web开发学习(5) - Django启动服务器源代码阅读
Django启动服务器命令,这边对相关源码的入口和流程做一下记录:
python manage.py runserver重点内容:
--wsgi.py文件中application对象--socket服务器响应请求的处理函数(HTTPRequestHandler) -- 位置可通过配置文件查到
--中间件请求处理集成工具的获取,请求处理的过程
--底层请求的处理过程_get_request() (定义于BaseHandler类中,目录: django/core/handlers/base.py)
1. 直接跳到django/core/management/__init__.py,从以下命令开始
self.fetch_command(subcommand).run_from_argv(self.argv)
#subcommand='runserver' self.fetch_command(subcommand)返回一个runserver.Command()对象2. runserver.py
目录:django/core/managment/commands/runserver.py
Command继承BaseCommand类,使用父类的初始化方法
options参数载入的来源:????
#文件 django/core/management/base.py
class BaseCommand:
#--部分代码省略--
def run_from_argv(self, argv):
self.execute(*args, **cmd_options) #执行子类代码
def execute(self, *args, **options):
#---部分代码省略---
output = self.handle(*args, **options) #执行父子类代码
if output:
if self.output_transaction:
connection = connections[options.get('database', DEFAULT_DB_ALIAS)]
output = '%s\n%s\n%s' % (
self.style.SQL_KEYWORD(connection.ops.start_transaction_sql()),
output,
self.style.SQL_KEYWORD(connection.ops.end_transaction_sql()),
)
self.stdout.write(output)
return output
#文件 django/core/management/commands/runserver.py
class Command(BaseCommand):
default_addr = '127.0.0.1' #注意全局变量的设置,后续可能有用
default_addr_ipv6 = '::1'
default_port = '8000'
protocol = 'http'
server_cls = WSGIServer
def execute(self, *args, **options): #执行此处代码
if options['no_color']:
# We rely on the environment because it's currently the only
# way to reach WSGIRequestHandler. This seems an acceptable
# compromise considering `runserver` runs indefinitely.
os.environ["DJANGO_COLORS"] = "nocolor"
super().execute(*args, **options) #跳回父类执行父类代码
def handle(self, *args, **options):
if not settings.DEBUG and not settings.ALLOWED_HOSTS:
raise CommandError('You must set settings.ALLOWED_HOSTS if DEBUG is False.')
self.use_ipv6 = options['use_ipv6'] #False
if self.use_ipv6 and not socket.has_ipv6:
raise CommandError('Your Python does not support IPv6.')
self._raw_ipv6 = False
if not options['addrport']:
self.addr = ''
self.port = self.default_port #self.port='8000'
else:
#--代码省略--
if not self.addr:
#--代码省略--
self.run(**options) #执行run()函数
def run(self, **options):
"""Run the server, using the autoreloader if needed."""
use_reloader = options['use_reloader']
if use_reloader:
autoreload.run_with_reloader(self.inner_run, **options) #最后执行到这里
else:
self.inner_run(None, **options)
3. autoreload.run_with_reloader()
目录:django/utils/autoreload.py
autoreload的作用是什么:python manage.py runserver命令是进入开发者模式,当我们在程序文件上做了修改之后,会重新自动加载进来,而不需要我们重启服务器。get_reloader()会返回一个WatchmanReloader对象(也就是用来监控我们更改程序文件的),
- 这边有一个控制线程的知识点,先跳过了(Threading.Event),这个WatchmanReloader和启动服务的主要函数inner_run一起传递给start_django()方法,在里面进行线程的切换
- 信号(signal)-- 进程之间通讯的方式,是一种软件中断。一个进程一旦接收到信号就会打断原来的程序执行流程来处理信号。
def run_with_reloader(main_func, *args, **kwargs):
signal.signal(signal.SIGTERM, lambda *args: sys.exit(0)) #当收到终止信号时,终止进程,难道ctrl+c就是在这里用的??
try:
if os.environ.get(DJANGO_AUTORELOAD_ENV) == 'true': #True
reloader = get_reloader()
logger.info('Watching for file changes with %s', reloader.__class__.__name__)
start_django(reloader, main_func, *args, **kwargs)
else:
exit_code = restart_with_reloader()
sys.exit(exit_code)
except KeyboardInterrupt:
pass
def get_reloader():
"""Return the most suitable reloader for this environment."""
try:
WatchmanReloader.check_availability() #看不懂,跳过
except WatchmanUnavailable:
return StatReloader()
return WatchmanReloader()
class WatchmanReloader(BaseReloader):
def __init__(self):
self.roots = defaultdict(set)
self.processed_request = threading.Event() #这个Event用来控制线程,现在暂时跳过
self.client_timeout = int(os.environ.get('DJANGO_WATCHMAN_TIMEOUT', 5))
super().__init__()4. start_django(reloader, main_func, *args, **kwargs)
启动服务器的主要功能在main_func,也就是inner_run()方法,所以这边先跳过了目录:django/utils/autoreload.py
def start_django(reloader, main_func, *args, **kwargs): #main_func() = inner_run()
ensure_echo_on()
main_func = check_errors(main_func)
django_main_thread = threading.Thread(target=main_func, args=args, kwargs=kwargs, name='django-main-thread')
django_main_thread.setDaemon(True) #设置为守护线程
django_main_thread.start()
while not reloader.should_stop:
try:
reloader.run(django_main_thread)
except WatchmanUnavailable as ex:
# It's possible that the watchman service shuts down or otherwise
# becomes unavailable. In that case, use the StatReloader.
reloader = StatReloader()
logger.error('Error connecting to Watchman: %s', ex)
logger.info('Watching for file changes with %s', reloader.__class__.__name__)
5. inner_run()方法
目录:django/core/management/commands/runserver.py
class Command(BaseCommand):
def inner_run(self, *args, **options):
#---部分代码省略---
threading = options['use_threading']
try:
handler = self.get_handler(*args, **options) #获得WSGI模块
run(self.addr, int(self.port), handler,
ipv6=self.use_ipv6, threading=threading, server_cls=self.server_cls)
except socket.error as e:
#----代码省略----
except KeyboardInterrupt:
#---代码省略----
def get_handler(self, *args, **options):
"""Return the default WSGI handler for the runner."""
return get_internal_wsgi_application() #返回默认的wsgi处理函数6. get_handler(self, *args, **options)
目录:django/core/servers/basehttp.py
加载并返回wsgi应用程序,加载的位置是从settings.WSGI_APPLICATION中获取(本地配置文件 : bootcamp/config/setting/base.py文件中,WSGI_APPLICATION = 'config.wsgi.application')
def get_internal_wsgi_application():
from django.conf import settings
app_path = getattr(settings, 'WSGI_APPLICATION') #获取WSGI.py文件中的字符串'config.wsgi.application'
if app_path is None:
return get_wsgi_application()
try:
return import_string(app_path) #相当于获得了WSGI模块吧
except ImportError as err:
raise ImproperlyConfigured(
"WSGI application '%s' could not be loaded; "
"Error importing module." % app_path
) from err7. 返回第五步
目录:django/core/management/commands/runserver.py
目录:django/core/servers/basehttp.py
这里的handler就是上一步获得的WSGI模块
执行方法:run(self.addr, int(self.port), handler, ipv6=self.use_ipv6, threading=threading, server_cls=self.server_cls)
这边的run函数与第2步的run函数可不是同一个哦,差点看错了
#文件 django/core/servers/basehttp.py
def run(addr, port, wsgi_handler, ipv6=False, threading=False, server_cls=WSGIServer): #server_cls=WSGIserver threading=True ipv6=False addr='127.0.0.1' port='8000'
server_address = (addr, port)
if threading:
#创建一个Socket服务器(继承类两个类:ThreadingMixIn和WSGIServer)
# class WSGIServer(socketserver.ThreadingMixIn,django.core.servers.basehttp.WSGIServer)
#加入ThreadingMixIn类,让socket服务器具备了多线程的行为
httpd_cls = type('WSGIServer', (socketserver.ThreadingMixIn, server_cls), {})
else:
httpd_cls = server_cls
#初始化参数应该还是传给WSGIServer
httpd = httpd_cls(server_address, WSGIRequestHandler, ipv6=ipv6) #sockek服务器初始化
if threading:
# ThreadingMixIn.daemon_threads indicates how threads will behave on an
# abrupt shutdown; like quitting the server by the user or restarting
# by the auto-reloader. True means the server will not wait for thread
# termination before it quits. This will make auto-reloader faster
# and will prevent the need to kill the server manually if a thread
# isn't terminating correctly.
httpd.daemon_threads = True
httpd.set_app(wsgi_handler)
httpd.serve_forever()8. Socket服务器初始化
执行:httpd = httpd_cls(server_address, WSGIRequestHandler, ipv6=ipv6)
对django.core.servers.basehttp.WSGIServer这个Socket服务器进行初始化
目录:django/core/servers/basehttp.py
class WSGIServer(simple_server.WSGIServer):
"""BaseHTTPServer that implements the Python WSGI protocol"""
request_queue_size = 10
def __init__(self, *args, ipv6=False, allow_reuse_address=True, **kwargs):
if ipv6:
self.address_family = socket.AF_INET6
self.allow_reuse_address = allow_reuse_address
super().__init__(*args, **kwargs) #还是要父类进行初始化跳到父类:simple_server.WSGIServer (没找到)
参考廖雪峰的官方网站-WSGI接口:https://www.liaoxuefeng.com/wiki/897692888725344/923057027806560
WSGI服务器是一个封装好的Socket的服务器,让我们可以避免考虑一些底层实现细节,WSGI服务器负责接收浏览器发来的请求,那接收到请求应该怎么做呢???我们如何预先定义好WSGI的响应行为呢?比如我发了一个某网页的请求,他是如何正确的返回我想要得HTML页面???
就是靠定义中的参数WSGIRequestHandler,也就是我们本地wsgi.py文件中的application对象,还记得怎么找到他吗,可以通过配置文件找到他的位置bootcomp/conf/settings/base.py,通过编写(参考:第6步)
9. wsgi.py文件
目录 :bootcamp/conf/settings/base.py,文件中的application对象,也就是传到socket服务器里的HTTPRequestHandler
"""
WSGI config for Bootcamp project. #可以根据不同需求配置
"""
import os
import sys
from django.core.wsgi import get_wsgi_application
app_path = os.path.abspath(os.path.join( #当前文件上一级目录
os.path.dirname(os.path.abspath(__file__)), os.pardir)) #os.path.abspath(__file__)获取当前文件wsgi.py的绝对路径
sys.path.append(os.path.join(app_path, 'bootcamp')) #将apps所在目录添加到系统路径
if os.environ.get('DJANGO_SETTINGS_MODULE') == 'config.settings.production': # 'config.settings.local'
from raven.contrib.django.raven_compat.middleware.wsgi import Sentry
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "config.settings.production")
application = get_wsgi_application() #最后到这里,也就是传到socket服务器里的HTTPRequestHandler
if os.environ.get('DJANGO_SETTINGS_MODULE') == 'config.settings.production':
application = Sentry(application)10. get_wsgi_application()
目录:django/core/wsgi.py
import django
from django.core.handlers.wsgi import WSGIHandler
def get_wsgi_application():
"""
The public interface to Django's WSGI support. Return a WSGI callable.
Avoids making django.core.handlers.WSGIHandler a public API, in case the
internal WSGI implementation changes or moves in the future.
"""
django.setup(set_prefix=False)
return WSGIHandler()11. WSGIHandler()
目录:django/core/handlers/wsgi.py
#django/core/handlers/wsgi.py
class WSGIHandler(base.BaseHandler):
request_class = WSGIRequest #定义了请求格式的类
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.load_middleware() #加载中间件到处理函数self._middleware_chain,我的理解这是多层的一个嵌套函数,初始化的主要工作就是把这个工具准备好
def __call__(self, environ, start_response): #__call__: 允许一个类的实例像函数一样被调用,处理请求的入口
set_script_prefix(get_script_name(environ))
signals.request_started.send(sender=self.__class__, environ=environ)
request = self.request_class(environ) #从系统环境中获取请求
response = self.get_response(request) #开始处理请求
#---其他代码暂时省略---12. 先梳理以下流程:
-
python manage.py runserver 命令过程中,初始化了一个实例对象WSGIHandler() ,并把该对象传给了WSGI服务器
初始化过程的主要目的是什么?
- 请求的初步处理,其实在WSGIHandler的父类方法_get_response()就已经完成了,可能是为了满足某种协议,需要进行增加或修改格式或信息,用到了一个集成处理工具_middleware_chain,初始化也是为了获得这个工具
- 在WSGIHandler中有个属性_middleware_chain = None,他其实是一个函数,集合了多个中间件的处理功能,用于将__get_retponse()得到reponse,逐步/逐层的进行一些处理
- 中间件在哪里(要把他加载进来),怎么把它集成到一起,这都是靠BaseHandler的load_middleware()来实现
conver_exception_to_response( ):对中间件处理过程添加异常处理方法,通过嵌套对实现每层的检查
for 循环:嵌套添加中间件处理功能,中间件的处理功能是通过调用MiddlewareMixin的__call__方法实现的
#文件 django/core/handlers/base.py
def load_middleware(self):
#----部分代码省略-----
self._exception_middleware = []
handler = convert_exception_to_response(self._get_response) #检查该层中间件/_get_repoponse处理过过程中的异常
for middleware_path in reversed(settings.MIDDLEWARE): #for循环实际定义了一个嵌套函数
middleware = import_string(middleware_path) #获得中间件对象
try:
mw_instance = middleware(handler) #通过for循环,不断的往handler集成工具中添加中间件的处理功能
except MiddlewareNotUsed as exc:
#代码省略
handler = convert_exception_to_response(mw_instance) #执行嵌套
self._middleware_chain = handler #将集成了多种中间件功能的函数绑定到WSGIHandler()实例对象上集成工具处理过程:从嵌套函数的最底层开始执行,逐层往上
- _get_response(request):继承工具从系统环境获得请求,检查处理过程异常,返回处理结果response,传给上一层
- mw_instance调用__call__,执行该层中间件的处理过程,期间检查处理异常,放回处理结果response,传给上一层
- 依此逐层进行....
#文件 django/middleware/common/CommonMiddleware
class CommonMiddleware(MiddlewareMixin):
#---省略部分代码---
def process_request(self, request):#代码省略
def process_response(self, request, response):#代码省略
#文件 django/utils/deprecation.py
class MiddlewareMixin:
def __init__(self, get_response=None):
self.get_response = get_response
super().__init__()
def __call__(self, request):
response = None
if hasattr(self, 'process_request'):
response = self.process_request(request)
response = response or self.get_response(request)
if hasattr(self, 'process_response'):
response = self.process_response(request, response)
return response
#文件 django/core/handlers/exception.py
def convert_exception_to_response(get_response): #好像定义了一个装饰器,看不懂,先跳过
@wraps(get_response)
def inner(request):
try:
response = get_response(request)
except Exception as exc:
response = response_for_exception(request, exc)
return response
return inner
-
WSGIHandler实例对象可以不断的从系统环境中获取到请求,执行__call__(),(WSGIHandler是可调用对象)
-- 再回到这个话题开始的地方,请求从哪里来?request=self.request_class(environ),它是一个WSGIRequest类
#文件 django/core/handlers/wsgi.py
class WSGIHandler(base.BaseHandler):
request_class = WSGIRequest #定义了请求格式的类
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.load_middleware() #加载中间件到处理函数self._middleware_chain,我的理解这是多层的一个嵌套函数,初始化的主要工作就是把这个工具准备好
def __call__(self, environ, start_response): #__call__: 允许一个类的实例像函数一样被调用,处理请求的入口
set_script_prefix(get_script_name(environ))
signals.request_started.send(sender=self.__class__, environ=environ)
request = self.request_class(environ) #从系统环境中获取请求
response = self.get_response(request) #开始处理请求
#---其他代码暂时省略---
return response #返回最终的结果
class WSGIRequest(HttpRequest):
def __init__(self, environ):
script_name = get_script_name(environ)
# If PATH_INFO is empty (e.g. accessing the SCRIPT_NAME URL without a
# trailing slash), operate as if '/' was requested.
path_info = get_path_info(environ) or '/'
self.environ = environ
self.path_info = path_info
# be careful to only replace the first slash in the path because of
# http://test/something and http://test//something being different as
# stated in https://www.ietf.org/rfc/rfc2396.txt
self.path = '%s/%s' % (script_name.rstrip('/'),
path_info.replace('/', '', 1))
self.META = environ
self.META['PATH_INFO'] = path_info
self.META['SCRIPT_NAME'] = script_name
self.method = environ['REQUEST_METHOD'].upper()
self.content_type, self.content_params = cgi.parse_header(environ.get('CONTENT_TYPE', ''))-- 执行父类BaseHandler的方法:self.get_response(request)
#文件 django/core/handlers/base.py
class BaseHandler:
#----部分代码省略----
_middleware_chain = None
def _get_response(self, request):#代码省略
def load_middleware(self):#代码省略
def get_response(self, request):
# Setup default url resolver for this thread
set_urlconf(settings.ROOT_URLCONF) #设置默认的url解析器,ROOT_URLCONF = 'config.urls'
response = self._middleware_chain(request) #上面说的请求处理集成工具来处理请求,其中第一步就是调用_get_response()方法进行初步处理
#---部分代码省略----
return response13. set_urlconf(settings.ROOT_URLCONF)
#文件 django/urls/base.py
_urlconfs = local() #关注以下
def set_urlconf(urlconf_name): #urlconf_name='config.urls' 表示位于bootcamp/config/urls.py
if urlconf_name:
_urlconfs.value = urlconf_name
else:
if hasattr(_urlconfs, "value"):
del _urlconfs.value14. _get_response()方法 (看不懂、待续。。。。。。)
#文件 django/core/handlers/base.py
def _get_response(self, request):
response = None
if hasattr(request, 'urlconf'): #False 在WSGIRequest和HTTPRequest类的定义中没有找到
urlconf = request.urlconf
set_urlconf(urlconf)
resolver = get_resolver(urlconf)
else:
resolver = get_resolver() #执行这里 return URLResolver(RegexPattern(r'^/'), urlconf)
#'config.urls’
resolver_match = resolver.resolve(request.path_info) #request.path_info表示请求的网址信息
callback, callback_args, callback_kwargs = resolver_match
request.resolver_match = resolver_match
#---部分代码省略---
return response
#文件 django/urls/resolvers.py
@functools.lru_cache(maxsize=None)
def get_resolver(urlconf=None):
if urlconf is None:
urlconf = settings.ROOT_URLCONF
return URLResolver(RegexPattern(r'^/'), urlconf) #urlconf='conf.urls'
#文件 django/urls/resolvers.py
class URLResolver:
def __init__(self, pattern, urlconf_name, default_kwargs=None, app_name=None, namespace=None):
self.pattern = pattern
self.urlconf_name = urlconf_name
#----部分代码省略-----
def resolve(self, path): #path表示客户端请求的网址信息
path = str(path) # path may be a reverse_lazy object
tried = []
match = self.pattern.match(path) #如请求是/users/, 正则表达式是r'^/'
if match:
new_path, args, kwargs = match #new_path=users/ args=() kwargs={}
for pattern in self.url_patterns:
#---代码省略-----执行语句:match = self.pattern.match(path)
self.pattern是一个RegexPattern类,执行match函数,并执行到match=self.regex.search(path)
#文件 django/urls/resolvers.py
class RegexPattern(CheckURLMixin):
regex = LocaleRegexDescriptor('_regex')
def __init__(self, regex, name=None, is_endpoint=False):
self._regex = regex #regex = r'^/'
#---代码省略---
def match(self, path):
match = self.regex.search(path) #执行到这里,相当于match=re.compile(r'^/').search(path)
if match:
#---代码省略----
def _compile(self, regex):
#代码省略--执行语句match=self.regex.search(path), 其中self.regex是LocaleRegexDescriptor,所以转到该类定义处:
但在类的定义中未找到search方法,但是定义了__get__(),由于找到search()找不到search方法,就触发了__get__()方法
如果class定义了它,则这个class就可以称为descriptor。instance是访问descriptor的实例,在本例中就是RegexPattern这个类实例对象,如果不是通过实例访问,而是通过类访问的话,instance则为None。(descriptor的实例自己访问自己是不会触发__get__,
以上关于__get__()方法参考:https://www.cnblogs.com/nyist-xsk/p/8288266.html
#文件 django/urls/resolvers.py
class LocaleRegexDescriptor:
def __init__(self, attr):
self.attr = attr # self.attr = '_regex'
def __get__(self, instance, cls=None): #instance就是RegexPattern实例对象
if instance is None:
return self
pattern = getattr(instance, self.attr) #pattern = RegexPattern._regex = r'^/'
if isinstance(pattern, str):
instance.__dict__['regex'] = instance._compile(pattern) #RegexPattern.regex=RegexPattern._compile(r'^/')
return instance.__dict__['regex']
#---代码省略------执行语句:instance.__dict__['regex'] = instance._compile(pattern),相当于执行
RegexPattern.regex = RegexPattern._compile(r'^/') 绕了一圈,又回到了RegexPattern类,再执行类中_compile()方法后,self.regex被覆盖,变为执行 re.compile(regex),由此也获得search()方法:
#文件 django/urls/resolvers.py
class RegexPattern(CheckURLMixin):
#---部分代码省略----
regex = LocaleRegexDescriptor('_regex')
def __init__(self, regex, name=None, is_endpoint=False):
self._regex = regex #regex = r'^/'
def match(self, path):
match = self.regex.search(path) #match=re.compile(r'^/').search(path)
if match:
kwargs = match.groupdict() #kwargs={}
args = () if kwargs else match.groups() #args=()
return path[match.end():], args, kwargs #match.end():被配到的字符串在原字符串中的位置
return None
def _compile(self, regex):
"""Compile and return the given regular expression."""
try:
return re.compile(regex)
except re.error as e:
raise ImproperlyConfigured(
'"%s" is not a valid regular expression: %s' % (regex, e)
)--再回到URLResolver类的 resolve()方法:
#文件 django/urls/resolvers.py
class URLResolver:
def __init__(self, pattern, urlconf_name, default_kwargs=None, app_name=None, namespace=None):
self.pattern = pattern #URLResolver(RegexPattern(r'^/'), urlconf)
self.urlconf_name = urlconf_name # 'config.urls'
def resolve(self, path):
path = str(path) # path may be a reverse_lazy object
tried = []
match = self.pattern.match(path) #如果path是 /users/
if match:
new_path, args, kwargs = match #new_path = users/ args=() kwargs={}
for pattern in self.url_patterns:
#---代码省略---
@cached_property
def urlconf_module(self):
if isinstance(self.urlconf_name, str):
return import_module(self.urlconf_name) #
else:
return self.urlconf_name
@cached_property
def url_patterns(self):
patterns = getattr(self.urlconf_module, "urlpatterns", self.urlconf_module) #获得在bootcamp/config/urls.py 文件中的urlpatterns参数(是一个列表)
try:
iter(patterns)
except TypeError:
#---代码省略---
return patternsbootcamp/config/urls.py文件中内容如下:
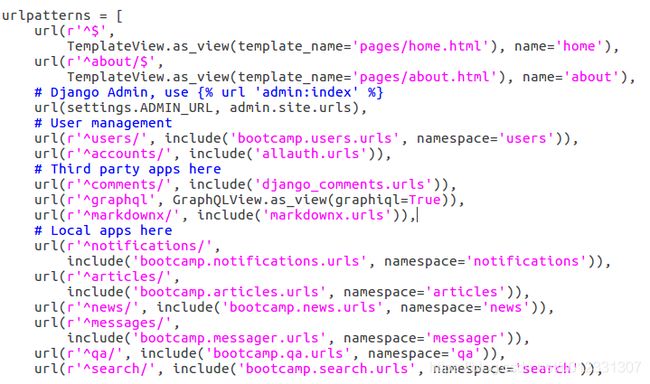
-- 继续URLResolver类的 resolve()方法:
#文件 django/urls/resolvers.py
class URLResolver:
def __init__(self, pattern, urlconf_name, default_kwargs=None, app_name=None, namespace=None):
self.pattern = pattern #URLResolver(RegexPattern(r'^/'), urlconf)
self.urlconf_name = urlconf_name # 'config.urls'
def resolve(self, path):
path = str(path) # path may be a reverse_lazy object
tried = []
match = self.pattern.match(path) #如果path是 /users/ RegexPattern(r'^/')
if match:
new_path, args, kwargs = match #new_path = users/ args=()
for pattern in self.url_patterns: #遍历urlpatterns列,定义在bootcamp/config/urls.py文件中
try:
sub_match = pattern.resolve(new_path) #相当于url(...).resolve(new_path)
except Resolver404 as e:
else:
#---代码省略---
raise Resolver404({'tried': tried, 'path': new_path})
raise Resolver404({'path': path})--执行语句: sub_match = pattern.resolve(new_path) ,相当于执行 url(...).resolve(new_path)
以这个为例: url(r'^$',TemplateView.as_view(template_name='pages/home.html'), name='home'),
#文件 django/urls/__init__.py
def url(regex, view, kwargs=None, name=None):
return re_path(regex, view, kwargs, name)
#文件 django/urls/conf.py
from functools import partial
re_path = partial(_path, Pattern=RegexPattern) #偏函数,设置默认参数 Pattern=RegexPattern
def _path(route, view, kwargs=None, name=None, Pattern=None): #route=r'^$'
if isinstance(view, (list, tuple)): #如果是用include包含的另一个urls.py文件中的url列表,则执行改代码块
# For include(...) processing.
pattern = Pattern(route, is_endpoint=False)
urlconf_module, app_name, namespace = view
return URLResolver(
pattern,
urlconf_module,
kwargs,
app_name=app_name,
namespace=namespace,
)
elif callable(view): # 如果不是列表,则执行这里,简单的情况:view='views.index' 表示文件views.py文件中的index函数
#TemplateView.as_view(template_name='pages/home.html'),这样的写法想相当与取消了MTV中的view层,不知道好坏,先跳过
pattern = Pattern(route, name=name, is_endpoint=True) #route=r'^$'
return URLPattern(pattern, view, kwargs, name) #pattern=RegexPattern(r'^$',name,is_endpoint=True)
else:
raise TypeError('view must be a callable or a list/tuple in the case of include().')--再继续URLResolver类的 resolve()方法: sub_match = pattern.resolve(new_path),由上面的分析可知,这边的pattern,也就是url函数的返回值
url函数返回一个URLPattern类,该类包含了urls.py中的关于url以及view等的信息,他将通过resove()方法,与new_path的也就是客户端发送的请求网址(比如users/),进行匹配
URLPattern(pattern, view, kwargs, name) #pattern=RegexPattern(r'^$',name,is_endpoint=True)
#文件 django/urls/resolvers.py
class URLPattern:
def __init__(self, pattern, callback, default_args=None, name=None):
self.pattern = pattern #pattern=r'^$'
self.callback = callback # the view
self.default_args = default_args or {}
self.name = name #name='home'
def resolve(self, path):
match = self.pattern.match(path) #path=http://localhost:8000/ 即客户端请求
if match:
new_path, args, kwargs = match
# Pass any extra_kwargs as **kwargs.
kwargs.update(self.default_args)
return ResolverMatch(self.callback, args, kwargs, self.pattern.name, route=str(self.pattern))
#文件 django/urls/resolvers.py
class ResolverMatch:
def __init__(self, func, args, kwargs, url_name=None, app_names=None, namespaces=None, route=None):
self.func = func #self.func对应view视图
self.args = args #{}
self.kwargs = kwargs #{}
self.url_name = url_name #‘home’
self.route = route #urls.py文件中的路径 #pattern=r'^$'
#----部分代码省略------再继续URLResolver类的 resolve()方法:
#文件 django/urls/resolvers.py
class URLResolver:
def __init__(self, pattern, urlconf_name, default_kwargs=None, app_name=None, namespace=None):
self.pattern = pattern #URLResolver(RegexPattern(r'^/'), urlconf)
self.urlconf_name = urlconf_name # 'config.urls'
def resolve(self, path):
path = str(path) # path may be a reverse_lazy object
tried = []
match = self.pattern.match(path) #如果path是 /users/ RegexPattern(r'^/')
if match:
new_path, args, kwargs = match #new_path = users/ args=()
for pattern in self.url_patterns: #遍历urlpatterns列,定义在bootcamp/config/urls.py文件中
try:
sub_match = pattern.resolve(new_path) #url函数的返回值,也就是这里pattern,是一个类URLPattern(pattern, view, kwargs, name) #pattern=RegexPattern(r'^$',name,is_endpoint=True)
#sub_match是ResolverMatch类型
except Resolver404 as e:
sub_tried = e.args[0].get('tried')
if sub_tried is not None:
tried.extend([pattern] + t for t in sub_tried)
else:
tried.append([pattern])
else:
if sub_match:
# Merge captured arguments in match with submatch
sub_match_dict = {**kwargs, **self.default_kwargs} # {{},{}}
# Update the sub_match_dict with the kwargs from the sub_match.
sub_match_dict.update(sub_match.kwargs) #groupdict()
# If there are *any* named groups, ignore all non-named groups.
# Otherwise, pass all non-named arguments as positional arguments.
sub_match_args = sub_match.args #groups()
if not sub_match_dict:
sub_match_args = args + sub_match.args
current_route = '' if isinstance(pattern, URLPattern) else str(pattern.pattern)
return ResolverMatch(
sub_match.func,
sub_match_args,
sub_match_dict,
sub_match.url_name,
[self.app_name] + sub_match.app_names,
[self.namespace] + sub_match.namespaces,
self._join_route(current_route, sub_match.route),
)
raise Resolver404({'tried': tried, 'path': new_path})
raise Resolver404({'path': path})返回 _get_response()方法主程序
resolver_match = resolver.resolve(request.path_info) ,方法接收到客户端网址请求,通过与config/urls.py文件(wei)中urlspatterns逐一匹配,并返回视图view函数,url_name参数
#文件 django/core/handlers/base.py
def _get_response(self, request):
response = None
if hasattr(request, 'urlconf'): #False 在WSGIRequest和HTTPRequest类的定义中没有找到
urlconf = request.urlconf
set_urlconf(urlconf)
resolver = get_resolver(urlconf)
else:
resolver = get_resolver() #执行这里 return URLResolver(RegexPattern(r'^/'), urlconf)
#'config.urls’
resolver_match = resolver.resolve(request.path_info) #request.path_info表示请求的网址信息
callback, callback_args, callback_kwargs = resolver_match #callback就是view视图函数
request.resolver_match = resolver_match
# Apply view middleware
for middleware_method in self._view_middleware:
response = middleware_method(request, callback, callback_args, callback_kwargs)
if response:
break
if response is None: #代码省略
if response is None: #代码省略
elif hasattr(response, 'render') and callable(response.render):
#代码省略
return response15. 执行视图函数
_view_middleware是什么时候加进来的?是在WSGIHandler初始化的时候,执行self.load_middleware,这边不做展开了
for middleware_method in self._view_middleware:
response = middleware_method(request, callback, callback_args, callback_kwargs)
if response:
break就到这吧。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
还有个问题:用户输入了网址,服务器也返回页面,那之后,不输入网址了,改按纽了,数据库-服务器-浏览又是如何交互的呢?