评价指标
1.查准率、查全率(召回率)
- 查准率:反映了被分类器判定的正例中真正的正例样本的比重
查准率(Precision)=精确度=precision=TP/(TP+FP)
- 查全率:反映了被正确判定的正例占总的正例的比重
查全率(recall)=召回率recall=TP/(TP+FN)
- 正确率、准确率:反映了分类器统对整个样本的判定能力——能将正的判定为正,负的判定为负:
Accuracy =正确率=准确率=(TP+TN)/Total examples
- 查全率和查准率是一对矛盾的度量,一般情况(查全率高时,查准率高;反之)。
- 在很多情况下,我们可以根据学习器的预测结果对样例进行排序,排在前面的是学习器认为最可能是正例的样本,排在后面的是学习器认为最不可能是正例的样本,按此顺序逐个把样本作为正例进行预测,则每次可计算当前的查全率和查准率,以查准率为y轴,以查全率为x轴,可以画出下面的P-R曲线(图:查准率P曲线-——查全率(召回率R))。
PR:
如果一个学习器的P-R曲线被另一个学习器的P-R曲线完全包住,则可断言后者的性能优于前者,例如上面的A和B优于学习器C,但是A和B的性能无法直接判断,但我们往往仍希望把学习器A和学习器B进行一个比较,我们可以根据曲线下方的面积大小来进行比较,但更常用的是平衡点或者是F1值。平衡点(BEP)是查准率=查全率时的取值,如果这个值较大,则说明学习器的性能较好。而F1 = 2 * P * R /( P + R ),同样,F1值越大,我们可以认为该学习器的性能较好。

2.分类结果表示:
- 表示分类正确:
True Positive: 本来是正样例,分类成正样例。TP
True Negative:本来是负样例,分类成负样例。TN
- 表示分类错误:
False Positive : 本来是负样例,分类成正样例,通常叫误报。 FP
False Negative:本来是正样例,分类成负样例,通常叫漏报。FN
3.ROC曲线(AUC)
很多学习器是为测试样本产生一个实值或概率预测,然后将这个预测值与一个分类阈值进行比较,若大于阈值分为正类,否则为反类,因此分类过程可以看作选取一个截断点。
不同任务中,可以选择不同截断点,若更注重”查准率”,应选择排序中靠前位置进行截断,反之若注重”查全率”,则选择靠后位置截断。因此排序本身质量的好坏,可以直接导致学习器不同泛化性能好坏,ROC曲线则是从这个角度出发来研究学习器的工具。
曲线的坐标分别为真正例率(TPR)和假正例率(FPR),定义如下:
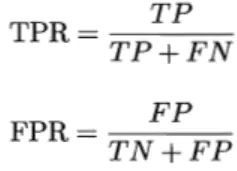
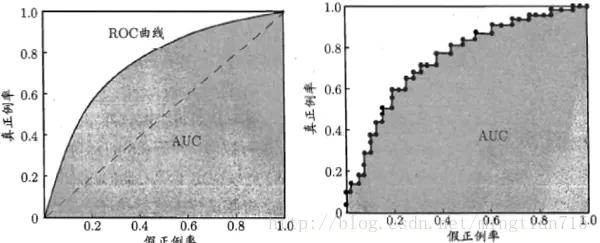
下图为ROC曲线示意图,因现实任务中通常利用有限个测试样例来绘制ROC图,因此应为无法产生光滑曲线,如右图所示。
绘图过程很简单:给定m个正例子,n个反例子,根据学习器预测结果进行排序,先把分类阈值设为最大,使得所有例子均预测为反例,此时TPR和FPR均为0,在(0,0)处标记一个点,再将分类阈值依次设为每个样例的预测值,即依次将每个例子划分为正例。设前一个坐标为(x,y),若当前为真正例,对应标记点为(x,y+1/m),若当前为假正例,则标记点为(x+1/n,y),然后依次连接各点。
下面举个绘图例子: 有10个样例子,5个正例子,5个反例子。有两个学习器A,B,分别对10个例子进行预测,按照预测的值(这里就不具体列了)从高到低排序结果如下:
A:[反正正正反反正正反反](根据样例顺序绘制一些点)
B : [反正反反反正正正正反]
按照绘图过程,可以得到学习器对应的ROC曲线点
A:y:[0,0,0.2,0.4,0.6,0.6,0.6,0.8,1,1,1]
x:[0,0.2,0.2,0.2,0.2,0.4,0.6,0.6,0.6,0.8,1]
B:y:[0,0,0.2,0.2,0.2,0.2,0.4,0.6,0.8,1,1]
x:[0,0.2,0.2,0.4,0.6,0.8,0.8,0.8,0.8,0.8,1]
绘制曲线结果如下:
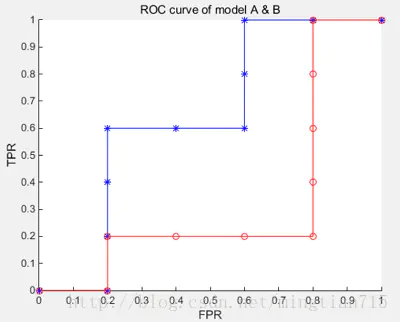
蓝色为学习器A的ROC曲线,其包含了B的曲线,说明它性能更优秀,这点从A,B对10个例子的排序结果显然是能看出来的,A中正例排序高的数目多于B。此外,如果两个曲线有交叉,则需要计算曲线围住的面积(AUC)来评价性能优劣。
4.TOP-1错误率 TOP-5错误率
评价标准采用 top-5 错误率,或者top-1错误率,即对一张图像预测5个类别,只要有一个和人工标注类别相同就算对,否则算错。
Top-1 = (正确标记 与 模型输出的最佳标记不同的样本数)/ 总样本数;
Top-5 = (正确标记 不在 模型输出的前5个最佳标记中的样本数)/ 总样本数;