.Net中的AOP系列之《方法执行前后——边界切面》
本篇目录
- 边界切面
- PostSharp方法边界
- 方法边界 VS 方法拦截
- ASP.NET HttpModule边界
- 真实案例——检查是否为移动端用户
- 真实案例——缓存
- 小结
本系列的源码本人已托管于Coding上:点击查看。
本系列的实验环境:VS 2013 Update 5(建议最好使用集成了Nuget的VS版本,VS Express版也够用),安装PostSharp。
这篇博客覆盖的内容包括:
- 什么是方法边界
- 使用PostSharp的边界方法
- 编写ASP.NET HttpModule来检测用户是否是移动端用户
- 方法拦截和方法边界的不同之处
- 使用PostSharp编写缓存切面
上一篇我们讲了方法切面中最通用的类型《方法拦截》,这篇我们讲一下可能用到的另外一种切面:边界切面,它里面的代码会在方法的边界运行。首先会使用PostSharp在方法层面上演示一个边界切面,然后也会使用ASP.NET HttpModule演示一个页面层面的边界切面。
这篇博客的目的是通过多个例子演示来说明什么事边界切面以及边界切面一般是如何工作的,而不是带领大家详细地编写这些例子。
边界切面
通常意义上的边界指的是两个实体间的任意分割线,比如两个国家之间的地理上的分界线,我国各个省份之间的分界线,当你去临省旅游时,你必须首先穿过你所在省和邻省的分界线,旅行结束返回时,必须再次穿过省份分界线。
和现实生活一样,编码时也会有很多分界线。就拿最简单的控制台程序来说,当启动一个Main方法时,然后Main方法又调用了另一个方法,当程序进入被调用方法体时也要穿过一个分界线,当被调方法执行完成之后,程序流就会返回到Main方法,这就是我们平时没怎么意识到的边界。
使用了AOP,我们就可以把代码放到那些边界上,这些边界代表了一个地方或一个条件,对于放置一些可复用的代码很有用。
PostSharp方法边界
创建一个控制台项目,名为“BasketballStatsPostSharp”,解决方案名称为"BoundaryAspectsPractices",通过Nuget安装PostSharp。这个项目的需求很简单,创建一个服务类,然后根据球员的名字获得该球员的球衣号码,这里为了演示,直接将结果打印到控制台。
public class BasketballStatsService
{
/// 这只是个普通的程序,没什么可言之处,大家很容易看出运行结果,这里就不演示了。
下面我们创建一个边界切面MyBoundaryAspect,它继承自PostSharp中的OnMethodBoundaryAspect,注意使用PostSharp时记得使用Serializable特性。
[Serializable]
public class MyBoundaryAspect:OnMethodBoundaryAspect
{
public override void OnEntry(MethodExecutionArgs args)
{
Console.WriteLine("方法{0}执行前",args.Method.Name);
}
public override void OnSuccess(MethodExecutionArgs args)
{
Console.WriteLine("方法{0}执行后", args.Method.Name);
}
}
使用的话,很简单,只需要在服务类的方法上加上特性即可,然后运行如下:
这个例子和第一篇介绍中的"Hello World"例子差不多,没什么好玩的,别着急,在本文后面会有一个使用边界方法处理缓存的例子。
方法边界 VS 方法拦截
目前,方法边界切面和方法拦截切面我们都看过了,那么接下来对比一下这两者有什么区别。区别肯定是存在的,但这些区别是很微妙的,专一的开发者可能只使用其中一种切面。这节从下面两个方面讨论一下这些区别:
- 切面方法间的共享状态
- 代码清晰度/意图
下图是PostSharp中MethodInterceptionAspect和OnMethodBoundary切面的基本结构对比:
概念上讲,可以将一个边界切面转成拦截切面,反之亦然,只需要将左边的代码改为右边格式的代码就好了,但是,如果真那么简单,那么这两者之间的区别是什么呢?很明显,答案肯定不是想象的那么简单。
切面方法间的共享状态
首先看一下共享状态。拦截切面只有一个方法OnInvoke,因此共享状态不是关心的问题——在方法开始时可以使用的任何变量可以继续在方法的其他地方使用。但是对于边界方法来说就不那么简单了,在OnEntry方法中声明的变量在OnSuccess方法中是不可用的,因为它们是分离的方法。
但使用PostSharp,对于边界方法的共享状态可以变通一下。首先,可以使用类本身的字段:
[Serializable]
public class MyBoundaryAspect:OnMethodBoundaryAspect
{
private string _sharedState;//使用一个全局变量共享方法之间的信息
public override void OnEntry(MethodExecutionArgs args)
{
_sharedState = "123";//边界方法运行之前,设置一个值
Console.WriteLine("方法{0}执行前",args.Method.Name);
}
public override void OnSuccess(MethodExecutionArgs args)
{
Console.WriteLine("方法{0}执行后,_sharedState={1}", args.Method.Name,_sharedState);//边界方法运行之后该值不变
}
}
然而,这种方法有个缺点。在PostSharp中,切面类中的每个边界方法都使用切面类的相同实例。这种切面叫做静态范围切面,这意味着,即使你创建了多个类的实例,PostSharp的切面标记的方法只会创建一个切面实例与那个类对应。如果切面实现了IInstanceScopedAspect接口,那么这个切面就是一个实例范围切面。默认行为会在编织之后,在代码中添加少量负担,但是引入的那点复杂度可能不是很明显。
要演示这个问题,修改一下切面类和Main方法,服务类方法不变,代码修改如下:
[Serializable]
public class MyBoundaryAspect:OnMethodBoundaryAspect
{
private readonly Guid _sharedState;//使用一个全局变量共享方法之间的信息
public MyBoundaryAspect()
{
_sharedState = Guid.NewGuid();
}
public override void OnEntry(MethodExecutionArgs args)
{
//_sharedState = "123";//边界方法运行之前,设置一个值
Console.WriteLine("方法{0}执行前",args.Method.Name);
}
public override void OnSuccess(MethodExecutionArgs args)
{
Console.WriteLine("方法{0}执行后,_sharedState={1}", args.Method.Name,_sharedState);//边界方法运行之后该值不变
}
}
#region 拦截切面VS边界切面
var s1=new BasketballStatsService();
var s2=new BasketballStatsService();
s1.GetPlayerNumber("Kobe Bryant");
s2.GetPlayerNumber("Kobe Bryant");
#endregion
Console.Read();
运行效果如下:
从结果可以看到,产生的GUID的值是一样的,也就是说,切面实例(每次实例化时都会产生)只产生了一个,也就是说多个服务类的方法共享了相同的MyBoundaryAspect切面对象。如果又调用了服务类的另外一个方法,那么生成的GUID的值就不同了。
GUID
GUID是Globally Unique Identifier(全局唯一标识符)的简写。GUID是用于唯一标识的128bit的值,通常表现为16进制的8-4-4-4-12形式。Guid.NewGuid()会生产一个唯一的Guid(不是从数学角度,而是从实际和统计角度),因此很适合演示产生的实例是不是同一个实例。
总之,切面的全局字段不是切面方法间沟通的安全方式,因为它不是线程安全的。其他方法可以对这些全局字段更改,因此,PostSharp提供了一个叫做args.MethodExecutionTag的API来协助共享状态。它是会传入每个边界方法的args对象的属性,该对象对于方法调用时的每次特定时间都是唯一的。
现在,将Guid.NewGuid()移到构造函数的外面的OnEntry方法中,然后在OnSuccess方法中使用args.MethodExecutionTag方式输出。代码如下:
[Serializable]
public class MyBoundaryAspect:OnMethodBoundaryAspect
{
private readonly Guid _sharedState;//使用一个全局变量共享方法之间的信息
public MyBoundaryAspect()
{
// _sharedState = Guid.NewGuid();
}
public override void OnEntry(MethodExecutionArgs args)
{
//_sharedState = "123";//边界方法运行之前,设置一个值
args.MethodExecutionTag = Guid.NewGuid();
Console.WriteLine("方法{0}执行前,该方法生成的Guid={1}",args.Method.Name,args.MethodExecutionTag);
}
public override void OnSuccess(MethodExecutionArgs args)
{
//Console.WriteLine("方法{0}执行后,_sharedState={1}", args.Method.Name,_sharedState);//边界方法运行之后该值不变
Console.WriteLine("方法{0}执行后,该方法生成的Guid={1}", args.Method.Name, args.MethodExecutionTag);
}
}
运行结果如下:
从上面的运行结果看以看出,同一个边界切面中的不同边界方法共享了相同的数据GUID,但是不同的服务类实例调用使用了同一个切面的方法,GUID是不同的。
MethodExecutionTag是一个对象类型,适合存储一些像GUID等简单的类型,如果需要存储更复杂的共享数据,必须在使用时强制转换MethodExecutionTag的类型。如果要存储一个包含了多个对象的共享数据,必须创建一个自定义类存储到MethodExecutionTag属性中。
记住,方法拦截切面中不存在这些问题,因为OnInvoke方法是方法拦截切面中唯一的方法,可以在该方法中使用所有的共享数据。上一篇例子中的数据事务就是一个使用了很多共享数据的例子,比如重试次数的数量,事务是否成功执行的标识succeeded都是共享数据。
那么如何选择何时使用拦截切面还是边界切面呢?方法是:如果你要编写的切面使用了复杂的共享数据,或者使用了很多共享数据,那么最好使用方法拦截切面。
代码清晰度/意图
方法拦截切面在数据共享方法有明显的优势,但没有共享数据或者共享数据很少呢?或者需要在某个单独的边界执行一些代码呢?这些场合,方法边界切面更胜一筹。
下面写一个切面,该切面运行在方法完成时的边界(无论方法是否成功)。在PostSharp中需要编写这个边界切面,
需要重写OnExit方法,它不同于OnSuccess方法,后者只有当方法没有抛出异常执行完毕时才会执行,而前者当方法执行完成时都会运行,不管有没有抛异常都会执行。
//边界切面的写法
public override void OnExit(MethodExecutionArgs args)
{
Console.WriteLine("方法{0}执行完成!",args.Method.Name);
}
如果要在拦截切面中写的话,就需要这么写:
public class MyIntercepor : MethodInterceptionAspect
{
public override void OnInvoke(MethodInterceptionArgs args)
{
try
{
args.Proceed();//在边界切面中,这行代码是隐式执行的
}
finally //C#中的finally指的是,无论try中发生了什么,代码块都会执行
{
Console.WriteLine("方法{0}执行完成!", args.Method.Name);
}
}
}
上面这个例子很简单,但是现实中的项目不可能这么简单,可能try和finally代码块中的代码都很多,那么此时使用拦截切面维护就显得更加费力,因为第一眼看得代码更多,而且代码一多,可能发生的问题更多。而边界切面隐藏了try/catch/finally和Proceed()的细节,我们不需要读写那些代码。
最后要说的是,虽然你可能偏爱方法拦截,但不要忽略了边界切面,因为它可以改善代码的清晰度和简洁度。
性能和内存考虑
方法边界切面和方法拦截切面其他的重要区别是性能和内存方面,这些方法的考虑取决于使用的工具的不同而不同。
在PostSharp中,当使用MethodInterceptionAspect时,所有的参数每次都会从栈中复制到堆中(通过装箱boxing),当使用OnMethodBoundaryAspect时,PostSharp会检测没有使用的参数,不会把这些参数装箱,从而优化了代码。因此,如果编写的切面没有使用方法参数,那么使用OnMethodBoundaryAspect会使用更少的内存,如果在多个地方都使用这个切面,那么这样的做法可能是重要的(注意:该优化功能没有包含在PostSharp的免费版中)。
方法边界不是使用AOP时唯一有用的边界类型,下面我们会看一个ASP.NET HttpModule的例子,这个例子对于把边界放到web页面上非常有用。
ASP.NET HttpModule边界
这里为了方便演示,创建一个Asp.Net Web Form项目WebFormHttpModule,新建一个页面Demo.aspx,代码如下:
<%@ Page Language="C#" AutoEventWireup="true" CodeBehind="Demo.aspx.cs" Inherits="WebFormHttpModule.Demo" %>
<html xmlns="http://www.w3.org/1999/xhtml">
<head runat="server">
<title>title>
head>
<body>
<form id="form1" runat="server">
<div><h1>这是一个Demo页面!h1>div>
form>
body>
html>
在浏览器中浏览该文件时,页面上会显示这是一个Demo页面!这句话。对每个ASP.NET 页面的请求都会有一个很复杂的生命周期,但值得注意的是该生命周期中的一部分使用了HttpModule,它允许我们将代码放到ASP.NET页面的边界。要创建一个HttpModule,需要创建一个实现了IHttpModule接口的类:
public class MyHttpModule:IHttpModule
{
/// 每个模块都必须在ASP.NET的Web.config文件中配置后才可以运行。Web.config的配置可能会根据你使用的web服务器( IIS6 , IIS7 +, Cassini, IIS Express等等)不同而不同。要想覆盖以上服务器的所有配置,可以像下面那样配置:
<system.web>
<compilation debug="true" targetFramework="4.5" />
<httpModules>
<add name="MyHttpModule" type="WebFormHttpModule.MyHttpModule"/>
httpModules>
system.web>
<system.webServer>
<validation validateIntegratedModeConfiguration="false"/>
<modules>
<add name="MyHttpModule" type="WebFormHttpModule.MyHttpModule"/>
modules>
system.webServer>
ASP.NET使用了多个工作进程处理即将到来的请求,每个工作进程都会创建一个HttpApplication的实例,每个HttpApplication实例都会创建一个HttpModule,然后运行Init方法,现在自定义的Init方法什么都还没写,下面会使用事件句柄设置一些边界:
public class MyHttpModule:IHttpModule
{
/// 虽然语法很不同,但是这种感觉很像之前的方法边界切面。浏览一下页面,效果如下:
因为在这些边界方法中有一个HttpApplication对象,因此可以有很大的灵活性和潜能完成很多事情。当检查HttpApplication的属性和事件时,可以看到做许多事情而不仅是输出文本。下一节我们会使用HttpModule演示一个真实的案例:检测用户是否是移动端用户。
真实案例——检查是否为移动端用户
下面再创建一个ASP.NET WebForm 项目演示一个检测用户端是否是移动端的例子。比如,你通过搜索引擎搜索到一个网页,然后打开网页,当然,进入的可能不是首页,也可能是首页。如果当用户进入时,该网站能根据用户的客户端类型,为用户提供更好的服务,那么该用户可能就会发展成为该产品的最终用户。那么问题来了,怎么根据用户的客户端类型为他提供更好的服务呢?请看以下流程图:
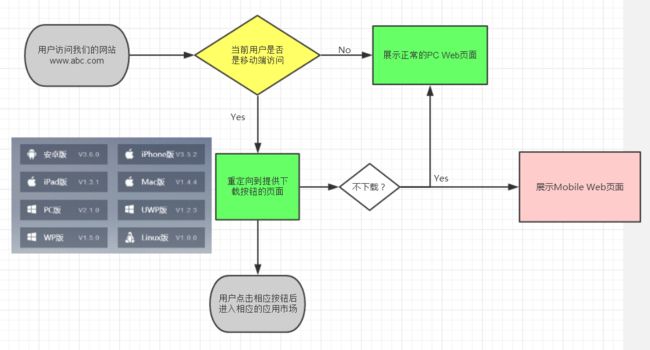
项目目录见下图(源码大家可以通过上面的链接拿到):
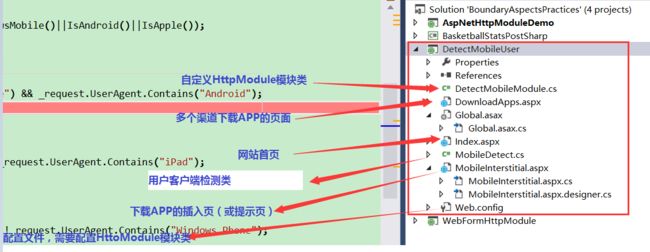
详细代码就不在这里浪费地方贴出来了,感兴趣的可以去下载源码学习,这里只贴一部分比较核心的代码。
创建HttpModule
首先要创建自己的HttpModule,然后实现IHttpModule接口,默认要实现Init和Dispose方法:
public class DetectMobileModule:IHttpModule
{
public void Dispose()
{
throw new NotImplementedException();
}
public void Init(HttpApplication context)
{
context.BeginRequest += context_BeginRequest;
}
}
在这个例子中,我们不需要在Dispose方法中写任何代码,因为我们这个例子没有使用任何要求释放的资源(如FileStream或者SqlConnection等GC没有处理的资源)。ASP.NET HttpModule在每个Http请求都会运行,传入到Init方法的HttpApplication上下文参数给具体的边界调用提供了一些事件。这个例子中,我们只对BeginRequest边界事件感兴趣,它的代码如下:
void context_BeginRequest(object sender, EventArgs e)
{
}
context_BeginRequest中的代码会在页面执行之前运行,因此,这也就是我们可以检测用户是否是移动端的地方。
检测移动端用户
创建一个MobileDetect类,假设APP可用的有3大平台:Android,IOS和Windows 10 Mobile。这里检测用户客户端类型的方式很简单,看UserAgent是否包含确定的关键字即可。代码如下:
public class MobileDetect
{
readonly HttpRequest _request;
public MobileDetect(HttpContext context)
{
_request = context.Request;
}
public bool IsMobile()
{
return _request.Browser.IsMobileDevice&&(IsWindowsMobile()||IsAndroid()||IsApple());
}
/// 重定向到插入页
接下来,我们要在context_BeginRequest事件句柄中使用上面定义的MobileDetect类了。如果MobileDetect类检测到用户的请求来自智能手机,那么他会被重定向到一个插入页MobileInterstitial.aspx:
void context_BeginRequest(object sender, EventArgs e)
{
var context = HttpContext.Current;
//使用当前上下文对象创建一个MobileDetect对象
var mobileDetect=new MobileDetect(context);
if (mobileDetect.IsMobile())
{
//如果用户拒绝下载APP,那么我们需要将他跳转回之前访问的页面
var url = context.Request.RawUrl;
var encodeUrl = HttpUtility.UrlEncode(url);
//重定向到下载插入页,并带上returnUrl,以防用户需要返回到之前的页面
context.Response.Redirect("MobileInterstitial.aspx?returnUrl=" + encodeUrl);
}
}
插入页效果很简单,如下所示:
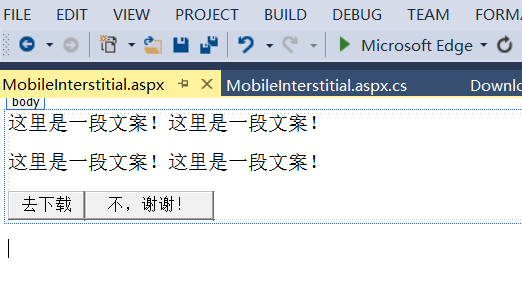
两个按钮的点击事件如下:
/// 添加检查
细心的园友可能会发现一个问题,如果按照上面的代码就这样完了,那是会出问题的。用户的每次请求都会经过HttpModule,这么一来,每次请求都会检测用户的客户端类型,然后再次跳转到插入下载页。即使用户点击了“不,谢谢!”按钮,还是会每次都跳转到下载插入页。这会让用户感到很烦人,可能会立即关闭这个网页,因而我们也就失去了一个潜在用户。因此,我们需要在context_BeginRequest中添加条件判断:
void context_BeginRequest(object sender, EventArgs e)
{
//如果上一次请求来自下载插入页或者当前请求就是下载插入页,那么直接返回
if (ComingFromMobileInterstitial()||OnMobileInterstitial())
{
return;
}
var context = HttpContext.Current;
//使用当前上下文对象创建一个MobileDetect对象
var mobileDetect=new MobileDetect(context);
if (mobileDetect.IsMobile())
{
//如果用户拒绝下载APP,那么我们需要将他跳转回之前访问的页面
var url = context.Request.RawUrl;
var encodeUrl = HttpUtility.UrlEncode(url);
//重定向到下载插入页,并带上returnUrl,以防用户需要返回到之前的页面
context.Response.Redirect("MobileInterstitial.aspx?returnUrl=" + encodeUrl);
}
}
/// 上面只是解决了当用户点击拒绝下载之后用户不会再次直接跳转到下载插入页的问题,用户就不会卡在这个死循环了。但是我们还可以做得更好,假设用户不想安装APP,并希望在一个正常的移动端浏览器中查看页面,而且,用户点击了拒绝下载按钮之后,也不要每次请求都要重定向到下载插入页。
进一步完善
当用户点击了“不,谢谢!”按钮之后,我们就不要在每次页面请求时都跳转到下载插入页,不要再打扰他们了。一种方式就是当用户点击了该按钮之后,设置一个cookie:
protected void btnThanks_Click(object sender, EventArgs e)
{
//用户点击拒绝下载按钮之后,设置一个cookie,并根据自己的情况设置一个有效期,这里为了演示,设置为2分钟
var cookie=new HttpCookie("NoThanks","yes");
cookie.Expires = DateTime.Now.AddMinutes(2);
Response.Cookies.Add(cookie);
//取到上一次请求的url
var url = Request.QueryString.Get("returnUrl");
Response.Redirect(HttpUtility.UrlDecode(url));
}
接下来,我们需要在context_BeginRequest方法中检查是否具有特定值的Cookie,从而是否将用户重定向到下载插入页:
void context_BeginRequest(object sender, EventArgs e)
{
//如果请求中的Cookie包含NoThanks键或者上一次请求来自下载插入页或者当前请求就是下载插入页,那么直接返回
if (ExistNoThanksCookie()||ComingFromMobileInterstitial()||OnMobileInterstitial())
{
return;
}
var context = HttpContext.Current;
//使用当前上下文对象创建一个MobileDetect对象
var mobileDetect=new MobileDetect(context);
if (mobileDetect.IsMobile())
{
//如果用户拒绝下载APP,那么我们需要将他跳转回之前访问的页面
var url = context.Request.RawUrl;
var encodeUrl = HttpUtility.UrlEncode(url);
//重定向到下载插入页,并带上returnUrl,以防用户需要返回到之前的页面
context.Response.Redirect("MobileInterstitial.aspx?returnUrl=" + encodeUrl);
}
}
bool ExistNoThanksCookie()
{
return HttpContext.Current.Request.Cookies.Get("NoThanks") != null;
}
下面楼主将网站发布到IIS,使用Windows 10 Mobile,借助Windows 10 PC RS1版的连接功能,给大家截取动态图演示一下效果,其他类型的手机也可以访问网站并跳转到对应的应用商店,但是楼主这里主要可以借助win10 PC和手机进行投影给大家演示效果。动态图很大的,近1000帧剪辑得还剩100多帧。
Web应用中的HttpModule使用AOP很好地解决了横切关注点的问题,别忘了我们这个系列的目的,是学习AOP的,而不是Web开发中的一些细节知识点,这个例子是页面边界切面的例子,下面我们看一个PostSharp方法边界处理缓存的例子。
真实案例——缓存
在web开发中有一种数据库优化的方法,比如,一个页面可能调用了很多次数据库,那么这些调用可以通过优化代码和减少数据库调用来改善性能。但是有时处理的速度不是我们能控制的,比如某些处理过程真的很复杂,需要花费很多时间来处理;有时我们需要依赖外部的处理(数据库,web服务等等),这些我们几乎没有控制权。
重点来了,如果需要的数据处理的很慢,并且这些数据不经常变化,那么我们可以使用缓存来减少等待时间。Caching通常对于多用户的系统是非常有利的,第一次的请求还是很慢的,然后缓存将第一次请求的结果存储到可以迅速读取数据的本地,之后其他的请求就会先去缓存检测是否有需要的数据,如果有的话,就会直接从缓存中取出数据,从而跳过缓慢的处理过程。
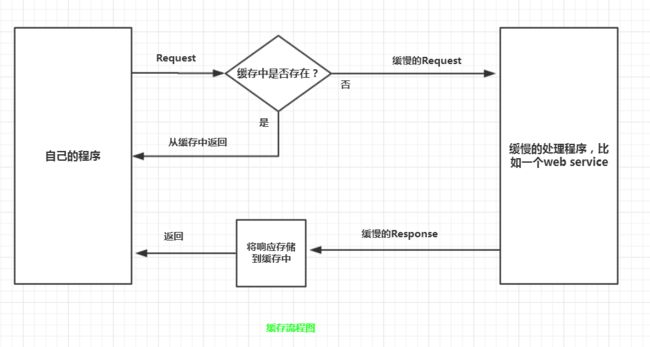
缓存也可以看作是一个横切关注点,对于想要使用缓存的每个方法,可以按照以下步骤来:
- 检测缓存中是否含有值;
- 如果有,直接返回;
- 如果没有,像以往那样处理;
- 将处理的结果放到缓存中,以便下次使用。
用流程图画一下:
上面的流程在代码中都实现出来的话,可能会导致大量的样板代码,这就暗示我们使用AOP是个不错的主意。下面我们看一个ASP.NET中关于Cache对象的例子,并编写一个切面来更有效的工作。
ASP.NET Cache
不同类型的应用可以使用不同的缓存工具,比如NCache,Memcached等。但这里我们关注的是如何使用AOP处理缓存而不是各种缓存工具的使用,下面的例子会使用.Net开发者的老朋友 ASP.NET Cache。
ASP.NET代码中的缓存就像一个可以使用的字典对象,在ASP.NET WEB Froms中,Cache继承自Page基类,而在ASP.NET MVC中,通过继承自Controller基类的HttpContext就可以使用缓存了。如果上面的都无法读取缓存,可以通过HttpContext.Current.Cache获取。
Cache对象的API很简单,可以把它当作字典来使用,可以从Cache中获取值,也可以往Cache中添加值。如果要获取的值没有存在于缓存中,就会返回null。
Cache["MyCacheKey"] = "some value";//使用MyCacheKey作为键存储some value
var myValue = Cache["MyCacheKey"];//使用键获取缓存
var myValue = Cache["SomeOtherKey"];//如果缓存不存在就会返回null
Cache还有很多有用的其他方法,比如Add 和 Insert方法,这可以让我们指定缓存的过期时间。此外,也可以使用Remove方法立即从缓存中移除一个值。
Cache 有效期
缓存值通常都会设置一个过期时间。比如,如果使用"CacheKey"存储了一个值,并设置过期时间是2小时之后,那么2小时之后,使用"CacheKey"检索那个值时就会返回null。
ASP.NET Cache有几个可以使用的过期时间设置:
- 绝对过期时间:该值会在给定的时间过期。
- 滑动过期时间:该值会在上次使用之后开始计算时间,如果超过了给定的时间就会过期。
- 永不过期:该值会一直存在,除非应用结束掉,或者该缓存存储了其他的东西。
关于缓存的一个案例
这次我们创建一个ASP.NET MVC项目,项目的目录结构如下:

上面的其他文件夹Content,Scripts,Controller,Models等等就不用多说了,不懂的话,请去学习ASP.NET MVC。下面在用一张动态图看一下整个网站的效果:
这个项目是楼主从头搭建起来的,整体布局使用的是法拉利红作为主题色,虽然给自己的定位是全栈,但是整个页面的布局还是花了不少时间的,看来自己还得在css和html方面深入学习一下啊。放了三个导航链接,Home页随便找了一辆自己看着还不错的法拉利图片,About放了两张打赏的图片,其实要讲的东西在最后一个Value页面。
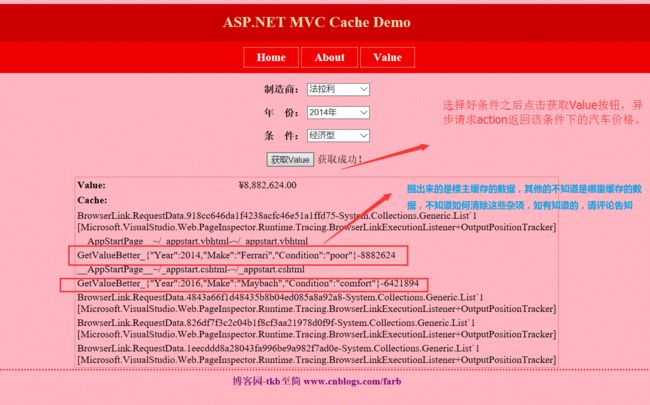
和之前一样,css,html,js代码这里就不贴出来了,感兴趣的可以去看源码,这里只放一些关于AOP的核心代码。
Value显示页面
下面是点击Value按钮时的Action代码,主要是放了些select中的数据和读取缓存内容:
[HttpGet]
public ActionResult Value()
{
ViewData["Cache"]= DisplayCache();//显示缓存内容
//制造商数据
var makes = new SelectList(new List
{
new SelectListItem{Text = "法拉利",Value = "Ferrari",Selected = true},
new SelectListItem{Text = "劳斯莱斯",Value = "Rolls-Royce"},
new SelectListItem{Text = "迈巴赫",Value = "Maybach"}
},"Value","Text");
//年份数据
var years=new SelectList(new List
{
new SelectListItem{Text = "2014年",Value = "2014"},
new SelectListItem{Text = "2015年",Value = "2015"},
new SelectListItem{Text = "2016年",Value = "2016",Selected = true}
},"Value","Text");
//条件数据
var conditions=new SelectList(new List
{
new SelectListItem{Text = "经济型",Value = "poor",Selected = true},
new SelectListItem{Text = "舒适型",Value = "comfort"},
new SelectListItem{Text = "豪华型",Value = "best"}
},"Value","Text");
ViewData["makes"] = makes;
ViewData["years"] = years;
ViewData["conditions"] = conditions;
return View();
}
/// 看到缓存里面有很多不知哪里生成的东西,就写了个ClearAllCache()方法清除所有的缓存,但是这样就没办法把自己的缓存也清除了,所以这里注释了。这里也不贴实现了,感兴趣的话请看源码。
获取Value的Action
选择好各个条件之后,点击获取Value 按钮就会通过ajax异步将选择的条件提交到下面这个action:
[HttpPost]
public ActionResult ValuePost(FormCollection collection)
{
var years = Convert.ToInt32(Request.Form.Get("years"));
var makes = Request.Form.Get("makes");
var conditions = Request.Form.Get("conditions");
//第二种方式获取form表单的值
//var years2 = Convert.ToInt32(collection.Get("years"));
//var makes2 = collection.Get("makes");
//var conditions2 = collection.Get("conditions");
var carValueService=new CarValueService();
//第一种方式获取汽车价格,不具有健壮性,故不采用
//var value = carValueService.GetValue(years, makes, conditions);
var value = carValueService.GetValueBetter(new CarValueArgs
{
Condition = conditions,Make = makes,Year = years
});
return Content(value.ToString("c"));
}
这个action就取到前端传过来的条件参数,然后使用这些参数借助CarValueService服务类获得车辆的价格。
CarValueService服务类
下面是一个汽车服务类,一般情况下,这些数据是第三方汽车厂商或代理商、分销商等提供的,变化频率不是很高,而且调用一个Web Service可能会很慢,因此,可以用户缓存处理。这里我们使用Thread.Sleep(5000);来模拟一个耗时操作。这里有两个方法,一个是GetValue,一个是GetValueBetter,上面也已经说了,后面的方法健壮性更好,因为只需要更改服务类方法的参数的属性就够了,而不用修改服务类方法的参数的签名。
public class CarValueService
{
readonly Random _ran;
public CarValueService()
{
_ran=new Random();
}
[CacheAspect]
public decimal GetValue(int year,string makeId,string conditionId)
{
Thread.Sleep(5000);
return _ran.Next(1000000, 10000000);
}
[CacheAspect]
public decimal GetValueBetter(CarValueArgs args)
{
Thread.Sleep(5000);
return _ran.Next(1000000, 10000000);
}
}
汽车的价格这里是去获取100w到1000w之间的随机数。方法上面都使用了缓存切面CacheAspect特性。
缓存切面CacheAspect
既然是调用第三方不频繁变化的数据,那么就可以把请求的结果缓存起来。
[Serializable]
public class CacheAspect : OnMethodBoundaryAspect
{
/// 上面的代码已经解释地很清楚了,大家看代码注释就好。
这里为什么将缓存的键加入Json?
易读。当看到屏幕上缓存的内容时,很清楚知道发生了什么,以及缓存了什么。
轻量。无意冒犯xml粉,但这里真不需要额外的XML头和其他命名空间信息等标签。
易生成。使用JsonConvert类或JavaScriptSerializer就可以轻易搞定。
其实这里选哪种方式序列化无所谓,只要能实现给缓存生成一个唯一的键的目的就行。
小结
这篇博文我们看了一下切面常用的类型:边界切面。代码中的边界就像国家之间的分界线一样,它给我们提供了将行为放到代码边界的机会。两个常见的例子就是web页面加载前后和方法调用前后的例子。跟方法拦截切面一样,边界切面提供了封装横切关注点的另一种方式。
PostSharp提供了编写方法拦截切面的能力,ASP.NET通过HttpModule提供了编写Web页面边界的能力,而且他们的API都提供了上下文信息(比如Http请求和方法的信息),以及控制程序流的能力(比如重定向页面或立即从方法返回)。
转载自:http://www.cnblogs.com/farb/p/BoundaryAspects.html#vs