Redis的复制(MasterSlave)
Redis的复制(Master/Slave)
1.是什么
1.1官网
…
1.2行话
也就是我们所说的主从复制,主机数据更新后根据配置和策略自动同步到备机的master/slave机制,Master以写为主,Slave以读为主。
2.能干嘛
2.1读写分离
2.2容灾恢复
3.怎么玩
3.1配从(库)不配主(库)
3.2从库配置:salveof 主库IP 主库端口
3.2.1 每次与master断开之后,都需要重新连接,除非你配置进redis.conf文件
3.2.2 Info replication
3.3修改配置文件细节操作
1.拷贝多个redis.conf文件
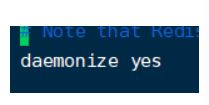
2.开启daemonize yes
3.Pid文件名字
4.指定端口
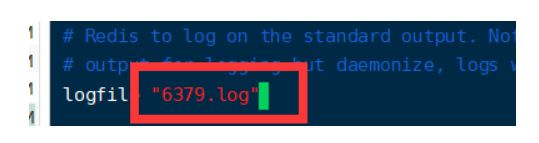
5.Log文件名字
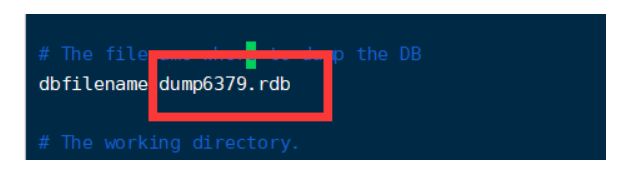
6.Dump.rdb名字
拷贝多个redis.conf文件
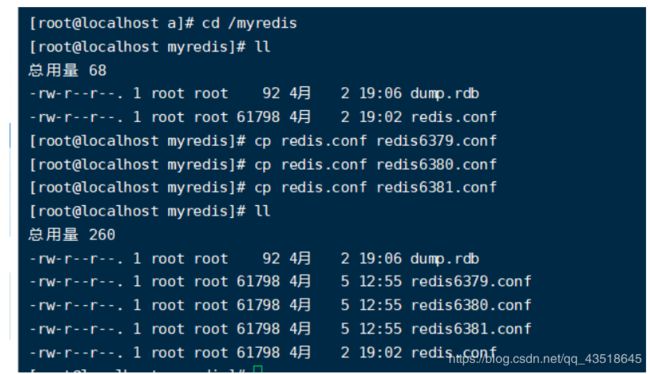
修改每一个redis.conf文件(6379.6380.6381)

修改端口号

开启daemonize yes
修改Pid文件名字

修改Log文件名字
修改Dump.rdb名字
注意:6379.conf,6380.conf,6381.conf 3个配置文件都需要进行修改,再次不在阐述。
wq!保存退出
3.4常用3招
1.一主二仆
2.薪火相传
3.反客为主
3.4.1一主二仆
启动服务器和客户端

查看一下 ps -ef|grep redis

先看第一个指令
info replication
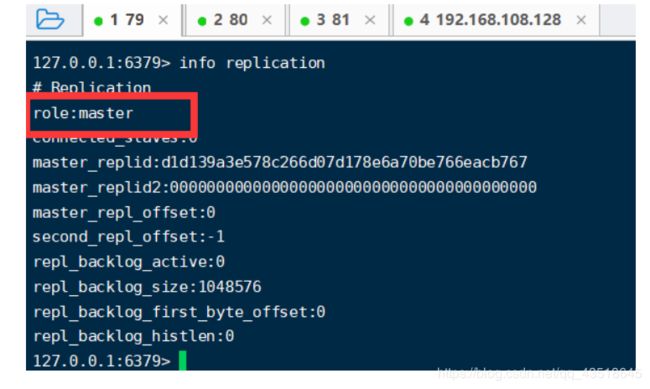
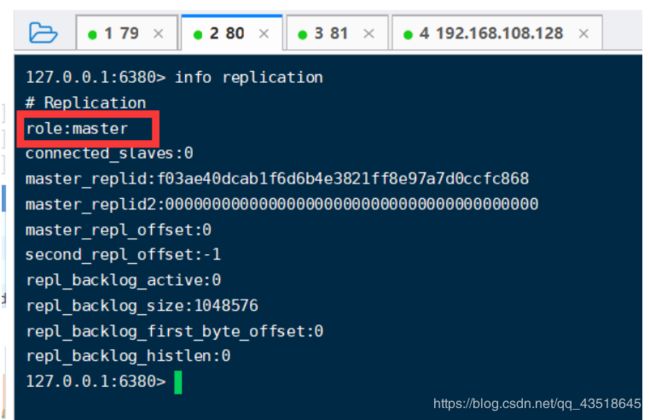
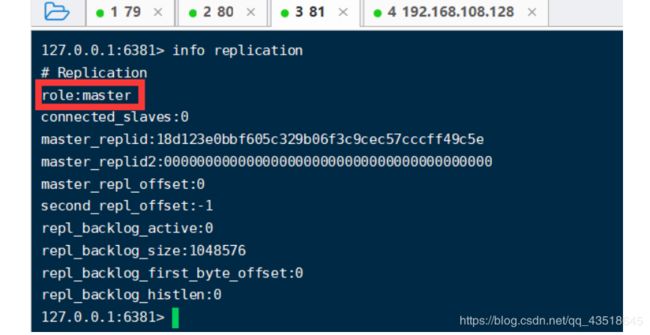
看到当前3个角色都是:master
先在6379这里设置值
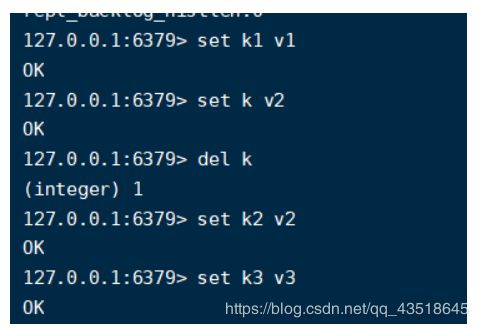
然后把6379当作主人,6380.6381为6379的仆人
slaveof 主机名 端口号
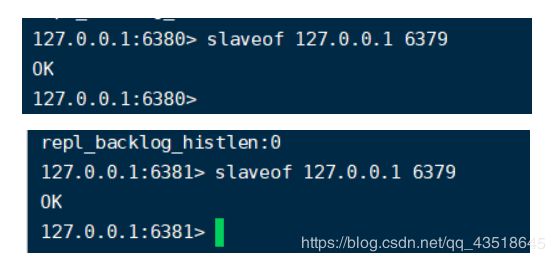 这个时候,在主机6379上存入值k4
这个时候,在主机6379上存入值k4

测试一下,在6380.6381上看能不能取到k4
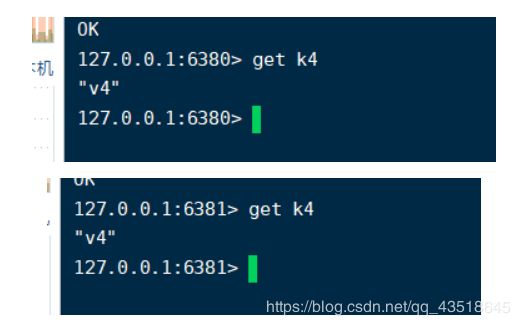
好,问题是k1,k2,k3能不能取到(即建立主从关系之前存入的值能不能取到)
测试一下
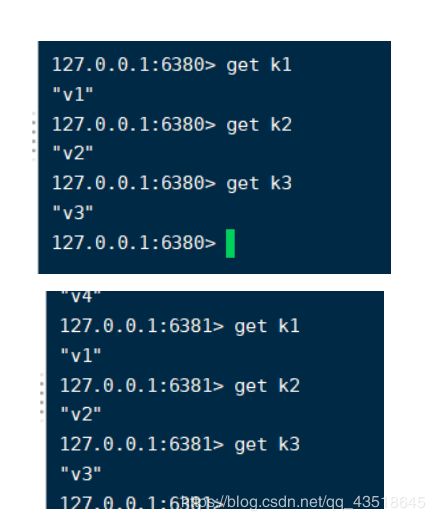
好的,可以取到,也就是说建立主从关系后,之前的所有数据都要保存。
我们刚才把80.81设置成了79的仆人,可以看一下, info replication
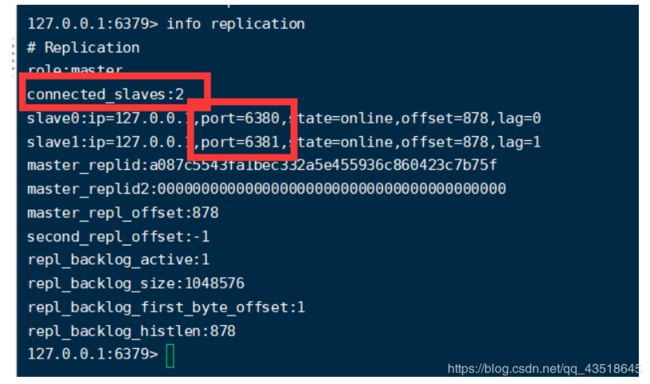
现在来看几个情况:
情况一:如果79.80.81都要设置一个值 k6,并且79先设置了,那么80.81可以设置k6么?是覆盖还是不行报错。

好吧,看结果就应证了主(写)从(读)。自己细品吧。(读写分离)
情况二:如果,现在主机死了(79),那么从机(80.81)是上位变成master还是原地待命?
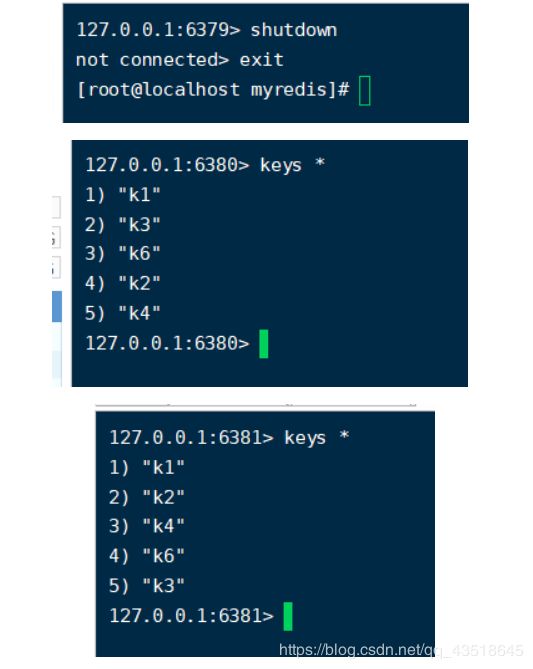
看到数据还是保存有,那么看一下角色变了没?是上位了?还是仍然是小弟。
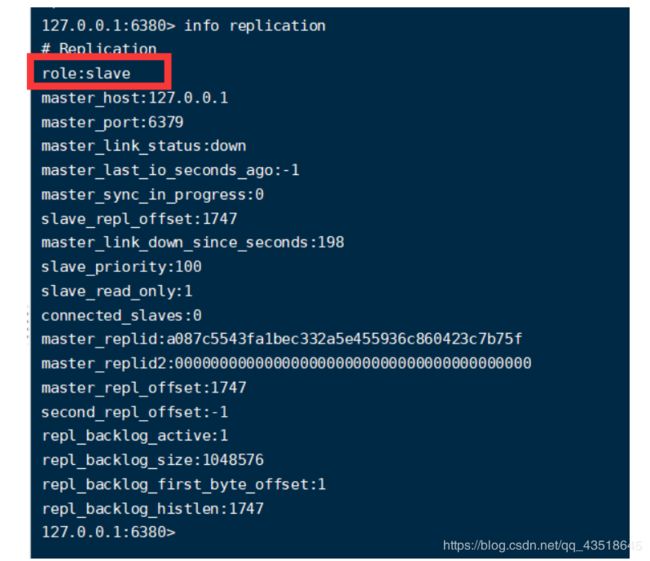

好吧,还是一条臭咸鱼。!
情况三:现在主机又活过来了,那么在主机设置k7,从机还能取到k7么(也就是说主从关系还存在么?)
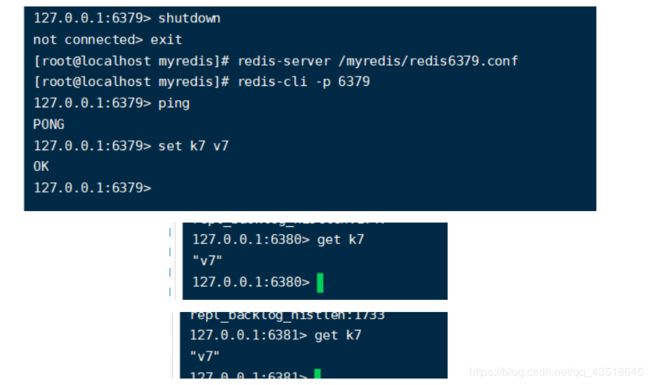
好吧,主人就是主人,短暂离去,归来仍是主人!
情况四:如果从机死了,从机再开服务,还能续借上这个主从关系么?
假设80死了
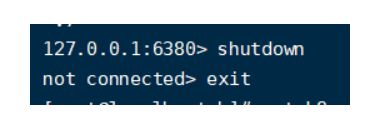
再次启动

可以看到从机死了就死了,再开启,就是另外一个路了,自己是一个新的主人。
3.4.2薪火相传
上一个Slave可以是下一个Slave的Master,Slave同样可以接收其它slaves的连接和同步请求,那么该slave作为了链条中下一个master,可以有效减轻master的写压力。
中途变更转向:会清除之前的数据,重新建立连接拷贝最新的Slaveof新主库IP端口。
79–》80–》81
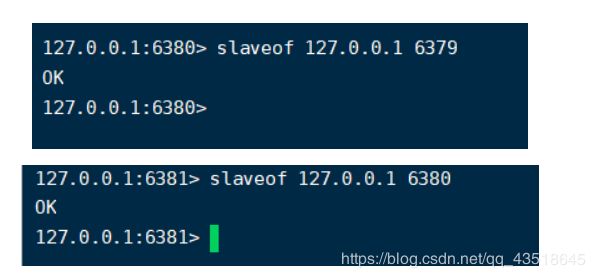
79为80的主人,80为81的主人
给79设置值
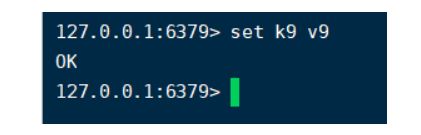
看下80.81是否可以拿到

可以看到,都可以拿到,那么现在一个问题是80的角色是master还是slave?
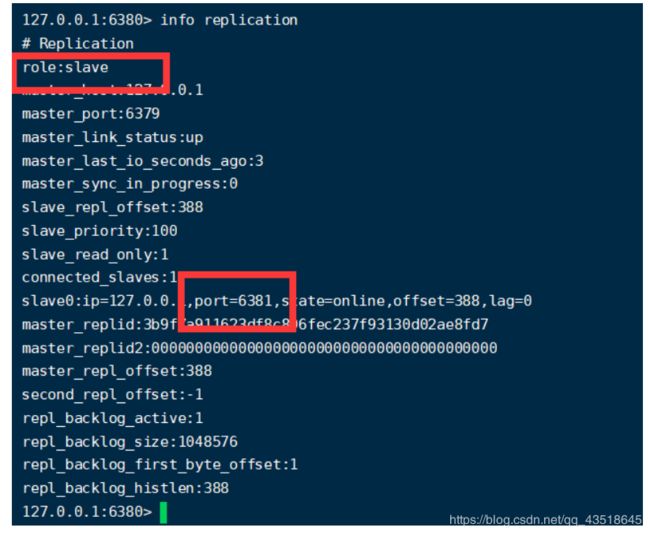
3.4.3反客为主
反客为主:可以对比一下一主二从,主机挂了,从机不会上位,而反客为主就是主机改了,从机要上位了。
把主机79搞挂掉

从机上位,我们让80上位

给80设置值k10

那么对于我们的81来说,有2个选择,要不还是跟着老领导混,静静等待老领导回来,要么改换门庭,跟80混。
我们就让他跟80混吧

问题:现在79杀回来了,那么查看一下79的信息吧。
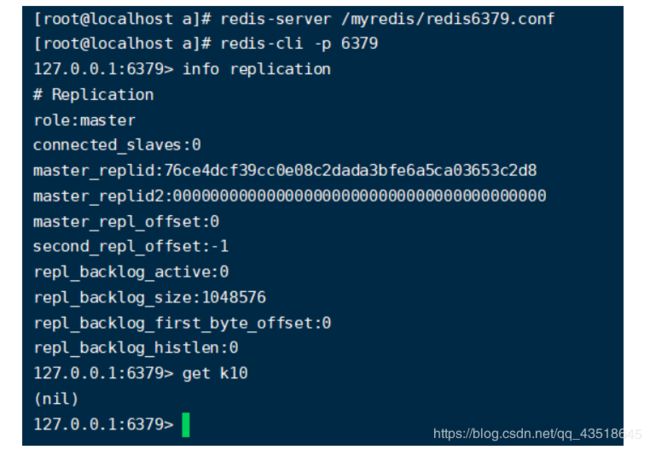
好吧,和你79没有关系了。
4.复制原理
1.Slave启动成功连接到master后会发送一个sync命令
2.Master接到命令启动后台的存盘过程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
3.全量复制:而Salve服务在接收到数据库文件数据后,将其存盘并加载到内存中
4.增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步,但是只要是重新连接master,一次完全同步(全量复制)将自动执行。
首次全量复制,之后增量复制。
5.哨兵模式(sentinel)
公司中常用的,哨兵模式可以简单理解成反客为主的自动版。(有个哨兵在巡逻,只要主机挂了,哨兵就通知,在剩下的从机里面投票选举一个成为新的主机)。
把79.80.81恢复成一主二从的模式
使用步骤:
1.调整目录结构79.80.81(一主二从结构)
2.自定义的/myredis目录下新建sentinel.conf文件,名字不能错
3.配置哨兵,填写内容
sentinel monitor 被监控主机名字(自己起名字) 127.0.0.1 6379 1
上面的1代表的意思:表示主机挂掉之后salve投票看让谁接替为主机,得票数多的为主机。
4.启动哨兵
5.正常主从演示
6.原有的master挂了
7.投票新选
8.重新主从继续开工,info replication查看
问题:如果之前的master重启回来,会不会双master冲突?
1.调整目录结构79.80.81(一主二从结构)
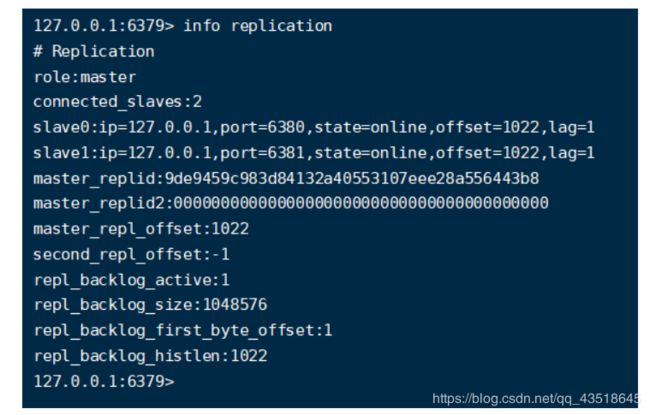
2.自定义的/myredis目录下新建sentinel.conf文件,名字不能错

3.配置哨兵,填写内容
vim sentinel.conf

wq!保存退出
4.启动哨兵
redis-sentinel /myredis/sentinel.conf
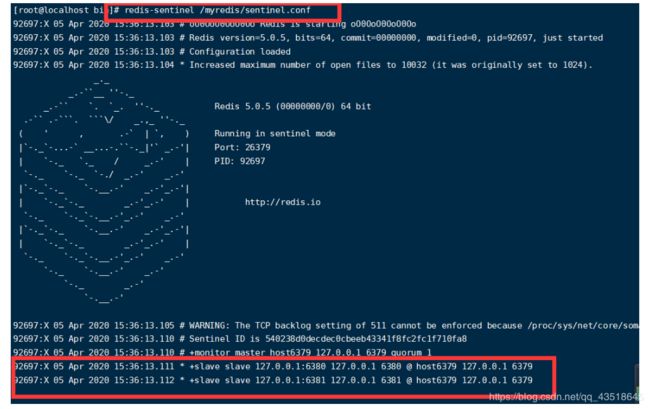
哨兵就盯着79,只要79死了,迅速在80.81中选择一个
5.正常主从演示
//TODO…(不再演示了)
6.原有的master挂了
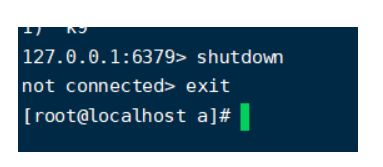
7.投票新选

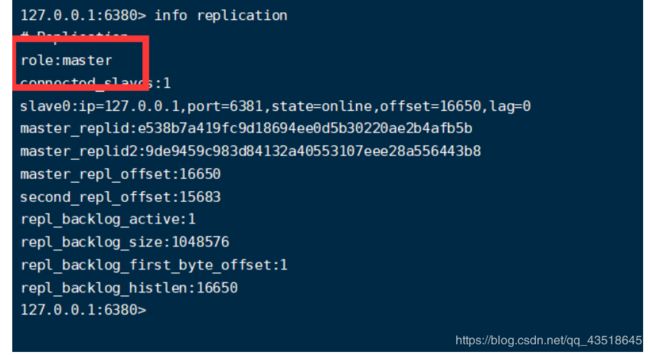
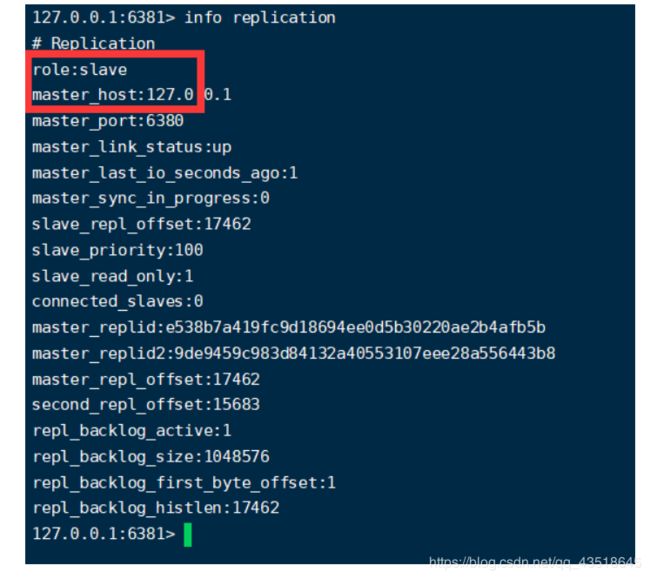
到80已经自动变成了master
8.重新主从继续开工
问题:如果之前的master重启回来,会不会双master冲突?
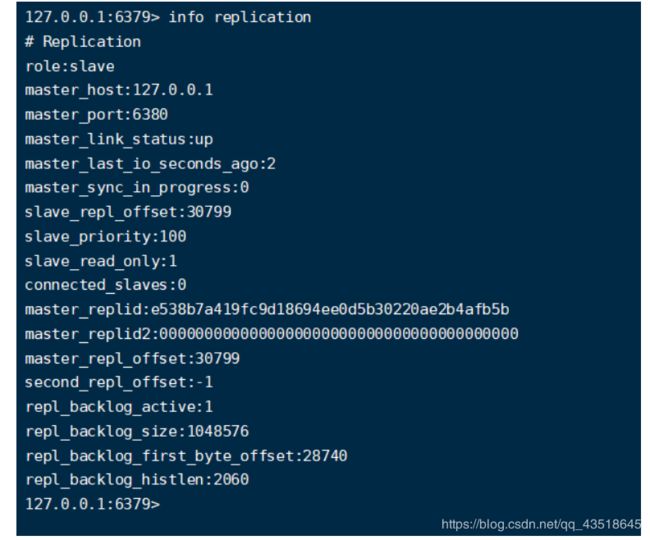
可以看到老领导回来之后就是80的兵了不再是老领导了。
6.复制的缺点
复制延时
由于所有的写操作都是现在Master上操作,然后同步更新到Slave上,所以Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量增加也会使这个问题更加严重。