星期六倒腾了一只python爬虫脚本(支持下图,数据清洗过滤,自动建表字段并存储入库Mysql)附demo演示
个要定义为是 简单实用的python爬虫脚本,支持下图,数据清洗过滤,存储入库 Mysql,Api post
应用场景:
crontab 定时监控的抓取某个列表实时的更新,然后发布或保存
目前功能点
1.下载图片本地化
2.数据MYSQL入库
3.数据过滤清洗
4.采集字段灵活定义 存储表根据爬中字段创建MYSQL字段,也可直接应用于生产环境的数据库,根据生产库设置爬虫字段
通过计划任务每3分钟调用脚本以达到实时与采集目标站点同步更新的效果,图片可用同步软件与远程同步。
暂不要每分钟,因为脚本执行时间的问题,可能会出现越来越多的进程。
计划功能点
1.多线程
2.进程检查
3.分页与历史数据的抓取(已有,还未整合进这版)
4.采集数据接口提交 (已有,还未整合进这版)
使用方法,理论上环境没问题了,预创建的数据库OK了,这脚本可直接运行测试了。
python splider2019.py httptest 测试并显示采集的一条数据
python splider2019.py http 正式采集
演示录像的目标网站选的不好,网络不稳定,有时候卡的采半天没动静,录了好多次。
配置方法
参考代码中的注释即可
"""
python2.7.x版本
"""
C = {"SITE":{},"DBCONFIG":{},"FIELD":{},"SAVEAPI":'',"Thread":1,"HEADER":{}}
#数据采集发布的API 功能未整合 预留
C['SAVEAPI'] = ''
#MYSQL数据库连接配置 采集数据存储
C['DBCONFIG']['save_host'] = '127.0.0.1'
C['DBCONFIG']['save_dbname'] = 'ceshi' #必须提前创建或存在数据库
C['DBCONFIG']['work_data'] = 'work_data' #指定数据保存表 自动创建 支持使用现有表
C['DBCONFIG']['work_log'] = 'work_log' #指定日志保存表 自动创建
C['DBCONFIG']['save_user'] = 'root'
C['DBCONFIG']['save_password'] = '123456'
"""
采集规则配置开始
"""
C['SITE']['home'] = 'http://www.51tietu.net'
C['SITE']['list_url'] = ['http://www.51tietu.net/weitu/','']#入口列表页 只要采集规则适用就支持多个
C['SITE']['is_json'] = False #暂用不到 就是采集接口的
C['SITE']['items_start'] = '' #列表页范围切片开始
C['SITE']['items_end'] = '' #列表页范围切片结束
C['SITE']['items_url'] = ' (?:.+?)
(.+?)
' #获取标题的正则
C['FIELD']['content'] = '([\S\s]*?)'
C['FIELD']['addtime'] = '[NOW]' #[NOW]是唯一一个保留标签,会在插入时替换成当前时间
C['USE_FILTER'] = 'content' #需要使用过滤的字段,必须是上面设置的,比如现在的 C['FIELD']['content']
#理论上以下不需要手工干预
if(C['SITE']['home'].find('https://') != -1):
C['ISHTTPS'] = True
C['HOST'] = C['SITE']['home'].replace("https://","")
else:
C['ISHTTPS'] = False
C['HOST'] = C['SITE']['home'].replace("http://", "")
C['HEADER'] = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
"Referer":C['HOST'],"Host":C['HOST'],"Accept-Language":"zh-CN,zh;q=0.8,zh-TW;q=0.6,ar;q=0.4,en;q=0.2","Accept-Encoding":"gzip, deflate","Connection":"keep-alive",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8"}
"""
采集规则配置结束
"""
效果图 动态图加载比较慢 耐心等下:
演示用的目标采集网址不稳定,时不时就timeout,录这个我都试了几次
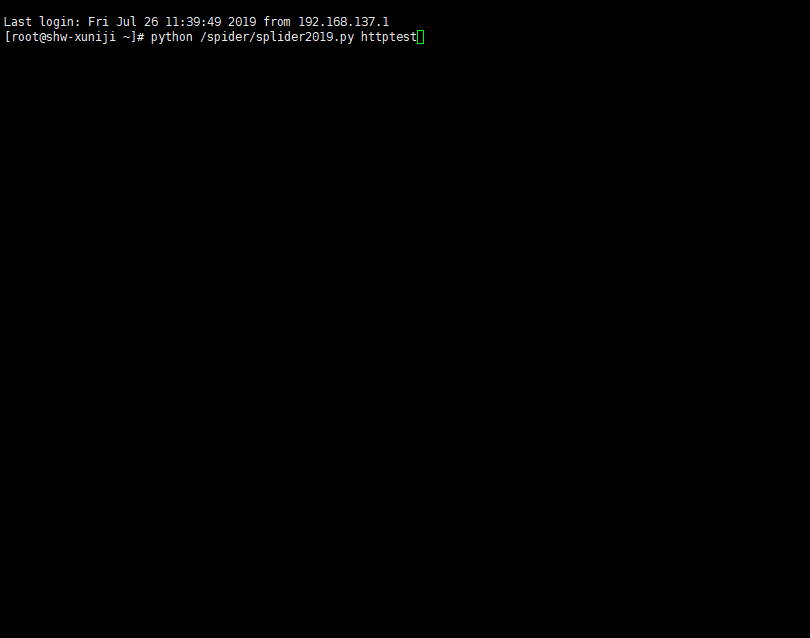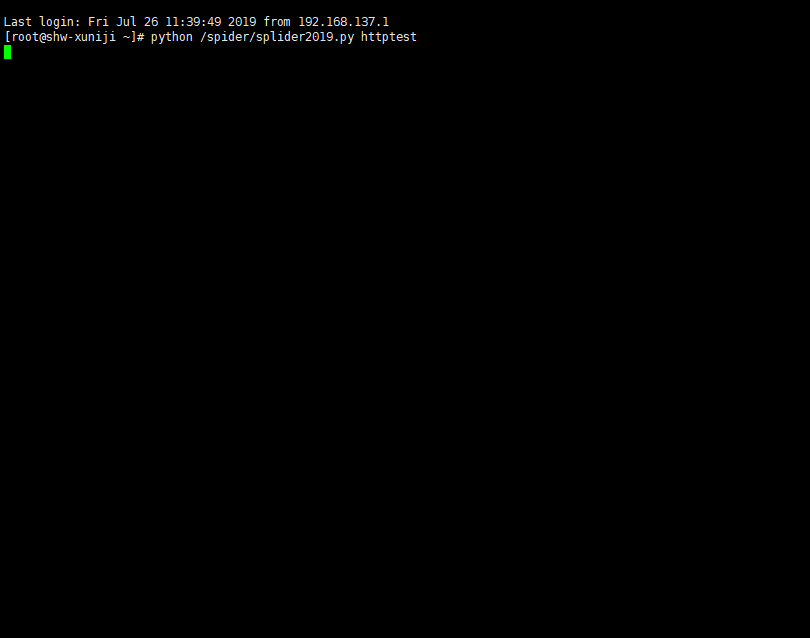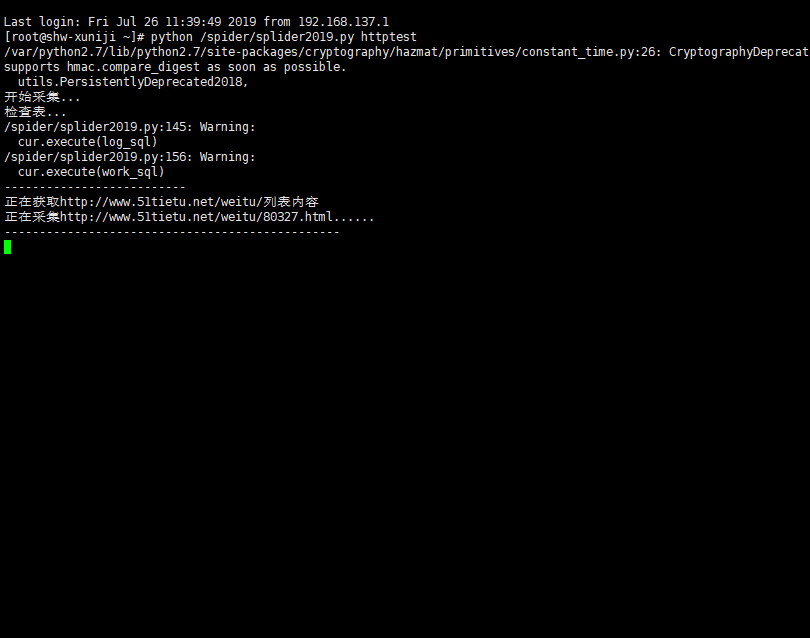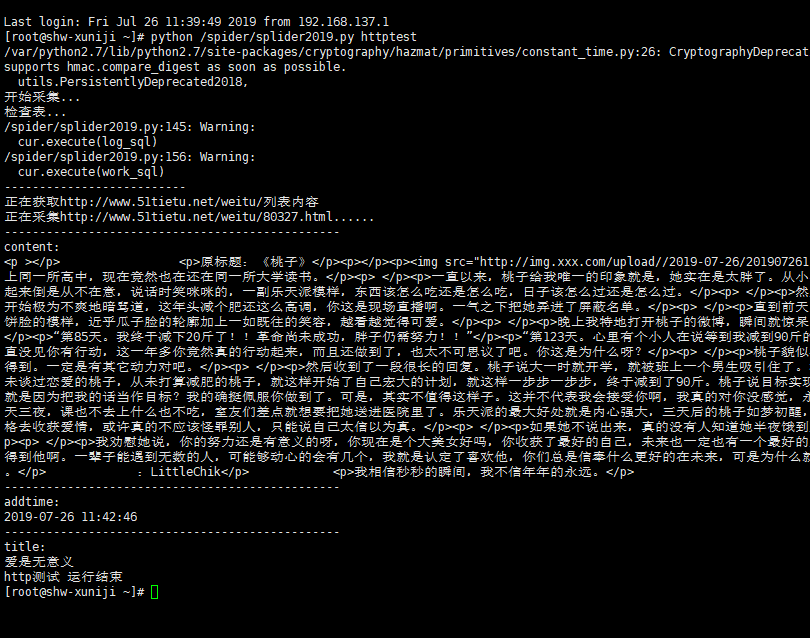
第一图展示的就是显示采集到的一条数据,常用于规则配置好后的验证和修改测试等。
第二图展示的是一个空数据库,爬虫自动创建表 字段,并完成数据入库,字段根据 并记录日志和排重 并看到图片已下载。
贴代码篇幅有点长,已传github,需要的朋友可以下载
https://github.com/shw3588/splider2019
水平不高,如果高手来看,还请指点。
个人主页 https://www.isres.com ,有个人主页的朋友加个友链呗^_6