lua数据结构之TString的内部实现
一、TString结构
1、结构分析
TString是存放字符串的结构体,代码如下:
typedef union TString {
L_Umaxalign dummy; /* ensures maximum alignment for strings */
struct {
CommonHeader;
lu_byte reserved; /* 保留字段 */
unsigned int hash; /* hash值 */
size_t len; /* 字符串长度 */
} tsv;
} TString;结构很简单,主要是CommonHeader,他有两个作用。其一,用于hash值冲突时的链表结构。其二与CGObject形成多态的一个关系。结构如下:
#define CommonHeader GCObject *next; lu_byte tt; lu_byte marked结构也很明了,next指针指向下一个冲突的TString,tt为类型,marked是gc时用到的,暂时不敞开分析。
2、字符串的存放方式
了解完TString的结构以后,或许许多人会有疑问,那字符串数据是存放在哪的?结构中也没有char指针变量呀?的确,字符串不是放在TString这个结构里的,而是往TString后的地址上开辟一段以字符串长度为大小的内存空间,然后把字符串复制到这个空间中。代码如下:
static TString *newlstr (lua_State *L, const char *str, size_t l,
unsigned int h) {
TString *ts;
//创建TString内存空间,大小等于TString大小加上字符串大小。
//可以看出字符串是直接放在TString内存块地址后面的
ts = cast(TString *, luaM_malloc(L, (l+1)*sizeof(char)+sizeof(TString)));
...省略...
memcpy(ts+1, str, l*sizeof(char)); /* 复制字符串到TString内存块地址后面的位置上。*/
((char *)(ts+1))[l] = '\0'; /* ending 0 */
...省略...
}二、全局hash表
对于大量的字符串创建,为了能高效的利用内存空间,lua 有一套设计思想。 所有已创建的TString数据,都会生成一个hash值,并放到hash表里。当创建的字符串是在hash表中已存在的话,则直接返回相同的字符串。
1、stringtable的结构
hash表是放在stringtable中的,结构如下:
typedef struct stringtable {
GCObject **hash; /* hash表,存放 TString指针的数组*/
lu_int32 nuse; /* TString数量 */
int size; /* hash表大小,大小为2^n */
} stringtable;2、存放TString
每次创建完TString *str以后,都会根据其hash值获得在hash表中相对的位置节点,把str放到当前节点。如果有hash值冲突,则把str->next指向冲突节点。存放模型如下图:
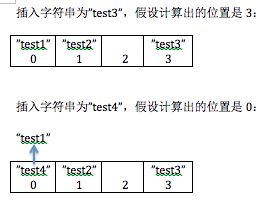
主要代码如下:
static TString *newlstr (lua_State *L, const char *str, size_t l,
unsigned int h) {
TString *ts;
stringtable *tb;
...省略...
h = lmod(h, tb->size); /*通过hash值,转换为具体下标位置*/
ts->tsv.next = tb->hash[h]; /* 新的字符串存到hash表里,并把next指向之前冲突的字符串*/
tb->hash[h] = obj2gco(ts);
...省略...
}三、字符串的创建
创建流程如下图:
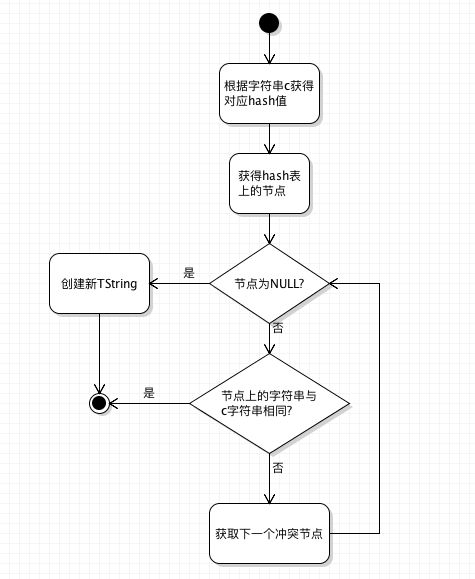
每次创建时,都会先计算当前字符串对应的hash值,在获得相对hash表里的位置节点。如果节点已经被占用,则遍历冲突节点,判断当前字符串是否已经存在。如果存在则返回已存在的节点,否则创建TString,并放到hash表中。
判断字符串是否已经存在的代码如下:
TString *luaS_newlstr (lua_State *L, const char *str, size_t l) {
GCObject *o;
unsigned int h = cast(unsigned int, l); /* seed */
size_t step = (l>>5)+1; /* if string is too long, don't hash all its chars */
size_t l1;
for (l1=l; l1>=step; l1-=step) /* 计算hash值*/
h = h ^ ((h<<5)+(h>>2)+cast(unsigned char, str[l1-1]));
//遍历在冲突位置上的TString,查找是否已经存在相同的字符串
for (o = G(L)->strt.hash[lmod(h, G(L)->strt.size)];
o != NULL;
o = o->gch.next) {
//转化为TString类型
TString *ts = rawgco2ts(o);
//判断长度和字符串是否相同
if (ts->tsv.len == l && (memcmp(str, getstr(ts), l) == 0)) {
/* gc部分,以后在分析 */
if (isdead(G(L), o)) changewhite(o);
return ts;
}
}
//全局string表没有找到,创建新的字符串。
return newlstr(L, str, l, h); /* not found */
}创建新TString代码如下:
static TString *newlstr (lua_State *L, const char *str, size_t l,
unsigned int h) {
TString *ts;
stringtable *tb;
//字符长度是否越界
if (l+1 > (MAX_SIZET - sizeof(TString))/sizeof(char))
luaM_toobig(L);
//创建TString内存空间,大小等于TString大小加上字符串大小。
//可以看出字符串是直接放在TString内存块地址后面的
ts = cast(TString *, luaM_malloc(L, (l+1)*sizeof(char)+sizeof(TString)));
ts->tsv.len = l;
ts->tsv.hash = h;
ts->tsv.marked = luaC_white(G(L));
ts->tsv.tt = LUA_TSTRING;
ts->tsv.reserved = 0;
memcpy(ts+1, str, l*sizeof(char)); /* 复制字符串到TString内存块地址后面的位置上。*/
((char *)(ts+1))[l] = '\0'; /* ending 0 */
tb = &G(L)->strt;
h = lmod(h, tb->size); /*通过hash值,转换为具体下标位置*/
ts->tsv.next = tb->hash[h]; /* 新的字符串存到hash表里,并把next指向之前冲突的字符串*/
tb->hash[h] = obj2gco(ts);
tb->nuse++;
//hash表空间不够?
if (tb->nuse > cast(lu_int32, tb->size) && tb->size <= MAX_INT/2)
luaS_resize(L, tb->size*2); /* 重新设置hash表大小*/
return ts;
}四、hash表空间扩展
hash表的空间扩展大致分为三步,第一步创建新的内存空间并初始化所有的节点,第二步把旧hash表的数据赋值给新表,最后释放旧表空间。代码如下:
void luaS_resize (lua_State *L, int newsize) {
GCObject **newhash;
stringtable *tb;
int i;
if (G(L)->gcstate == GCSsweepstring)
return; /* cannot resize during GC traverse */
//创建新空间
newhash = luaM_newvector(L, newsize, GCObject *);
tb = &G(L)->strt;
//初始化
for (i=0; i/* rehash 把老的hash表里的值换到新hash表中*/
for (i=0; isize; i++) {
GCObject *p = tb->hash[i];
//循环冲突节点
while (p) { /* for each node in the list */
GCObject *next = p->gch.next; /* save next */
unsigned int h = gco2ts(p)->hash;
int h1 = lmod(h, newsize); /* 根据hash值计算相对于newsize的位置*/
lua_assert(cast_int(h%newsize) == lmod(h, newsize));
p->gch.next = newhash[h1]; /* 把旧的冲突节点放在新的冲突链表上*/
newhash[h1] = p;
p = next;
}
}
//释放旧的hash表
luaM_freearray(L, tb->hash, tb->size, TString *);
tb->size = newsize;
tb->hash = newhash;
}