1.机器学习的概念和环境搭建
本文是我学习bobo老师视频的学习笔记,是机器学习的入门课程,建议有编程基础和高等数学、概率论、线性代数的学习者参考学习。
github项目课件及代码笔记地址: https://github.com/youaresherlock/scikit-learnNoteAndCode
第一章:
机器学习的大概过程
输入大量学习资料 --> 机器学习算法 --> 学习得到执行任务的算法(模型)
--> 输入样例给模型输出结果
机器学习的应用:
金融预测、医疗诊断、市场分析
例如: 判断贷款风险、搜索预判、商品的智能推荐、广告推荐、语音识别、人脸识别
机器学习、人工智能、深度学习之间的关系?
深度学习是机器学习的一种方法,机器学习属于人工智能领域,,
人工智能中还有一些智能搜索算法(梯度下降法、遗传算法、粒子群算法等)
内容:
成体系的介绍机器学习算法
KNN 线性回归 多项式回归 逻辑回归 模型正则化 PCA
SVM 决策树 随机森林 集成学习 模型选择 模型调试介绍如何使用算法
1) 如何评价算法的好坏
2) 如何解决过拟合和欠拟合
3) 如何调节算法的参数
4)如何验证算法的正确性
课程环境
语言: python3
框架: Scikit-learn
其他: numpy, matplotlib,...
IDE: Jupyter Pycharm所使用的数据集
框架: Scikit-learn 内置数据集或通过scikit-learn可以直接下载的数据集
http://scikit-learn.org/stable/
第二章:
机器学习世界的数据:
如鸢尾花的数据中的三条:
萼片长度 萼片宽度 花瓣长度 花瓣宽度 种类
5.1 3.5 1.4 0.2 se(0)
7.0 3.2 4.7 1.4 ve(1)
6.3 3.3 6 2.5 vi(2)数据整体叫数据集(data set)
每一行数据称为一个样本(sample)
除最后一列,每一列表达样本的一个特征(feature)
最后一列,称为标记(label)
特征空间: 特征向量所在的空间,每一个特征对应特征空间中的一维坐标。
分类任务本质就是在特征空间切分
机器学习的基本任务: 分类任务和回归任务
分类任务:
1) 二分类: 二选一的任务
如:
判断邮件是垃圾邮件;不是垃圾邮件
判断某支股票涨还是跌
2) 多分类: 多选一的任务
如:
数字识别
图像识别
判断发给客户信用卡的风险评级
一些算法只支持完成二分类的任务
但是多分类的任务可以转换二分类的任务
有一些算法天然可以完成多分类任务
3) 多标签任务
回归任务:
结果是一个连续数数字的值,而非一个类别
预测房屋价格
预测股票价格
有一些算法只能解决回归问题
有一些算法只能解决分类问题
有一些算法的思路既能解决分类问题,也可以解决回归问题
其实监督学习主要解决分类问题和回归问题
机器学习方法的分类:
1) 监督学习
概念:
给机器的训练数据拥有"标记"或者"答案"
我们将要学习的大部分算法,属于监督学习算法
K近邻、线性回归和多项式回归、逻辑回归、SVM、决策树和随机森林
2) 非监督学习
概念:
给机器的训练数据没有任何"标记"和"答案" ---- 聚类分析
非监督学习的意义:
对数据进行降维处理(方便可视化、去除冗余信息,简化运算)
特征提取: 信用卡的信用评级和人的胖瘦无关?
特征压缩: PCA(主成分分析,简化数据集的技术,经常用于减少数据集的维数)
异常检测:
异常是即不属于聚类也不属于背景噪声的点。它的行为与正常的行为有显著的不同。
3) 半监督学习
概念:
一部分数据有"标记"或者"答案",另一部分数据没有
更常见: 各种原因产生的标记缺失
通常都先使用无监督学习手段对数据做处理,之后使用监督学习手段
做模型的训练和预测
4) 增强学习
概念:
根据周围环境的情况,采取行动,根据采取行动的结果,
学习行动方式.(不断行动反馈奖赏或惩罚,逐渐增强自己的智能)
机器学习的其他分类:
1) 批量学习(Batch Learning 又程离线学习Offline Learning)
概念:
一次性批量输入给学习算法,面对新的数据,直接投入到生产环境中,
而不进一步的优化算法, 可以被形象的成为填鸭式学习
优点: 简单
问题: 如何使用环境变化?
解决方案: 定时重新批量学习
缺点:
每次重新批量学习,运算量巨大
在某些环境变化非常快的情况下,甚至不可能的.(例如股票价格预测,及时地将新产生的数据来改进我们机器学习的模型)
2) 在线学习(Online Learning)
按照顺序、循序的学习,不断的去修正模型,进行优化
根据输入样例得到输出结果,又根据真实的输出结果迭代进机器学习算法,来改进模型
优点: 及时反映新的环境变化
问题: 新的数据带来不好的变化?
解决方案: 需要加强对数据进行监控
适应的其他情况: 也适用于数据量巨大,完全无法批量学习的环境
3) 参数学习(Parametric Learning)
概念: 有固定数目的参数,模型学习之后会有一个永久的参数,这个参数在后对面的预测中可以直接使用,不需要
原有的数据集
4) 非参数学习(Nonparametric Learning)
概念: 不对模型进行过多假设,非参数不等于没参数!
参数数目会随着训练数据规模线性增长
如何选择机器学习算法?
奥卡姆剃须刀原则:
简单的就是好的
没有免费的午餐定理:
可以严格地数学推导出: 任意两个算法,他们的期望性能是相同的!
也就是说具体到某个特定问题,有些算法可能更好
但没有一种算法,绝对比另一种算法好
要在面对一个具体问题的时候,尝试使用多种算法进行对比实验,是必要的。
学习环境的搭建和简单使用:
1) ANACONDA的安装
ANACONDA是什么?
是最受欢迎的Python数据科学平台,也是一个通用的机器学习平台,支持各种操作系统跨平台的
安装ANACONDA:
官网下载地址: https://www.anaconda.com/download/
工具使用文档地址: https://docs.anaconda.com/
ANACONDA NAVIGATOR中Learning也有很多文档、训练、视频等链接(可以在content目录看到对应的json保存文件)
注: 去官网地址根据你的操作系统来选择下载
下载要下载Python3.7 version(python2将要2020年停止更新,py3是主流,虽然很多公司目前还在使用python2)
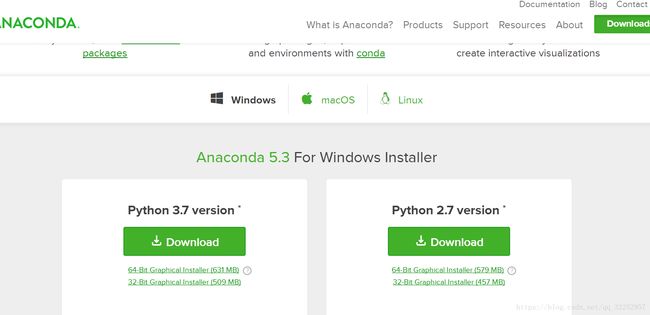
安装之后看到有ANACONDA NAVIGATOR样的程序,双击打开,可以看到
HOME菜单项中: 很多Application工具
Environments菜单项中: root中是安装所有默认的包

HOME中的jupyter notebook基于web的工具可以方便的创建py3的实验环境
2) Pycharm或sublime text或Spyder等等
国内大多数公司基本上都使用Pycharm,这里我也就以这个来写具体的代码
官网地址: http://www.jetbrains.com/pycharm/
要注意的是Location就是你的workspace, interpreter不要选择你本机上的解释器,Anaconda会自带一个,
选择目录在安装目录/anaconda/bin/python.exe解释器
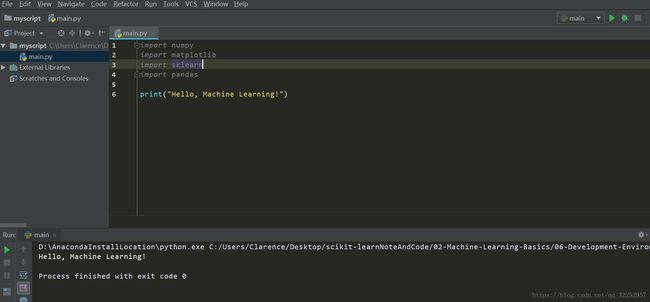
3) 测试环境是否正确
打开pycharm,创建工程文件,创建一个main.py
正确显示字符串,则说明环境配置成功