聚类算法之层次聚类与密度聚类
一、层次聚类
层次聚类方法对给定的数据集进行层次的分解,知道某种条件满足为止。层次聚类又可分为:
凝聚的层次聚类:AGNES算法
一种自底向上的策略,首先将每个对象做为一个簇,然后合并这些原子簇为越来愈大的簇,直到达到某个终结条件。
AGNES算法最初将每个对象做为一个簇,然后这些簇根据某些准则被一步步地合并。两个簇间的距离由这两个不同簇中距离最近的数据点对的相似度来确定;聚类的合并过程反复进行直到所有的对象最终满足簇数目。
分裂的层次聚类:DIANA算法
采用自顶向下的策略,它首先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇,直到达到了某个终结条件。
DIANA算法是AGNES算法的反过程,属于分裂的层次聚类,首先将所有的对象初始化到一个簇中,然后根据一些原则(比如最大的欧式距离)将该簇分类。直到达到用户指定的簇数目或者两个簇之间的距离超过了某个阈值。
聚类过程如下图:
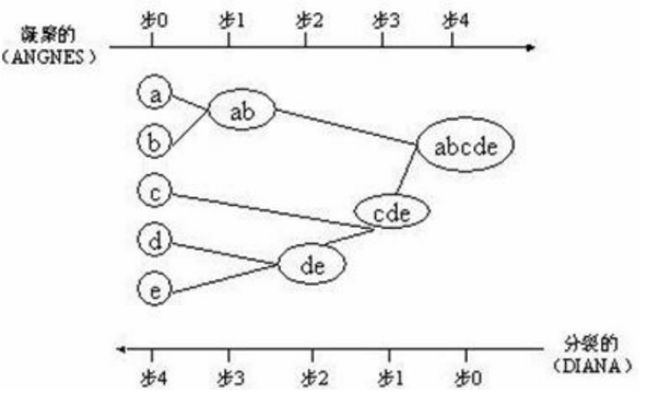
从左向右的过程为AGNES,从右向左的过程为DIANA。
AGNES具体算法如下:


二、密度聚类
密度聚类算法的指导思想是,当样本点的密度大于某阈值时,则将样本点添加到最近的簇中。使用密度聚类能够克服基于距离的算法只能发现“类圆形”聚类的缺点,可发现任意形状的聚类,且对噪声数据不敏感。但是缺点是计算密度单元的复杂度大,需要建立控件索引来降低计算量。
DBSCAN算法
首先来看DBSCAN算法中的一些概念:
对象的![]() 邻域:给定对象在半径
邻域:给定对象在半径![]() 内的区域
内的区域
核心对象:对于给定的数目m,如果一个对象的![]() 邻域至少包含m个对象,则称该对象为核心对象
邻域至少包含m个对象,则称该对象为核心对象
直接密度可达:给定一个对象集合D,如果p是在q的![]() 邻域内,而q是一个核心对象,则对象p从对象q出发是密度可达的。
邻域内,而q是一个核心对象,则对象p从对象q出发是密度可达的。
密度可达:如果存在一个对象链p1p2p3……pn,p1=q,pn=p,对![]() ,
,![]() 是从pi关于
是从pi关于![]() 和m直接密度可达的,则对象p是从对象q关于
和m直接密度可达的,则对象p是从对象q关于![]() 和m密度可达的。简单说就是p直接密度可达p1,p1直接密度可达q,则p和q密度可达。
和m密度可达的。简单说就是p直接密度可达p1,p1直接密度可达q,则p和q密度可达。
密度相连:如果p和q分别关于o密度可达,则p和q是密度相连的。
簇:一个基于密度的簇是最大的密度相连对象的集合
噪声:不包含在任何簇中的对象成为噪声

从左到右依次是密度可达、密度相连、核心对象和噪声的示意图。
DBSCAN算法流程:
1.如果一个点p的![]() 邻域内包含多余m个对象,则创建一个以p做为核心对象的新簇。
邻域内包含多余m个对象,则创建一个以p做为核心对象的新簇。
2.寻找并合并核心对象直接密度可达的对象
3.没有新点可以更新簇时,算法结束

密度最大值聚类
定义局部密度pi:
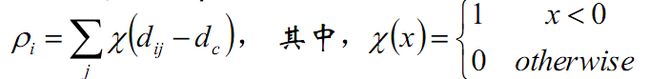
dc是一个截断距离, ρi 即到对象i的距离小于dc 的对象的个数,即:ρi = 任何一个点以dc为半径的圆内的样本点的数量
由于该算法只对ρi 的相对值敏感, 所以对dc的选择是稳健的,一种推荐做法是选择dc ,使得平均每个点的邻居数为所有点的1%-2%
定义:高局部密度点距离δ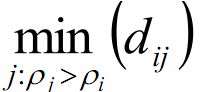
在密度高于对象i的所有对象中,到对象i最近的距离,即高局部密度点距离。
对于密度最大的对象,设置δi=max(dij )(即:该问题中的无穷大)
簇中心的识别
簇中心: 那些有着比较大的局部密度ρi和很大的高密距离δi 的点被认为是簇的中心。
异常点: 高密距离δi较大但局部密度ρi较小的点是异常点。即该样本点周围样本点少且比它密度大的样本点离它较远。
密度最大值聚类过程:

上图中左图是样本点在二维空间中的分布,右图是δ为纵坐标,ρ为横坐标绘制的决策图。
1号样本和10号样本的ρi和δi都比较大,所以可以做为簇中心。
样本28、26、27的ρi很小δi却很大,所以可以认为是异常点。
参考:
邹博 机器学习
http://blog.csdn.net/xueyingxue001/article/details/51966945