.
?(.?)’,re.S) #re.S匹配是包括
results = re.findall(pattern, res)
for row in results:
print(row)
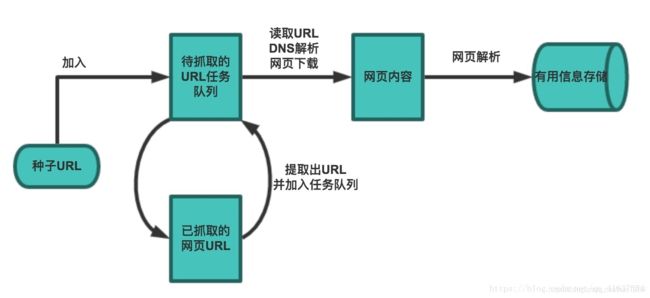
网络爬虫
##网络爬虫
在理想的状态下, 所有的ICP(internet Content Provider) 都应该为自己的网络提供API接口来共享它们允许其他程序获取的数据, 在这种情况下爬虫就不是必需品, 国内比较有名的电商平台(如淘宝, 京东等), 社交平台(如QQ/微博/微信等)这些网站都提供了自己的Open Api, 但是这类Open Api通常会对可以抓取的数据频率进行限制. 对于大多数的公司而言, 计时的获取行业相关数据就是企业生存的重要环节之一, 然而大部分企业在行业数据方面的匮乏是其与生俱来的短板, 合理的利用爬虫来获取数据并从中提取出有价值的信息是至关重要的. 当然爬虫还有很多重要的应用领域, 以下列举了其中一部分.

#设置代理操作器
proxy = urllib.request.ProxyHandler({‘http’:‘http://58.251.251.203:8118’})
#构建新的强求器,覆盖默认opener
opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
response = urllib.request.urlopen(‘http://www.baidu.com/s?wd=ip’)
html_content = response.read().decode(‘utf-8’)
print(html_content)
#免费的天气接口https://www.sojson.com/blog/305.html
import urllib.request
import json
url=‘http://t.weather.sojson.com/api/weather/city/101180101’
resp = urllib.request.urlopen(url)
if resp.code == 200:
weather_json = resp.read().decode(‘utf-8’)
#print(type(weather_json),weather_json)
weather_data= json.loads(weather_json)
data = weather_data[‘data’]
print(’\n\n’,data)
todo_humidity = data['shidu']
today_pm25 = data['pm25']
today_temperature = data['wendu']
print(f'今日温度:{today_temperature},湿度:{todo_humidity}')
# weather_data['data']
import urllib.request
import urllib.parse
import json
http://api.map.baidu.com/place/v2/suggestion?query=天安门®ion=北京&city_limit=true&output=json&ak=你的ak //GET请求
origin_args={‘query’:‘ATM机’,‘region’:‘郑州’,‘output’:‘json’,‘ak’:‘C8jTc5FZ9H3DTGBE8qkpCOtiPbDXHMx6’}
#将中文参数base64编码
b64_args = urllib.parse.urlencode(origin_args)
print(b64_args)
resp = urllib.request.urlopen(‘http://api.map。baidu.com/place/v2/search ‘+’?’+b64_args)
base_url = ‘http://api.map.baidu.com/place/v2/search’
url = base_url+’?’+b64_args
print(‘拼好的url’,url)
resp = urllib.request.urlopen(url)
content_json = resp.read().decode()
print(content_json)
#json转对象
content_obj = json.loads(content_json)
print(content_obj)
results = content_obj[‘results’]
for row in results:
print(row[‘name’],row[‘address’])
#糗事百科
#分析:请求url https://www.qiushibaike.com/hot/page/1/ 要抓取div class='article’小内容 urllib或requests,
import urllib.request
from fake_useragent import UserAgent
import re, requests
encoding=‘UTF-8’
for i in range(20):
base_url = ‘https://www.qiushibaike.com/hot/page/’
url =base_url+‘1’+’/’
print(url)
ua = UserAgent()
headers = {
‘User-Agent’:ua.random
}
req = urllib.request.Request(url,headers = headers)
resp =urllib.request.urlopen(req)
html_content = resp.read().decode(‘utf-8’)
print(html_content)
res = requests.get(
url= ‘https://www.qiushibaike.com/hot/page’+‘1’+’/’,
headers={‘User-Agent’:UserAgent().random}
).text
pattern = re.compile(r’