分级聚类——Hierarchical cluster算法
分级聚类——Hierarchical cluster算法
本篇文章是我在学习《集体智慧编程》这本书时,学习了一下cluster分级聚类算法,然后加入一点自己的理解,代码基于python3,与python2有一点不同。
- 分级聚类Hierarchical cluster算法
- 引言
- 聚类过程
- 聚类实例
- 1读取文件
- 2紧密度皮尔逊相关系数
- 3建立聚类
- 4聚类
- 5绘制树状图
- 参考文献
引言
分级聚类通过连续不断地将最为相似的群组两两合并,来构造出一个群组的层级结构。其中的每个群组都是从单一元素开始的。在每次迭代的过程中,分级聚类算法会计算每两个群组间的距离,并将距离最近的两个群组合并成一个新的群组。这一过程会一直重复下去,直至只剩一个群组为止。 —– 摘自《集体智慧编程》
聚类过程
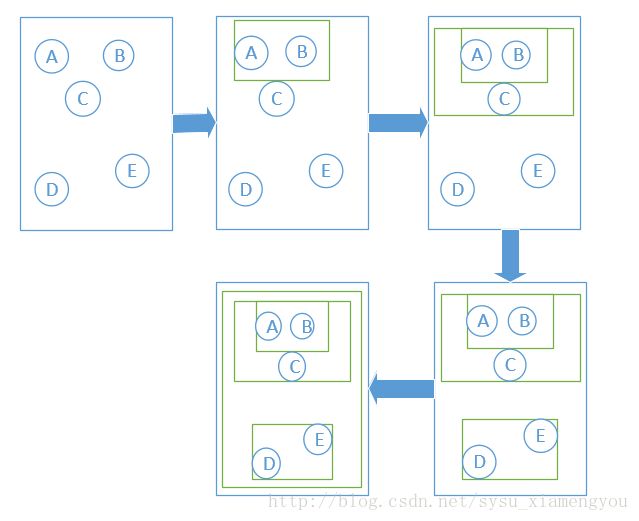
图1 分级聚类的过程
在上图中,元素的相似程度通过它们之间的距离来体现,距离越小,代表相似度越高(这里采用皮尔逊相关系数公式)。开始时,群组还只有一个元素,到第二步时,可以看见A和B两个相近的元素被聚类在一起,形成一个新的群组。关于新群组所在的位置确定有三种方法。
- 群组之间的距离取两个群组之间相隔较远的元素的距离为准,但这样会因为个别不合群的元素导致聚类时出现较大的误差。
- 群组之间的距离取两个群组之间相隔较近的元素的距离为准,这种方法同第一种方法相似,也会因为个别边缘化元素导致聚类出现较大偏差。
- 群组的位置取元素中间的位置,即是新群组的位置为两个旧群组中间的位置,这样不会因为个别元素而出现较大误差。
在第三步中,新群组又与C进行了合并。第四步中,D和E属于较近的元素,于是D和E合并成新群组,最后一步将剩下的两个群组合并在一起。
聚类实例
下面以一个实例来解释一下分级聚类的算法(数据来源:blogdata.txt在chapter3文件夹中)
首先,我们新建一个clusters.py的文件,作为一个解决问题的模型,然后将下述的函数代码都放入文件中。
1、读取文件
def readfile(filename):
lines = [line for line in open(filename)]
# 第一行是列标题
colnames = lines[0].strip().split('\t')[1:]
rownames = []
data = []
for line in lines[1:]:
p = line.strip().split('\t')
# 每行的第一列是列名
rownames.append(p[0])
# 剩余部分就是该行对应的数据
data.append([float(x) for x in p[1:]])
return rownames, colnames, data- 注意python2.7中的file()函数在python3版本以后替换成了open()函数
上述函数将数据集中的头一行数据读入了一个代表列名的colnames列表,并将最左边一列读入了一个代表行名的rownames列表,最后将剩下的所有数据都放入了一个大列表,其中的每一项对应于数据集中的一行数据。
2、紧密度——皮尔逊相关系数
欧几里德距离评价通过两群组元素之间的距离值来判断相关度,假如数据不是很规范的时候(例如,一个影评者对影评的评价总是相对于平均水平偏离很大时),欧几里得距离给出的评价是它们相关系数很小,但实际上它们是相关系数很高的群组。相比于欧几里德距离评价,皮尔逊相关系数通过判断两组数据与某一直线拟合程度来判断它们是否相关,数据不规范时,它可能会给出更好的结果。
from math import sqrt
def pearson(v1, v2):
sum1 = sum(v1)
sum2 = sum(v2)
sum1Sq = sum([pow(v, 2) for v in v1])
sum2Sq = sum([pow(v, 2) for v in v2])
pSum = sum([v1[i] * v2[i] for i in range(len(v1))])
num = pSum - ((sum1 * sum2) / len(v1))
den = sqrt((sum1Sq - pow(sum1, 2) / len(v1)) * (sum2Sq - pow(sum2, 2) / len(v1)))
if den == 0:
return 0.0
return 1.0 - num / den皮尔逊相关系数的计算结果在两者完全匹配的时候为1.0,两者毫无关系时为0.0。代码最后一行,用1.0减去皮尔逊相关度之后的结果,是为了让相似度越大的两个元素之间距离越小。
3、建立聚类
新建一个类,代表聚类这一类型:
class bicluster:
def __init__(self, vec, left=None, right=None, distance=0.0, id=None):
self.left = left
self.vec = vec
self.right = right
self.distance = distance
self.id = idvec代表建立新聚类的集合,left和right是建立新聚类的左右两个旧聚类,distance是这个聚类的距离,也即是两个旧聚类的皮尔逊相关系数,id用以代表这是一个分支还是叶节点。
4、聚类
分级聚类算法以一组对应于原始数据项的聚类开始。函数主体会通过两层嵌套循环尝试每一组可能的配对并计算他们的皮尔逊相关系数,以此找出当下最佳的配对,生成新的聚类。同时,两个旧聚类会被删除。这一过程会一直重复下去,直到只剩下一个聚类为止。
def hcluster(rows, distance=pearson):
distances = {}
currentclustid = -1
lowestpair = None
# 最开始的聚类就是数据集中的行
clusts = [bicluster(rows[i], id=i) for i in range(len(rows))]
while len(clust) > 1:
closest = distance(clusts[0].vec, clusts[1].vec)
# 遍历每一个配对,寻找最小距离
for i in range(len(clusts) - 1):
for j in range(i+1, len(clusts)):
# 用distances来缓存距离的计算值
if distances.get((clusts[i].id, clusts[j].id)) is None:
distances[(clusts[i].id, clusts[j].id)] = distance(clusts[i].vec, clusts[j].vec)
d = distances[(clusts[i].id, clusts[j].id)]
# 寻找最相似的两个群组
if d < closest:
closest = d
lowestpair = (i, j)
bic1, bic2 = lowestpair
# 计算两个聚类的平均值
mergevec = [((clusts[bic1].vec[i] + clusts[bic2].vec[i]) / 2.0) for i
in range(len(clusts[bic1].vec))]
# 建立新的聚类
newcluster = bicluster(mergevec, left=clusts[bic1], right=clusts[bic2], distance=closest,
id=currentclustid)
# 不在原始集合中的聚类,其id为负数
currentclustid -= 1
del clusts[bic2]
del clusts[bic1]
clusts.append(newcluster)
return clusts[0]因为每个聚类都指向构造该聚类时被合并的另两个聚类,所以我们可以用递归搜索由该函数最终返回的聚类,以及重建所有的聚类及叶节点(python中的del函数删除的只是变量,而不是数据,所以仍可以递归搜索到)。
5、绘制树状图
这次要用到PIL(Python Imaging Library)函数库,可以直接使用命令行pip install Pillow安装该库。
需要一个函数返回给定聚类的总体高度,如果聚类是一个叶节点,则其高度为1;否则为所有分支高度之和。
def getheight(clust):
# 这是一个叶节点吗?若是,则高度为1
if clust.left is None and clust.right is None:
return 1
# 否则,高度为每个分支的高度之和
return getheight(clust.left)+getheight(clust.right)然后,我们还需要知道根节点的总体误差,线条的长度会根据每个节点的误差进行相应的调整。
def getdepth(clust):
# 一个叶节点的距离是0.0
if clust.left is None and clust.right is None:
return 0
# 一个枝节点的距离等于左右两侧分支中距离较大者,加上该枝节点自身的距离
return max(getdepth(clust.left), getdepth(clust.right)) + clust.distance现在,我们根据聚类的大小创建一个高度为20像素、宽度固定的图片,其中缩放因子是由固定宽度除以总的深度值得到的。
from PIL import Image,ImageDraw
def drawdendprogram(clust, labels, jpeg='cluster.jpg'):
# 高度和宽度
h = getheight(clust) * 20
w = 1200
depth = getdepth(clust)
# 由于宽度是固定的,因此我们需要对距离值做相应的调整
scaling = float(w - 150) / depth
# 新建一个白色背景的图片
img = Image.new('RGB', (w, h), (255, 255, 255))
draw = ImageDraw.Draw(img)
draw.line((0, h/2, 10, h/2), fill=(255, 0, 0))
# 画第一个节点
drawnode(draw, clust, 10, (h/2), scaling, labels)
img.save(jpeg, 'JPEG')现在开始绘制节点了,水平线的长度是有聚类中的误差情况觉决定的。线条越长代表合并在一起的两个聚类差别很大,线条越短则表明两个聚类相似度很高。
def drawnode(draw, clust, x, y, scaling, labels):
if clust.id < 0:
h1 = getheight(clust.left) * 20
h2 = getheight(clust.right) * 20
top = y - (h1 + h2) / 2
bottom = y + (h1 + h2) / 2
# 线的长度
l1 = clust.distance * scaling
# 聚类到其子节点的垂直线
draw.line((x, top + h1 / 2, x, bottom - h2 / 2), fill=(255, 0, 0))
# 连接左侧节点的水平线
draw.line((x, top + h1 / 2, x + l1, top + h1 / 2), fill=(255, 0, 0))
# 连接右侧节点的水平线
draw.line((x, bottom - h2 / 2, x + l1, bottom - h2 / 2), fill=(255, 0, 0))
# 调用函数绘制左右节点
drawnode(draw, clust.left, x + l1, top + h1 / 2, scaling, labels)
drawnode(draw, clust.right, x + l1, bottom - h2 / 2, scaling, labels)
else:
# 如果这是一个叶节点,则绘制节点的标签
draw.text((x + 5, y - 7), labels[clust.id], (0, 0, 0))绘制出的图片如下图所示:

参考文献
[1].集体编程智慧. Toby Segaran 著,莫映、王开福译