交叉熵(cross_entropy)作为损失函数在神经网络中的作用
交叉熵的作用
通过神经网络解决多分类问题时,最常用的一种方式就是在最后一层设置n个输出节点
神经网络解决多分类问题最常用的方法是设置n个输出节点,其中n为类别的个数。对于每一个样例,神经网络可以得到的一个n维数组作为输出结果。数组中的每一个维度(也就是每一个输出节点)对应一个类别。在理想情况下,如果一个样本属于类别k,那么这个类别所对应的输出节点的输出值应该为1,而其他节点的输出都为0。
无论在浅层神经网络还是在CNN中都是如此,比如,在AlexNet中最后的输出层有1000个节点: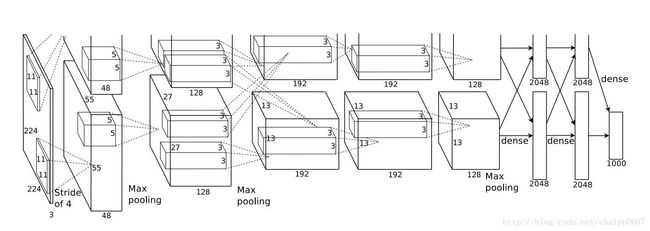
而即便是ResNet取消了全连接层,也会在最后有一个1000个节点的输出层: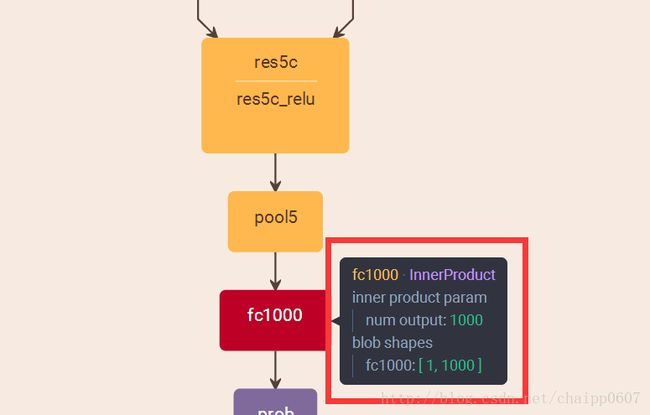
一般情况下,最后一个输出层的节点个数与分类任务的目标数相等。假设最后的节点数为N,那么对于每一个样例,神经网络可以得到一个N维的数组作为输出结果,数组中每一个维度会对应一个类别。在最理想的情况下,如果一个样本属于k,那么这个类别所对应的的输出节点的输出值应该为1,而其他节点的输出都为0,即[0,0,1,0,….0,0],这个数组也就是样本的Label,是神经网络最期望的输出结果,交叉熵就是用来判定实际的输出与期望的输出的接近程度!
Softmax回归处理
神经网络的原始输出不是一个概率值,实质上只是输入的数值做了复杂的加权和与非线性处理之后的一个值而已,那么如何将这个输出变为概率分布?
这就是Softmax层的作用,假设神经网络的原始输出为y1,y2,….,yn,那么经过Softmax回归处理之后的输出为: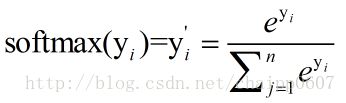
很显然的是: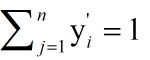
而单个节点的输出变成的一个概率值,经过Softmax处理后结果作为神经网络最后的输出。
交叉熵的原理
交叉熵刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。假设概率分布p为期望输出,概率分布q为实际输出,H(p,q)为交叉熵,则:

这个公式如何表征距离呢,举个例子:
假设N=3,期望输出为p=(1,0,0),实际输出q1=(0.5,0.2,0.3),q2=(0.8,0.1,0.1),那么:
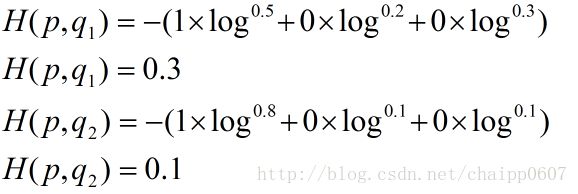
很显然,q2与p更为接近,它的交叉熵也更小。
除此之外,交叉熵还有另一种表达形式,还是使用上面的假设条件:

其结果为:
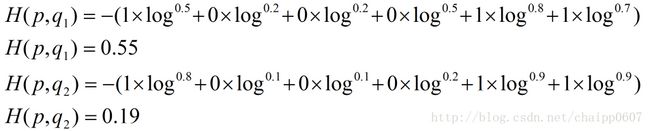
以上的所有说明针对的都是单个样例的情况,而在实际的使用训练过程中,数据往往是组合成为一个batch来使用,所以对用的神经网络的输出应该是一个m*n的二维矩阵,其中m为batch的个数,n为分类数目,而对应的Label也是一个二维矩阵,还是拿上面的数据,组合成一个batch=2的矩阵:

所以交叉熵的结果应该是一个列向量(根据第一种方法):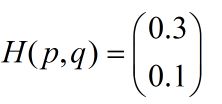
而对于一个batch,最后取平均为0.2。
在TensorFlow中实现交叉熵
tensorflow交叉熵计算函数输入中的logits都不是softmax或sigmoid的输出,而是softmax或sigmoid函数的输入,因为它在函数内部进行sigmoid或softmax操作
TensorFlow针对分类问题,实现了四个交叉熵函数,分别是
- tf.nn.sigmoid_cross_entropy_with_logits
- tf.nn.softmax_cross_entropy_with_logits
- tf.nn.sparse_softmax_cross_entropy_with_logits
- tf.nn.weighted_cross_entropy_with_logits
sigmoid_cross_entropy_with_logits
tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=labels)
- 计算方式:对输入的logits先通过sigmoid函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得的结果不至于溢出。
- 适用:每个类别相互独立但互不排斥的情况:例如一幅图可以同时包含一条狗和一只大象。
- output不是一个数,而是一个batch中每个样本的loss,所以一般配合
tf.reduce_mean(loss)使用。 -
计算公式:

softmax_cross_entropy_with_logits
tf.nn.softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1, name=None)
- labels:和logits具有相同type和shape的张量(tensor),,是一个有效的概率,sum(labels)=1, one_hot=True(向量中只有一个值为1.0,其他值为0.0)。
- 计算方式:对输入的logits先通过softmax函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出。
- 适用:每个类别相互独立且排斥的情况,一幅图只能属于一类,而不能同时包含一条狗和一只大象。
- output:不是一个数,而是一个batch中每个样本的loss,所以一般配合
tf.reduce_mean(loss)使用。 -
计算公式:

sparse_softmax_cross_entropy_with_logits
tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None,labels=None,logits=None, name=None)
- labels:shape为[batch_size],labels[i]是{0,1,2,……,num_classes-1}的一个索引, type为int32或int64
- 计算方式:对输入的logits先通过softmax函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出。
- 适用:每个类别相互独立且排斥的情况,一幅图只能属于一类,而不能同时包含一条狗和一只大象 。
- output不是一个数,而是一个batch中每个样本的loss,所以一般配合
tf.reduce_mean(loss)使用。 - 计算公式:
和tf.nn.softmax_cross_entropy_with_logits()的计算公式一样,只是要将labels转换成tf.nn.softmax_cross_entropy_with_logits()中labels的形式
weighted_cross_entropy_with_logits
tf.nn.weighted_cross_entropy_with_logits(labels,logits, pos_weight, name=None)
- 计算具有权重的sigmoid交叉熵sigmoid_cross_entropy_with_logits()
-
计算公式:

https://www.jianshu.com/p/cf235861311b