《Python网络爬虫技术》读书笔记1
文章目录
- 使用Selenium爬取动态网页
- 部署Selenium
- 简答使用Selenium
- 页面等待
- 元素选取
- 页面操作
- 填充表单
- 执行JavaScript
- 模拟登陆
- 简单的处理验证码
- 代理
- 使用Requests库配置代理IP
- 用post方式进行登陆
- 使用cookie
- 一个综合的例子
- 终端协议分析
- 分析app抓包
- 设置Fiddler工具
- 设置Android系统的手机
- 打开对应的app
使用Selenium爬取动态网页
部署Selenium
请参考:
python+selenium 安装及部署
简答使用Selenium
打开一个网站后,在新开一个tab打开另外一个网站
#!/usr/bin/env python
# encoding: utf-8
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.ptpress.com.cn/search/books')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to_window(browser.window_handles[1])
browser.get('http://www.tipdm.com')
time.sleep(1)
browser.switch_to_window(browser.window_handles[0])
browser.get('http://www.tipdm.org')
页面等待
Selenium Webdriver提供两种类型的等待——隐式和显式。显式的等待使网络驱动程序在继续执行之前等待某个条件的发生。隐式的等待使WebDriver在尝试定位一个元素时,在一定的时间内轮询DOM
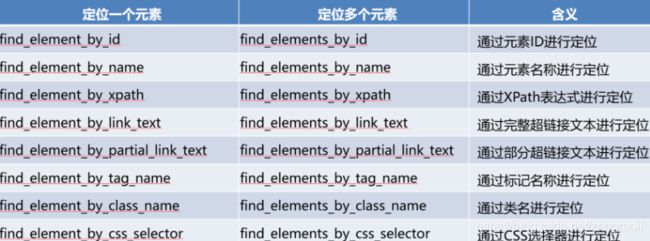
元素选取
在页面中定位元素有多种策略。Selenium库提供了如表所示的方法来定位页面中的元素,使用find_element进行元素选取。在单元素查找中使用到了通过元素ID进行定位、通过XPath表达式进行定位、通过CSS选择器进行定位等操作。在多元素查找中使用到了通过CSS选择器进行定位等操作
页面操作
填充表单
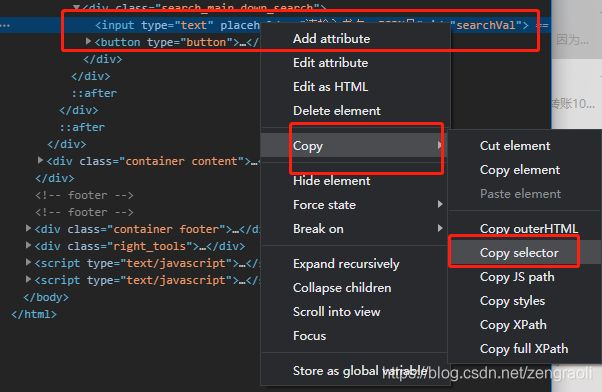
首先打开目标网页http://www.ptpress.com.cn/search/books,在chrome的F12中,按到对应元素的selector,这样才能在Selenium中进行操作
#!/usr/bin/env python
# encoding: utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get('http://www.ptpress.com.cn/search/books')
wait = WebDriverWait(driver, 10)
# 等待确认按钮加载完成
confirm_btn = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#app > div:nth-child(1) > div > div > div > button > i')))
# 填入文本框内容
search_text = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#searchVal')))
# 填入文本框内容
search_text.send_keys("zengraoli")
# 单击搜索
confirm_btn.click()
效果如下

执行JavaScript
Selenium库中的execute_script方法能够直接调用JavaScript方法来实现翻页到底部、弹框等操作。比如在“http://www.ptpress.com.cn/search/books”网页中通过JavaScript翻到页面底部,并弹框提示爬虫
示例代码如下
#!/usr/bin/env python
# encoding: utf-8
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
driver = webdriver.Chrome()
driver.get('http://www.ptpress.com.cn/search/books')
wait = WebDriverWait(driver, 10)
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
driver.execute_script('alert("python爬虫")')

模拟登陆
简单的处理验证码
如果遇到输入验证码的登录,模拟登陆的思路大概为,通过找到验证码的图片,用PIL库显示出来,人工进行输入,再去提交处理
下面的代码实现了,获取验证码的图片然后进行显示
#!/usr/bin/env python
# encoding: utf-8
import requests # 导入Requests库
from PIL import Image # 导入PIL库的Image模块
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) Chrome/65.0.3325.181'}
captcha_url = 'http://www.tipdm.org/captcha.svl'
response = requests.get(captcha_url, headers=headers)
with open('captcha.gif', 'wb') as f:
f.write(response.content)
im = Image.open('captcha.gif') # 创建image对象
im.show() # 显示图片,会在电脑上自动弹出
captcha = input('请输入验证码: ')
print(captcha)
显示的验证码如下

代理
每次输入验证码会比较麻烦,效率低下。而且当网站服务器多次对指定IP弹出验证码后,可能会封禁该IP,导致爬取无法进行。因此,使用代理IP的方法,使用多个IP切换跳过验证码,成为应对反爬虫的主要手段
获取代理IP的三种方式
- VPN:是Virtual Private Network的简称,指专用虚拟网络。国内外很多厂商都提供VPN服务,可自动更换IP,实时性高,速度快,但价格较高,适合商用
- IP代理池:指大量IP地址集。国内外很多厂商将IP做成代理池,提供API接口,允许用户使用程序调用,但价格也较高
- ADSL宽带拨号:是一种宽带上网方式。特点是断开重连会更换IP,爬虫使用这个原理更换IP,但效率低,实时性差
使用Requests库配置代理IP
Requests库为各个发送请求的函数(get、post、put等)配置代理IP的参数是proxies,它接收dict。为保障安全性,一些代理服务器设置了用户名和密码,使用它的IP时需要带上用户名和密码,IP地址的基本格式如下
http://用户名:密码@服务器地址
一个示例
#!/usr/bin/env python
# encoding: utf-8
import requests
proxies = {'http': 'http://zeng:[email protected]:808'}
r = requests.get("http://www.tipdm.org", proxies=proxies)
print(r.status_code)
输入输出200即为访问成功
用post方式进行登陆
这是普通的方法,直接进行提交
#!/usr/bin/env python
# encoding: utf-8
import requests
data = {'username': 'pc2019', 'password': 'pc2019', 'captcha': 'begv'}
r = requests.post('http://www.tipdm.org/login.jspx', data=data)
print(r) # ,虽然200,但是不会有正确数据,因为验证码肯定是不对的
使用cookie
Cookie用于服务器端识别客户端,当发送请求的客户端享有同样的Cookie时,即可认定客户端是同一个。Requests库的会话对象Session能够跨请求地保持某些参数,比如Cookie,它令发送请求的客户端享有相同的Cookie,保证表单数据的匹配
data = {'username': 'pc2019','password':'pc2019','captcha':'begv'}
s = requests.session()
r = s.post('http://www.tipdm.org/login.jspx', data=data)
print(r)
一个综合的例子
结合上面的代码,用post进行登录后拿到cookie保存到文件中,再用这个cookie去访问会员中心,查看是否能正常使用cookie
#!/usr/bin/env python
# encoding: utf-8
import requests
from PIL import Image
# 导入cookiejar模块
from http import cookiejar
s = requests.Session()
# 创建LWPCookieJar对象,若Cookie不存在建立Cookie文件,命名为cookie
s.cookies = cookiejar.LWPCookieJar('cookie')
login_url = 'http://www.tipdm.org/login.jspx'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) Chrome/65.0.3325.181'}
def get_captcha():
captcha_url = 'http://www.tipdm.org/captcha.svl'
response = s.get(captcha_url, headers=headers)
with open('captcha.gif', 'wb') as f:
f.write(response.content)
im = Image.open('captcha.gif')
im.show()
captcha = input('请输入验证码: ')
return captcha
login_data = {'username': 'pc2019', 'password': 'pc2019', 'captcha': get_captcha()}
r = s.post(login_url, data=login_data, headers=headers)
# 测试是否成功登陆
print('发送请求后返回的网址为:', r.url)
# 保存cookie
s.cookies.save(ignore_discard=True, ignore_expires=True)
try:
s.cookies.load(ignore_discard=True) # 加载保存的cookie文件
except:
print('Cookie 未能加载!')
# 携带Cookie提交请求
member_center_url = "http://www.tipdm.org/member/index.jspx"
r = s.get(member_center_url, headers=headers)
# 测试是否成功登陆
print('发送请求后返回的网址为:', r.text) # 是否输出会员信息
终端协议分析
分析app抓包
设置Fiddler工具
打开fiddler的tools,选择options,选中“Decrypt HTTPS traffic”,Fiddler即可截获HTTPS请求,如下图所示
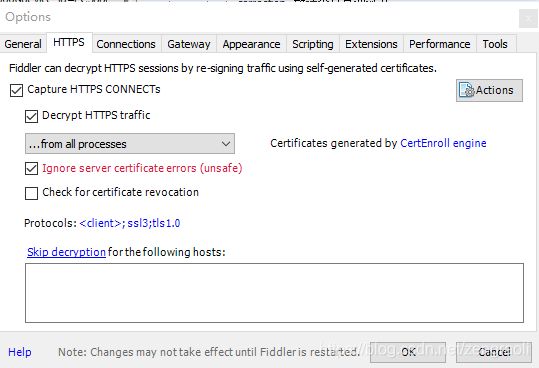
切换至“Connections”选项卡,选中“Allow remote computers to connect”,表示允许远程设备将HTTP/HTTPS请求发送到Fiddler,如下图所示。此处默认的端口号是8888,可以根据需求更改,但是需注意不能与已使用的端口冲突

设置Android系统的手机
访问pc的ip:8888,下载证书,完成后设置wifi的代理为pc的ip,端口为8888

打开对应的app
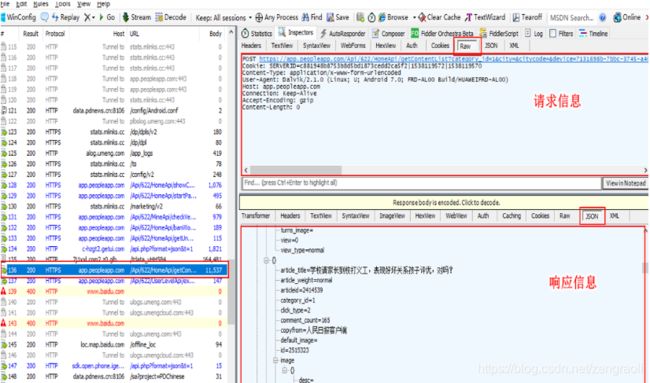
打开人民日报手机APP,在Fiddler工具的左侧栏找到人民日报APP的信息,每个Fiddler工具抓取到的数据包都会在该列表中展示,单击具体的一条数据包后,可以在右侧菜单上单击“Insepector”按钮查看数据包的详细内容。Fiddler工具的右侧栏主要分为请求信息(即客户端发出的数据)和响应信息(服务器返回的数据)两部分。在请求信息上,单击“Raw”按钮(显示Headers和Body数据),在响应信息单击“JSON”(若请求或响应数据是json格式,以json形式显示请求或响应内容),如下图所示
在Fiddler中得到GET请求的URL地址后,Chrome浏览器需要下载JSON-handle插件,才能看到返回的JSON格式的信息