它们。后处理器bean可以像容器中其它bean一样部署。
注意,当使用@Bean工厂方法配置一个BeanPostProcessor实现类时,这个工厂方法的返回值类型必须是这个实现类本身或至少得是org.springframework.beans.factory.config.BeanPostProcessor接口,清晰地表明这个bean是后处理器的本性。否则,ApplicationContext在完全创建它之前不能通过类型检测到它。因为BeanPostProcessor需要早点被实例化以便应用到其它bean的初始化中,所以早期的类型检测是必要的。
-
虽然我们推荐使用ApplicationContext自动检测BeanPostProcessor,但是也可以使用ConfigurableBeanFactory的addBeanPostProcessor方法编程式地注册。这在注册之前处理条件逻辑或者在同一继承体系上下文之间复制后处理器很有用。注意,编程式注册的BeanPostProcessor并不遵从Ordered接口的顺序,那是因为它们注册的顺序就是它们执行的顺序。同样地,编程式注册的BeanPostProcessor总是在通过自动检测注册的BeanPostProcessor之前执行。
-
实现了BeanPostProcessor接口的类是很特殊的,并且会被容器特殊对待。所有BeanPostProcessor和它们直接引用的bean会在启动时实例化,且作为ApplicationContext启动的特殊部分。然后,所有的BeanPostProcessor按顺序注册并应用到所有后来的bean上。因为AOP的自动代理也被实现为BeanPostProcessor本身,所以无论是BeanPostProcessor还是它们直接引用的bean都有获得自动代理的资格,且不会有切面织入它们。对于这些bean,你应该会看到一条信息日志消息:“Bean foo is not eligible for getting processed by all BeanPostProcessor interfaces (for example: not eligible for auto-proxying)”。注意,如果有bean通过自动装配或@Resource(可能会变成自动装配)被装配到了BeanPostProcessor,Spring在通过类型匹配查找依赖时可能会访问非预期的bean,从而使它们具有自动代理或其它后处理的资格。例如,如果通过不带name属性的@Resource注解在一个字段或setter方法上声明了一个依赖,并且这个字段或setter方法的名字并不直接与一个bean的名字通信,然后Spring将通过类型去匹配它们。
下面的例子展示了如何在ApplicationContext中编写、注册并使用BeanPostProcessor。
例子,BeanPostProcessor风格的Hello World
第一个例子展示了基本用法,它显示了一个自定义的BeanPostProcessor实现在bean在被创建时调用它们的toString()方法并把结果打印到控制台。
请看下面自定义的BeanPostProcessor实现类的定义:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
从上面可以看到,InstantiationTracingBeanPostProcessor是如此简单的定义。它甚至不需要一个名字,而且因为它是一个bean,它也可以像其它bean一样被依赖注入。(上面的例子也展示了如何通过Groovy脚本语言定义一个bean。关于Spring的动态语言支持的详细描述请参考35 动态语言支持。)
下面简单展示了Java应用如何执行前面的代码和配置:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
上面应用的输出看起来像下面这样
- 1
- 2
- 1
- 2
例子:RequiredAnnotationBeanPostProcessor
使用回调接口、注解或自定义的BeanPostProcessor实现类是一种扩展Spring容器的常用方式。Spring的RequiredAnnotationBeanPostProcessor是其中一个例子——它可以保证bean中被注解@Required标记的属性能被依赖注入一个值。
7.8.2 使用BeanFactoryPostProcessor自定义配置元数据
接下来我们看的一个扩展点是org.springframework.beans.factory.config.BeanFactoryPostProcessor。这个接口的语法与BeanPostProcessor类型,主要区别是:BeanFactoryPostProcessor操作的是配置元数据,也就是说,Spring容器允许BeanFactoryPostProcessor读取配置元数据并可能在容器实例化这些bean之前改变它们,当然,BeanFactoryPostProcessor除外。
可以配置多重BeanFactoryPostProcessor,也可以通过设置它们的order属性控制它们的执行顺序,当然,只有实现了Ordered接口才能设置顺序。更多BeanFactoryPostProcessor和Ordered接口的详细信息请参考javadoc。
- 如果想改变实际的bean实例,使用BeanPostProcessor即可。尽管在技术上使用BeanFactoryPostProcessor也是可以的,但是这样做会导致不成熟的bean实例化,违背了标准的容器生命周期,并可能导致负面影响,比如绕过bean的后置处理。
同样地,BeanFactoryPostProcessor也是每个容器作用域的,即使在容器继承体系中也是如此。在一个容器中定义的BeanFactoryPostProcessor,只能作用于这个容器的bean定义,不能处理另一个容器的bean定义,即使两个容器羽毛球同一个继承的体系也不可以。
ApplicationContext中定义的BeanFactoryPostProcessor是自动执行的,以便作用于这个容器中定义的元数据。Spring包含很多预先定义好的BeanFactoryPostProcessor,比如PropertyOverrideConfigure和PropertyPlaceholderConfigure。也可以使用自定义的BeanFactoryPostProcessor,比如,用于注册自定义的属性编辑器。
ApplicationContext会自动检测所有实现了BeanFactoryPostProcessor接口的bean,并在适当的时候使用这些bean作为bean工厂后置处理器。可以像部署其它bean一样部署这些后置处理器。
- 与BeanPostProcessor一样,一般不会配置BeanFactoryPostProcessor延迟初始化。如果没有别的bean引用一个Bean(Factory)PostProcessor,那这个后置处理器不会被实例化。因此,设置延迟初始化会被忽略,并且Bean(Factory)PostProcessor会自动初始化,即使在
元素设置default-lazy-init为true也没用。
例子:类名替代PropertyPlaceholderConfigurer
如果使用标准的Java Properties形式从外部文件中加载属性值,那么需要使用PropertyPlaceholderConfigurer。这样做可以定制环境相关的属性值,比如数据库URL和密码,而不需要冒很大的风险去修改容器中XML的定义。
查看下面的XML配置片段,配置DataSource时使用了占位符。这个例子展示了如何从外部文件配置属性。在运行时,PropertyPlaceholderConfigurer会替代其中的一些属性。这些被替代的占位符以${property-name}的形式定义,这与Ant/log4j/JSP EL的风格是一致的。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
实际的值是以标准Java Properties的形式存在于另一个文件中的:
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
因此,在运行时字符串${jdbc.username}会被替换为值’sa’,其它的占位符也是按一样的规则替换。PropertyPlaceholderConfigurer会检查一个bean定义的大部分属性。另外,占位符的前缀和后缀是可以自定义的。
Spring 2.5中引入的context命名空间中有专门配置占位符的元素。一个或多个位置可以使用逗号分割开。
- 1
- 1
PropertyPlaceholderConfigurer不仅查找我们指定的Properties文件中的属性值。默认地,如果在指定的文件中没有找到它还会检查Java的系统属性。设置它的systemPropertiesMode属性可以改变它的行为,包含以下三个值:
- never(0):从不检查系统属性。
- fallback(1):如果指定文件中没有找到才检查系统属性。这是默认值。
- override(2):在尝试查找指定的文件前先检查系统属性。这允许系统属性覆盖其它的属性来源。
更多信息请参考PropertyPlaceholderConfigurer的javadoc。
-
可以使用PropertyPlaceholderConfigurer去替换类名,这在运行时指定实现类有时候会很有用。例如:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如果在运行时这个类不能被解析为正确的类,那么这个bean会创建失败,对于非延迟初始化的bean,这种失败发生在ApplicationContext的preInstantiateSingletons()期间。
PropertyOverrideConfigurer
PropertyOverrideConfigurer,另外一个bean工厂后置处理器,与PropertyPlaceholderConfigurer类似,但又不像后者,原始的bean定义的属性可以有默认值或没有值。如果重写的Properties文件没有合适的值,那就使用默认值。
注意,bean定义是不会意识到被重写的,所以从XML定义是看不出重写配置器被使用的。如果有多个PropertyOverrideConfigurer实例定义了同一个属性的不同的值,那么最后一个会起作用,因为重写机制的存在。
属性文件按下面的形式编写:
- 1
- 1
例如:
- 1
- 2
- 1
- 2
这个例子适用于包含了一个dataSource的bean的定义,且它包含driver和url属性。
也支持复合的属性名,只要除了最后一个属性之前的组件不为空即可。例如:
- 1
- 1
它表示foo有一个fred属性,fred有一个bob属性,bob有一个属性sammy,这个sammy属性会被设置成123。
- 注意,重写的值总是字面值,它们不会被翻译成bean的引用,这种转换也适用于XML定义中指定的bean引用的原始值。
Spring 2.5中引入的context命名空间中有专门配置属性重写的元素。
- 1
- 1
(译者注:关于BeanPostProcessor和BeanFactoryPostProcessor的使用请参考本人另一篇博文:http://blog.csdn.net/tangtong1/article/details/51916679)
7.8.3 使用FactoryBean自定义实例化逻辑
为对象实现org.springframework.beans.factory.FactoryBean接口,这些对象是他们自己的工厂。
FactoryBean接口是Spring窗口实例化逻辑的插入点。如果有一个非常复杂的初始化代码,它用Java能比XML更好地表述,那么就可以创建一个自己的FactoryBean,编写复杂的初始化逻辑在那个类中,并插入到窗口中。
FactoryBean接口提供了三个方法:
- Object getObject():返回这个工厂创建的一个实例。这个实例可以共享,由这个工厂单例还是原型决定。
- boolean isSingleton():如果返回的是单例则返回true,否则返回false。
- Class getObjectType():返回getObject()方法返回的对象的类型,如果事先不知道类型那就返回null。
FactoryBean的概念和接口在Spring框架中被大量使用,Spring自己至少使用了50个FactoryBean的实现。
当需要从容器获得实际的FactoryBean的实例时,调用ApplicationContext的getBean()方法时在bean的id前面加上&符号即可。所以对于一个id为myBean的FactoryBean,调用getBean(“myBean”)会返回FactoryBean创建的实例,然而,调用getBean(“&myBean”)则会返回FactoryBean的实例本身。
(译者注:关于FactoryBean的使用请参考本人另一篇博文:http://blog.csdn.net/tangtong1/article/details/51920069)
7.9 基于注解的容器配置
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
一种XML形式的替代方案是使用基于注解的配置,它依赖于字节码元数据,用于装配组件并可取代尖括号式的声明。不同于使用XML描述一个bean,开发者需要把配置移动到组件类本身,并给相关的类、方法及字段声明加上注解。像例子:RequiredAnnotationBeanPostProcessor中提及的一样,联合使用BeanPostProcessor和注解是扩展Spring容器的一种常用方法。例如,Spring 2.0引入了@Required注解,它强制属性必须获取一个值。Spring 2.5遵循同样的方式驱动依赖注入。本质上,@Autowired注解提供了相同的能力,如7.4.5 自动装配合作者中描述的一样,不过它提供了更细粒度的控制和更广泛的适用性。Spring 2.5也支持JSR-250的注解,比如@PostConstruct和@PreDestroy。Spring 3.0支持JSR-330的注解,它们位于javax.inject包下,比如@Inject和@Named。更详细的信息可以在相关章节中找到。
- 注解形式的注入在XML形式之前执行,因此,如果同时使用了两者,则XML形式的注入会覆盖注解形式的注入。
可以一个一个地注册这些bean,也可以隐式地注册它们,使用下面的配置即可(注意,请包含context命名空间)。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
(隐式注册的后置处理器包括AutowiredAnnotationBeanPostProcessor, CommonAnnotationBeanPostProcessor, PersistenceAnnotationBeanPostProcessor以及前面提到的RequiredAnnotationBeanPostProcessor。)
7.9.1 @Required
- JSR-330的@Inject注解可以替换下面例子中Spring的@Autowired注解。更多详情请点这里。
可以在构造方法上使用@Autowired:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 从Spring 4.3开始,如果目标bean只有一个构造方法,则@Autowired的构造方法不再是必要的。如果有多个构造方法,那么至少一个必须被注解以便告诉容器使用哪个。
也可以在setter方法上使用@Autowired:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
也可以应用在具有任意名字和多个参数的方法上:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
也可以应用在字段上,甚至可以与构造方法上混用:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
也可以从ApplicationContext中提供特定类型的所有bean,只要添加这个注解在一个那种类型的数组字段或方法上即可:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
同样适用于集合类型:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 如果需要数组或list中的元素按顺序排列的话,可以让这些bean实现org.springframework.core.Ordered接口或使用@Order注解或标准的@Priority注解。
甚至Map也可以被自动装配,只要key的类型是String就可以。Map的value将包含所有的特定类型的bean,并且key会包含这些bean的名字。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
默认地,如果没有候选的bean则自动装配会失败。这种默认的行为表示被注解的方法、构造方法及字段必须(required)有相应的依赖。也可按下面的方法改变这种行为。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2