企业实战_09_Mycat 跨分片查询_全局表
| 垂直拆分根据业务模块把数据库划分独立出来,来矫情数据库的总体带来的压力! |
接上一篇:企业实战_08_Mycat清除冗余数据
https://blog.csdn.net/weixin_40816738/article/details/100057317
Mycat 跨分片查询_全局表
| 主机名 | IP地址 | 角色 | 数据库 |
|---|---|---|---|
| mycat | 192.168.43.32 | MYCAT MYSQL | imooc_db(物理主机) |
| node1 | 192.168.43.104 | MYSQL | order_db(物理从机) |
| node2 | 192.168.43.217 | MYSQL | product_db(物理从机) |
| node3 | 192.168.43.172 | MYSQL | customer_db(物理从机) |
文章目录
- 一、跨分片查询验证
- 1.1. 在node3上登录mycat
- 1.2. 使用逻辑数据库
- 1.3. 执行跨分片查询
- 1.4. 异常信息,问题定位
- 1.5. 表分布
- 1.6. 跨分片查询的解决方式
- 1.7. 场景分析
- 二、企业实战跨分片查询
- 2.1. 基础操作(熟悉即可)
- 2.2. node1节点操作
- 2.3. node2节点操作
- 2.4. node3节点操作
- 2.5. MyCat节点操作
- 2.6. 重启MyCat使配置生效
- 2.7. 再次跨分页查询验证
- 三、修改全局表数据同步从机数据验证
- 3.1. 登录MyCat修改全局表数据,验证是否可以同步到其他3个数据节点中
- 3.2. 登录node1节点
- 3.3. 登录node2节点
- 3.4. 登录node3节点
- 四、主从复制到MyCat总结
- 4.1. 数据库架构升级持之分库
- 4.2. 为什么数据库要进行垂直拆分?
- 4.2.1. 优点
- 4.2.2. 缺点
- 4.3. 解决跨分片关联的方式
一、跨分片查询验证
1.1. 在node3上登录mycat
mysql -uapp_imooc -p123456 -h192.168.43.32 -P8066
1.2. 使用逻辑数据库
use imooc_db;
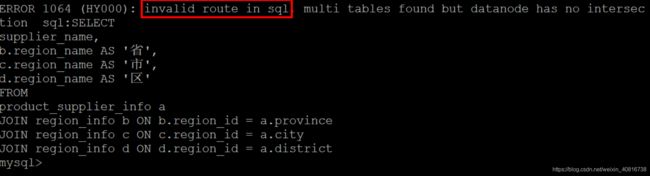
1.3. 执行跨分片查询
SELECT
supplier_name,
b.region_name AS '省',
c.region_name AS '市',
d.region_name AS '区'
FROM
product_supplier_info a
JOIN region_info b ON b.region_id = a.province
JOIN region_info c ON c.region_id = a.city
JOIN region_info d ON d.region_id = a.district;
1.4. 异常信息,问题定位
ERROR 1064 (HY000): invalid route in sql, multi tables found but datanode has no intersection sql
1.5. 表分布
| 表 | 节点 |
|---|---|
| region_info | node1 |
| product_supplier_info | node2 |
| 针对这种情况应该如何处理呢? |
1.6. 跨分片查询的解决方式
| 方式 | 说明 |
|---|---|
| api方式 | 通过前端程序,去订单模块中分别获取省市区的信息,之后拼接在一起 |
| 数据冗余的方式 | 把这些省市区的信息冗余到商品模块的供应商表中 |
| 全局表 | 字典表跨分片操作 |
1.7. 场景分析
- 字典类的表:
如果通过api方式,查询的频率比较高,api调取的次数也会很高,而且通过前台程序,api调用再去拼接,比较耗时。
如果通过数据冗余方式,这个数据的冗余度比较大,字段不多还好说,针对字段比较多的字典表的话,一旦修改的话,我们就要修改和字段表相关的表,因此,字典类型的不适用api和数据冗余的方式进行处理。
MyCat提供的全局表的功能,在每个分片上都会有这个全局表,也就是说,我们会把region_info这个表以相同的数据,存储到这3个数据节点中,然后再schema.xml中声明全局表。
二、企业实战跨分片查询
2.1. 基础操作(熟悉即可)
| 步骤 | 命令 | 说明 |
|---|---|---|
| 第一步 | mysql -uroot -p product_db < region_info | 将region_info 数据导入到product_db数据库中 |
| 第二步 | mysqldump -uroot -p order_db region_info > region_info | 导出备份region_info表 |
| 第二步 | scp region_info [email protected]:/root | 将region_info 表以root用户同步到ip为192.x服务器的root目录下面 |
2.2. node1节点操作
#在node1上导出备份region_info表
mysqldump -uroot -p order_db region_info > region_info
#复制到node2上
scp region_info [email protected]:/root
#复制到node3上
scp region_info [email protected]:/root
2.3. node2节点操作
#将region_info 数据导入到product_db数据库中
mysql -uroot -p product_db < region_info
2.4. node3节点操作
#将region_info 数据导入到customer_db数据库中
mysql -uroot -p customer_db< region_info
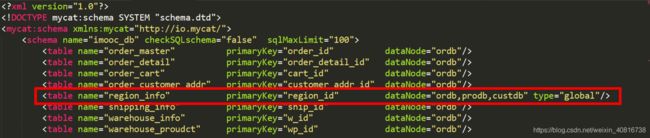
2.5. MyCat节点操作
#进入mycat的conf目录下面
cd /app/mycat/conf/
#编辑schema.xml文件
vim schema.xml
#将region_info逻辑表,定义为全局表
2.6. 重启MyCat使配置生效
#停止mycat
mycat stop
#启动mycat
mycat start
2.7. 再次跨分页查询验证
#使用mysql客户端连接mycat
mysql -uapp_imooc -p123456 -h192.168.43.32 -P8066
#验证跨分片查询
#执行跨分片查询
SELECT
supplier_name,
b.region_name AS '省',
c.region_name AS '市',
d.region_name AS '区'
FROM
product_supplier_info a
JOIN region_info b ON b.region_id = a.province
JOIN region_info c ON c.region_id = a.city
JOIN region_info d ON d.region_id = a.district;

三、修改全局表数据同步从机数据验证
3.1. 登录MyCat修改全局表数据,验证是否可以同步到其他3个数据节点中
#使用mysql客户端连接mycat
mysql -uapp_imooc -p123456 -h192.168.43.32 -P8066
#使用逻辑库
use imooc_db;
#查看全局表数据
select * from region_info limit 10;
#更新全局表数据
update region_info set region_name='中国' where region_id=1;
#更新后,再次查看全局表数据
select * from region_info limit 10;

注:mysql更新数据库失败 --read-only 请进入传送门:
https://blog.csdn.net/weixin_40816738/article/details/100059688
3.2. 登录node1节点
- 在登录mycat节点修改全局表数据后,查看node1节点的数据是否被更新
#登录数据库
mysql -uroot -p
#使用指定数据
use order_db;
#更新后,再次查看全局表数据
select * from region_info limit 10;
发现通过登录mycat节点修改全局表数据,node1节点的数据已经更新

3.3. 登录node2节点
- 查看在登录mycat节点修改全局表数据,node2节点的数据是否被更新
#登录数据库
mysql -uroot -p
#使用指定数据
use product_db;
#更新后,再次查看全局表数据
select * from region_info limit 10;
发现通过登录mycat节点修改全局表数据,node1节点的数据已经更新
3.4. 登录node3节点
- 查看在登录mycat节点修改全局表数据,node3节点的数据是否被更新
#登录数据库
mysql -uroot -p
#使用指定数据
use customer_db;
#更新后,再次查看全局表数据
select * from region_info limit 10;
发现通过登录mycat节点修改全局表数据,node1节点的数据已经更新
四、主从复制到MyCat总结
4.1. 数据库架构升级持之分库
①切换应用通过MyCat连接数据库
②删除不属于本模块的表
| 此场景验证Mysql主从复制到垂直拆分的演化。 由一开始有MySql主机主从复制方式,到由MyCat来控制后台的MySql主机--->>>垂直拆分场景 |
4.2. 为什么数据库要进行垂直拆分?
思路:优缺点出发
4.2.1. 优点
①数据库的拆分简单明了,拆分规则明确
②应用程序模块清晰明确,整合容易
③数据维护,简单易行,容易定位
4.2.2. 缺点
①部分表关联无法在数据库完成级别完成,需要在程序中完成
②对于访问比较频繁且数据量超大的表仍然存在性能瓶颈
③切分达到一定程度后,扩展性会遇到限制
4.3. 解决跨分片关联的方式
①适应MyCat全局表
②冗余部分关联数据
③使用API的方式获取数据
下一篇:企业实战_10_Mycat 水平扩展_分库分表
https://blog.csdn.net/weixin_40816738/article/details/100059793