利用Pandas、Numpy对多数据表之间相互匹配并创建交通数据集
Series + DataFrame
一、背景
接着上篇文章,现在通过某些渠道拿到了事故数据,但是存在几个问题。

如上图所示,分别有三个数据文件:data_ms、data_reason、reason_type
三个文件的字段如下:

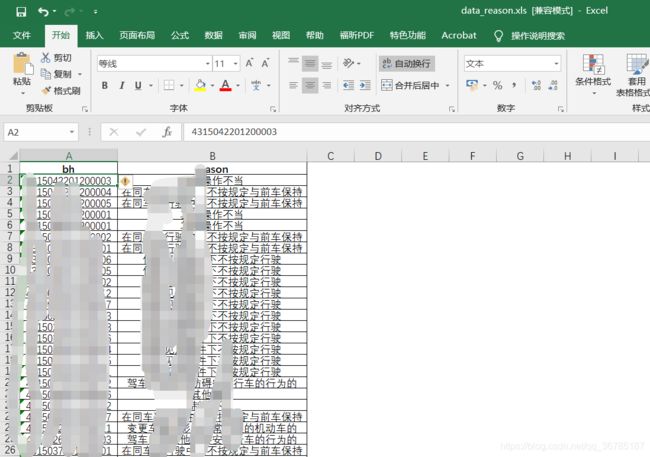

如上述三表,第一个表是案情描述-编号、第二个表是编号-事故原因描述、第三个表是事故原因描述-事故原因新类别。
因为存在不匹配的问题,就需要进行预处理,将已有的案情描述-编号表中的数据在二表中查询匹配并找到对应的事故原因描述,并再将对应的事故原因描述在三表中查询匹配并找到对应的事故原因新类别。
上述三表是已经简单的用excel删除掉许多无用字段后整理的初版,因为不知道excle怎么处理多表互匹配,所有就有了此文,利用python的pandas 和numpy进行操作,也巩固了一下库的调用。
二、正文
首先导入需要用到的numpy、pandas包
import numpy as np
import pandas as pd读入三个表的数据
data_ms = pd.read_excel('./data_ms.xls')
data_reason = pd.read_excel('./data_reason.xls')
reason_type = pd.read_csv('./reason_type.csv')查看第一个表的各字段类型
data_ms
data_ms.dtypes
#编号字段为int64类型
先将一表与二表匹配。在一表中增加一列
#创建新列,名为原因,长度等同于data_ms的长度的列向量
result = np.random.randn(len(data_ms), 1)
result.shape
result = pd.DataFrame(result, columns = ['reason'])
result#拼接在data_ms中
data_ms = pd.concat([data_ms, result], axis = 1)
#此处可以直接在后面加一个参数就不用后面重新修改字段类型了
#data_ms = pd.concat([data_ms, result], axis = 1, dtype = str)
data_ms
#将reason列向量类型设置为string
data_ms['reason'] = data_ms['reason'].astype(str)
data_ms查看二表的字段类型
data_reason
data_reason.dtypes
#编号字段为int64类型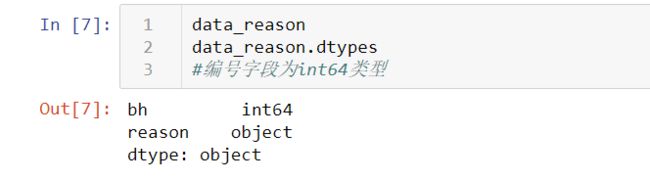
查看三表:
reason_type
#有最后十行为异常行
#删掉为null的异常行
reason_type = reason_type.dropna()
reason_type
#可以看到为float类型
发现dm、type字段都是浮点数类型,防止后期出错,转换为int整型
#将原因与新分类的映射表的"代码"、"分类",设置为整型int
reason_type['dm'] = reason_type['dm'].astype(int)
reason_type['type'] = reason_type['type'].astype(int)
reason_type
开始匹配一、二表
#匹配,将编码-描述表与编码-原因表进行匹配
for i in range(len(data_ms)):
result = None
bh = data_ms.loc[i, 'bh']
#判断在编码-原因总表中,是否存在当前行数据编码的内容,若存在赋值,若不存在就直接赋空值便于以后同意删除
if(len(data_reason.loc[data_reason['bh'] == bh]['reason'].values) == 1):
result = str((data_reason.loc[data_reason['bh'] == bh]['reason'].values)[0])
data_ms['reason'][i] = result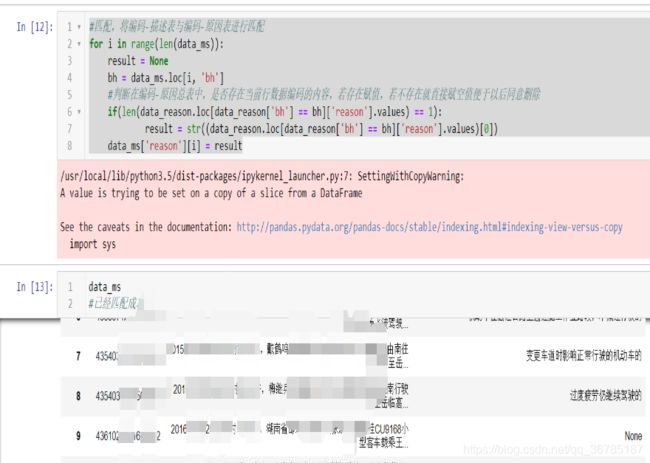
#删除掉不能在总表中找到的无效数据
data_ms = data_ms.dropna()
data_ms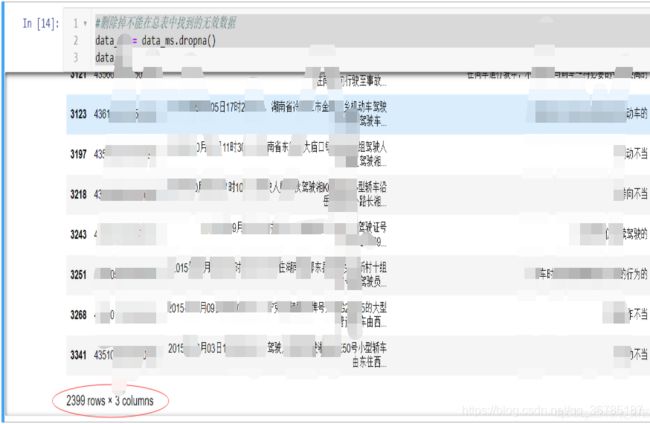
发现最终从9000多行中,仅仅2399行能匹配出来
接下来就是二、三表的匹配,同上述,就直接贴代码了
#创建新列,名为新分类,长度等同于data_ms的长度的列向量
typ = np.random.randn(len(data_ms), 1)
typ.shape
typ = pd.DataFrame(typ, columns = ['type'],dtype = int)
typdata_ms = pd.concat([data_ms, typ], axis = 1)
data_msdata_ms['type'] = data_ms['type'].fillna(1)
data_ms['type'] = data_ms['type'].astype(int)
data_ms = data_ms.dropna()data_ms = data_ms.reset_index(drop = True)
data_msfor i in range(len(data_ms)):
result = None
ms = data_ms.loc[i, 'reason']
result = (reason_type.loc[reason_type['ms'] == ms]['type'].values)[0]
data_ms['type'][i] = result这里不知道为啥,一拼接,瞬间原本int型的bh变成了float型,导致了编号丢失了几位,虽然编号在此题目中没用,但是找不到原因,还请知道的大佬留言提示一下!
data_ms.to_csv('data_all_ok.csv', encoding='utf_8_sig',index = False)导出数据,丢到群里,等着后面建模,over
三、后续
data_ms['type'].value_counts()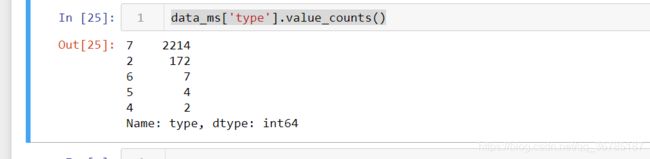
无意之间看了一下数据分布情况发现.....
这后面是要建多分类的模型,这玩意根本不能作训练集呀,差异太大了,经过研究,打算把之前做的归纳分类改一下,尽量让各类别分布均匀,具体操作有待商榷。
实在不行就只能打散了,多次扔进去训练咯,效果可能不好。
以上就是今天目前为止所做的了,等数据分类处理好以后,明天就开始建模,初步打算是TextRCNN,也不知道做得出来不,随缘吧。
感谢各位捧场!小弟谢了!
(数据涉密,不能外放,各位见谅!)