CREST: Convolutional Residual Learning for Visual Tracking ---- 文献翻译理解
Abstract
鉴别相关滤波器(DCFs)在视觉跟踪中表现出良好的性能。他们只需要从初始帧中提取一小组训练样本来生成外观模型。然而,现有的DCFs分别从特征提取中学习滤波器,并使用经验加权的移动平均操作更新这些滤波器。DCF跟踪器很难从端到端的培训中受益。本文提出了将DCFs重构为单层卷积神经网络的算法。该方法将特征提取、响应图生成和模型更新集成到神经网络中进行端到端训练 为了减少在线更新过程中模型的退化,我们利用残差学习来考虑外观变化。在基准数据集上的大量实验表明,我们的波峰跟踪器性能优于最先进的跟踪器。
1. Introduction
视觉跟踪有多种应用,从视频监控、人机交互到自动驾驶。主要的困难是如何利用极其有限的训练数据(通常是第一帧中的一个边界框)来开发一个外观模型,以应对各种挑战,包括背景杂波、尺度变化、运动模糊和部分遮挡。鉴别相关滤波器(Discriminative correlation filters, DCFs)由于其以下两个重要特性,越来越受到跟踪界的关注[4,8,30]。首先,由于空间相关性通常是在傅里叶域中以元素乘积的形式计算的,所以DCFs适合于快速跟踪。其次,DCFs将输入特性的循环移位版本转换为软标签,即,由从0到1的高斯函数生成。与现有的在采样点上生成稀疏响应分数的跟踪检测方法[22,1,14,34]相比,DCFs总是在所有搜索点上生成稠密的响应分数。利用深度卷积特性[25],基于DCFs的跟踪算法[30,8,11]在最近的跟踪基准数据集上取得了最先进的性能[45,46,24]。
 图1:卷积特征改善了DCFs (DeepSRDCF [8], CCOT [11], HCFT[30])。我们提出了CREST算法,将DCFs表示为带有残差学习的浅卷积层。与现有的具有卷积特性的DCFs相比,它的性能更好
图1:卷积特征改善了DCFs (DeepSRDCF [8], CCOT [11], HCFT[30])。我们提出了CREST算法,将DCFs表示为带有残差学习的浅卷积层。与现有的具有卷积特性的DCFs相比,它的性能更好
然而,现有的基于DCFs的跟踪算法受到两个方面的限制。首先,学习DCFs与特征提取无关。虽然像[30,8,11]中那样通过深度卷积特性直接学习DCFs很简单,但是DCFs跟踪器从端到端的培训中获益甚微。其次,大多数DCFs跟踪器使用线性插值操作随时间更新所学习的过滤器。这种经验插值权值不太可能在模型自适应性和稳定性之间取得良好的平衡。由于有噪声的更新,它会导致DCFs跟踪器漂移。这些局限性提出了两个问题:(1)具有特征表示的DCFs是否可以端到端建模;(2)相对于使用线性插值等经验操作,DCFs是否可以更有效地更新?
针对这两个问题,我们提出了一种卷积残差学习算法(CREST)。我们将DCFs解释为深度神经网络中卷积滤波器的对偶。基于这一思想,我们将DCFs重新定义为单层卷积神经网络,直接生成响应图作为连续两帧之间的空间相关性。利用该公式,通过预先训练好的CNN模型(如VGGNet[38])提取特征,生成相关响应图,更新模型,有效地集成到端到端的表单中。空间卷积运算的功能类似于循环移位输入与相关滤波器之间的点积。它通过直接在空间域进行卷积来消除傅里叶变换中的边界效应。此外,卷积层是完全可微的。它允许使用反向传播更新卷积过滤器。与DCFs类似,卷积层以一次通过的方式在所有搜索位置生成密集的响应分数。为了正确地更新我们的模型,我们使用残差学习[15]来捕获外观变化,检测这个卷积层的输出与ground truth软标签之间的差异。这有助于缓解由噪声更新引起的模型快速退化。同时,残差学习有助于对较大的外观变化做出目标响应的鲁棒性。消融研究(5.2节)表明,提出的卷积层相对于最先进的DCFs跟踪器表现良好,而残差学习方法进一步提高了准确性
这项工作的主要贡献如下:
- 我们将相关滤波器重新定义为一个卷积层。它将特征提取、响应生成和模型更新集成到卷积神经网络中进行端到端训练。
- 我们应用残差学习来捕捉目标在时空框架下的外观变化。这有效地缓解了由于大量外观变化而导致的模型快速退化。
- 我们在大规模序列的基准数据集上对我们的方法进行了广泛的验证。我们表明,我们的波峰跟踪器表现良好,反对最先进的跟踪器。
2. Related Work
文献[47,37,39]对视觉跟踪进行了广泛的调查。在本节中,我们主要讨论基于相关滤波器和CNNs的跟踪方法。
相关滤波器跟踪。由于傅里叶域的计算效率,用于视觉跟踪的相关滤波器受到了广泛的关注。基于相关滤波器的跟踪方法将所有循环移位的输入特征回归到高斯函数。它们不需要多个目标外观样本。MOSSE跟踪[4]通过自适应相关滤波器对目标外观进行编码,优化输出误差平方和。已经提出了几个扩展来考虑提高跟踪精度。这些例子包括:kernelized correlation filters [17], multiple dimensional features [12, 18], context learning [49], scale estimation [7], re-detection [31], subspace learning [28], shortterm and term memory [20], reliable collection [27]
以及空间正则化[9]。不同于现有的在傅里叶域中将相关运算表示为元素乘的相关滤波器框架,我们将相关滤波器表示为空间域的卷积运算。它由CNN中的一个卷积层表示。从这个意义上说,我们证明了特征提取、响应生成和模型更新可以集成到一个网络中进行端到端预测和优化。
由cnn跟踪。视觉表征对于视觉跟踪非常重要。现有的CNN跟踪器主要研究预训练的目标识别网络,建立在判别或回归模型上。鉴别跟踪方法提出多个粒子,通过在线分类进行细化。其中包括叠加去噪自编码器[44]、增量学习[26]、支持向量机分类[19]和全连通神经网络[33]。这些区别跟踪器需要辅助的训练数据以及离线的预训练。另一方面,基于回归的方法通常将CNN特征回归为软标签(例如,二维高斯分布)。他们专注于将卷积特性与传统的DCF框架集成。这些例子包括层次卷积特征[30]、自适应模糊[36]、空间正则化[8]和连续卷积运算[11]。此外,还有基于CNN的卷积特征[42]选择和[43]顺序更新的方法。此外,暹罗网络因其两种完全相同的流结构而受到越来越多的关注。其中包括目标验证[40]跟踪、相关[3]跟踪和位置轴预测[16]跟踪。此外,还对递归神经网络(RNN)进行了研究,以方便跟踪对象验证[6]。与现有框架不同的是,我们应用残差学习来捕获当前框架和ground-truth(初始框架)之间的预测响应映射的差异。这有助于考虑外观变化,并有效地减少由噪声更新引起的模型退化。

3.卷积残差学习
我们的CREST算法通过底层和剩余层进行特征回归。该基层由一个卷积层组成,该卷积层被表示为传统的DCFs。通过残差层捕获基层输出与ground truth软标签之间的差异。图2显示了CREST管道。细节将在下面讨论。
3.1. DCF Reformulation
我们重新讨论了基于DCF的框架,并将其作为我们的基础层。DCFs学习一个判别分类器,通过搜索响应图中的最大值来预测目标翻译。我们用X表示输入样本,用Y表示相应的高斯函数标号。然后通过求解以下最小化问题学习相关滤波器W: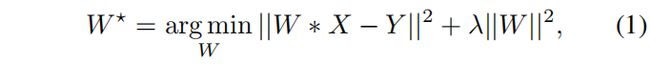
其中λ是正则化参数。通常,相关滤波器W和输入X之间的卷积运算被表述为傅里叶域中的点积[17,31,18]。
我们将DCFs的学习过程重新表述为卷积神经网络的损耗最小化。损失函数[21]的一般形式为:
其中N为样本数,LW (X(i)) (i∈N)为第i个样本的损失,r(W)为权值衰减。令N = 1,令L2范数为r(W)式2中的损失函数可表示为: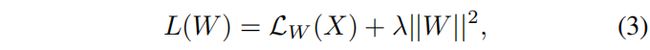
其中LW (X) = ||F(X)−Y ||2。它等价于F(X)和Y之间的L2损耗,其中F(X)是网络输出,Y是ground truth label。我们将F(X) = W∗X作为对X的卷积运算,它可以通过一个卷积层实现。卷积滤波器W等价于相关滤波器,式3中的损失函数等价于DCFs目标函数。因此,我们将DCFs表示为一个以L2损耗为目标函数的卷积层。它被命名为我们网络中的基础层。它的过滤器大小被设置为覆盖目标对象。利用梯度下降法代替封闭解[18]可以有效地计算卷积权值.
3.2. Residual Learning

我们将DCFs表示为一个基层,基层由一个卷积层表示。理想情况下,来自基础层输出的响应映射将与ground truth软标签相同。在实践中,单层网络不太可能做到这一点。我们使用残差学习来有效地捕捉基层输出与地面真值之间的差异,而不是将更多的层叠加在一起而导致退化问题[15]
图3显示了基础层和剩余层的结构。我们用H(X)表示输入X的最优映射,用FB(X)表示基层的输出。我们期望这些层近似残差函数FR(X) = H(X)−FB(X),而不是叠加更多层来近似H(X)。因此,我们期望的网络输出可以表示为:
其中FB(X) = WB∗X.映射FR(X,{WR})代表剩余学习,WR是卷积层的一般形式,为了简化标记而省略了ReLU[32]。在残差学习中,我们采用了三层结构,滤光片尺寸较小。它们被设置为捕获未在基层输出中显示的残差。最后,通过基和残差对输入X进行回归映射生成输出响应映射.
此外,我们还可以利用时间残差来捕捉空间残差无效时的差异。提出了一种与空间剩余学习结构相似的时间剩余学习网络。时间输入从包含初始对象外观的第一帧中提取。让Xt表示在坐标系t上的输入X,就得到

其中FT R(X1)为第一帧的时间残差。提出的时空剩余学习过程将难以捉摸的对象表示编码到响应图生成框架中,不需要额外的数据来训练网络。
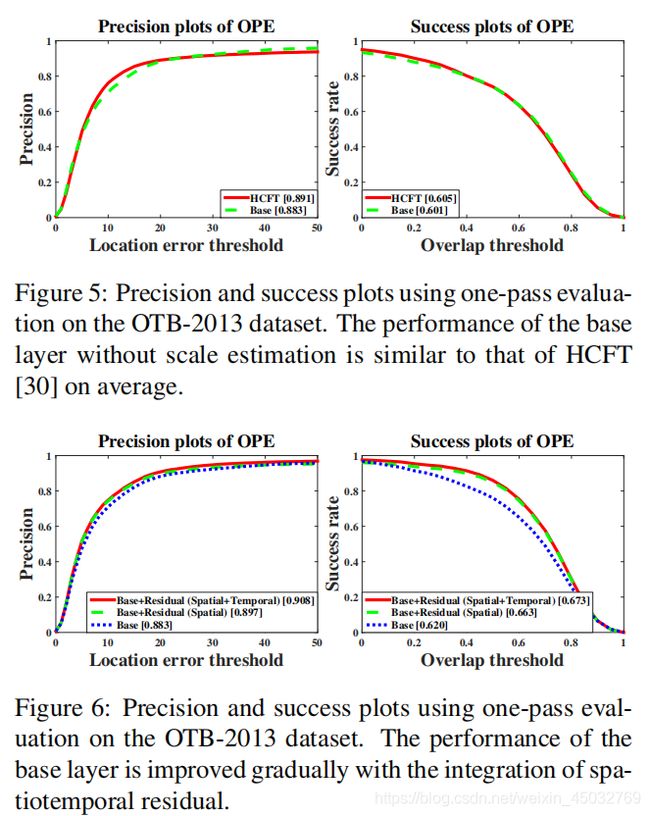
图4显示了来自基础层和剩余层的过滤器响应示例。对特征图进行缩放以实现可视化。给定一个输入图像,我们首先裁剪以前一帧估计位置为中心的搜索补丁。该补丁被发送到我们的特征提取网络中,然后通过基本层和剩余层回归到响应映射中。我们观察到,在预测响应图时,基础层的表现与传统的基于DCF的跟踪器相似。当目标物体发生微小的外观变化时,基层输出与地面真实值之间的差异很小。剩余层对最终响应图影响不大。然而,当目标物体出现较大的外观变化时,如背景杂波,来自底层的响应是有限的,可能无法区分目标和背景。然而,由于残差层的存在,这一限制得到了缓解,残差层有效地模拟了基层输出与地面真值之间的差异。通过添加基层和剩余层,有助于降低最终输出的噪声响应值。因此,目标响应对较大的外观变化更健壮。
4. Tracking via CREST
给出了视觉跟踪的具体过程。由于不需要离线训练,我们通过模型初始化、在线检测、尺度估计和模型更新等方面来展示跟踪过程。
模型初始化。给定一个目标位置的输入帧,提取一个以目标对象为中心的训练patch。这个补丁被发送到我们的框架中进行特征提取和响应映射。我们采用VGG网络[38]进行特征提取。同时,对基层和剩余层的所有参数按照零均值高斯分布进行随机初始化。我们的基本层和剩余层在几个步骤之后就被很好地初始化了。
在线检测。在线检测方案简单明了。当新的帧出现时,我们从前一帧预测的中心位置提取搜索补丁。搜索补丁的大小与训练补丁相同,并输入到我们的框架中以生成响应图。一旦有了响应映射,就可以通过搜索最大响应值来定位对象
规模估计。得到目标中心位置后,提取不同尺度的搜索patch。然后将这些补丁调整为一个固定大小的训练补丁。因此,不同尺度的候选对象大小都是标准化的。我们将这些补丁发送到网络中以生成响应映射。目标物体在第t帧的宽度wt和高度ht更新为:
![]()
w⋆t和h⋆t宽度和高度缩放对象的最大响应值。权重系数β 允许平滑更新目标大小。
模型更新。在线跟踪期间,我们始终生成培训数据。对于每一帧,在预测目标位置后,我们可以生成相应的ground truth response map,并且可以直接使用搜索patch作为训练patch。从每个T帧收集的训练补丁和响应图作为训练对,并将其输入我们的网络进行在线更新。
5. 实验
在本节中,我们将介绍实现细节,并分析包括基础层和剩余层在内的每个组件的效果。然后,我们比较我们的波峰跟踪器与最先进的跟踪器的基准数据集的性能评估
5.1 实验设置
实现细节。我们从第一帧获取训练补丁。它是物体宽度和高度最大值的5倍。我们的特征提取网络来自于VGG-16[38],只保留了前两个池化层。我们从conv4-3层中提取特征映射,通过PCA降维将特征通道降至64个,该方法是使用第一帧图像块来学习的。使用峰值为1.0的二维高斯函数生成回归目标图。规模估算的重量因子β是设置为0.6。我们的实验是在一台拥有i7 3.4GHz CPU和GeForce GTX的黑色GPU和MatConvNet工具箱[41]的PC上进行的。在训练阶段,我们迭代地应用学习率为5e-8的adam优化器[23]来更新系数,直到Eq. 3中的损失低于给定的阈值0.02。我们观察到,在实践中,我们的网络收敛于几百次迭代中的随机初始化。我们每2帧更新一次模型,只进行2次迭代,学习速率为2e-9。
 基准数据集。实验分别在OTB-2013[45]、OTB-2015[46]和VOT-2016[24]三个标准基准上进行。前两个数据集分别包含50和100个se quences。它们用地面真实边界框和各种属性进行了注释。在2016年选举数据集中,有60个具有挑战性的视频,来自300多个视频的集合。
基准数据集。实验分别在OTB-2013[45]、OTB-2015[46]和VOT-2016[24]三个标准基准上进行。前两个数据集分别包含50和100个se quences。它们用地面真实边界框和各种属性进行了注释。在2016年选举数据集中,有60个具有挑战性的视频,来自300多个视频的集合。
评价指标。我们遵循来自基准的标准评估指标。对于OTB-2013和OTB- 2015,我们使用带有精度和成功图指标的一次性评估(OPE)。精度度量的是帧位置与地面真值之间一定阈值距离内的比率。所有跟踪器的阈值距离设置为20。成功图度量度量了预测值与地面真实边界框之间的重叠率。对于VOT-2016数据集,性能是根据预期平均重叠(EAO)、平均重叠(AO)、精度值(Av)、精度等级(Ar)、鲁棒性值(Rv)和鲁棒性等级(Rr)来衡量的。平均重叠与OTB基准中的AUC指标相似。