一文梳理论文《AIBox: CTR Prediction Model Training on a Single Node》
论文链接:https://dl.acm.org/doi/pdf/10.1145/3357384.3358045
背景介绍:百度搜索中一个很重要的工作室点击率预估(CTR),CTR预估计算代价很大,往往在线的数据非常的大,之前采用的方式是MPI上训练集群,但是这种方式不但耗时而且通信代价也很大;点击率预测起着关键作用确定最佳广告空间分配,因为它会直接影响用户体验和广告盈利能力。本文设计了一个通过SSD(固态硬盘)和GPU的点击率集中式系统,叫做AIBOX,将CTR模型划分为两部分:第一部分适用于CPU,另一个适用于GPU。使用SSD上的二级缓存管理系统来存储10TB参数,同时提供低延迟访问;广泛的经验指导生产数据显示新系统的有效性。AIBox具有大型MPI训练能力,而只需要集群成本的一小部分。传统的采用参数服务器进行分布式训练,但是也曾遭受节点故障和网络故障,更糟糕的是,在参数服务器上的同步会阻碍训练的执行,并导致巨大的网络通信开销,而异步训练框架会因为每个工作节点上的过时模型而导致模型收敛问题。
分析:现有大规模CTR预测模型训练系统面临的问题
- 大数据和大模型问题:训练数据和模型规模达到PB级别
- 巨大的特征空间规模:特征空间规模达到
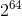
- 数据稀疏性问题: 每个特征向量中只有几百个非零条目
解决思路:
- 压缩模型规模:流行的模型压缩技术,如下采样和散列,对于训练具有超高维(例如,数千亿个特征)和极稀疏(例如,每个特征中只有几百个非零项)的训练数据的商业CTR模型来说,效果较差。研究报告中常见的论据,如“只需0分就能将培训成本降低一半”。3%的精度损失“,不再在这个行业工作。另一方面,DNN-CTR模型的训练在百度是一项日常工作,工程师和数据科学家必须对许多不同的模型/特性/策略/参数进行实验,并且必须非常频繁地训练andre-train-CTR模型。硬件(如MPI集群)的成本和能耗可能非常高。
- 设计高效的训练系统(本文方法):AIBox使用新兴的硬件SSD(固态驱动器和GPU),以存储大量参数并加速神经网络训练的繁重计算。 作为集中式系统,AIBox直接消除了分布式系统中由网络通信引起的那些弊端。与大型计算集群中的数千个节点相比,单节点AIBox的硬件故障数量要少几个数量级。 此外,由于仅需要内存锁和GPU片上通信,因此可以显着降低单个节点中的同步成本。 与分布式环境相比,没有通过网络传输数据。
但是模型压缩会损失一部分精度,但是即使精度损失了0.1%,也会造成巨大的商业损失,所以百度的这篇论文主要是从设计一个高效的训练系统的方式上进行的。
AIBOX设计过程中的挑战: AIBox的设计仍面临两个主要挑战。第一个挑战是将10TB规模的模型参数存储在单个节点上。当容量超过1 TB时,内存价格将上涨。当模型将来变得更大时,它是不可伸缩的。由于成本高昂,我们无法将整个10TB参数存储在主存储器中。 PCIe总线上新兴的非易失性内存Express(NVMe)SSD的延迟比硬盘驱动器低50倍以上。我们利用SSD作为辅助存储来保存参数。但是,SSD有两个缺点。首先,就延迟而言,SSD仍比主内存慢两个数量级,从而导致训练过程中的参数访问和更新速度较慢。 SSD的另一个缺点是,SSD中的存储单元只能持续数千个写周期。因此,我们必须维护有效的内存缓存以隐藏SSD延迟并减少磁盘写入SSD的时间。第二个挑战是在单个上使用多个GPU节点加快训练计算。最近,单Nvidia Tesla V100具有32 GB高带宽内存(HBM)达到15.7 TFLOPS,是47倍比高端服务器CPU节点(Intel Xeon系列)更快学习推理。这提供了独特的机会签署具有可比计算能力的多GPU计算节点集群性能。但是,当前的现成GPU确实可以没有TB规模的HBM。我们无法保留整个点击率预测GPU HBM中的神经网络。在这项工作中,我们提出了一本小说方法(第2节)将神经网络分为两部分。第一部分是占用大量内存并在CPU上进行过训练的。另一个网络的一部分是计算密集型的,而输入功能的迭代次数。我们在GPU上训练它。训练数据模型参数在主存储器之间传输以及多GPU的HBM。但是,主内存和GPU HBM受PCIe总线限制带宽。较高的GPU数值计算性能为当通信带宽成为瓶颈时,阻塞-颈部。新兴的NVLink 和NVSwitch 技术在不涉及PCIe的情况下实现直接GPU到GPU的通信公共汽车。我们使用NVLink并设计了一个内置HBM参数服务器减少GPU数据传输
设计的CTR预测神经网络模型的概述。
Embedding 学习的输入层上的节点表示高维稀疏性。 在联合学习的连接层上没有传入箭头的节点是密集的个性化输入特征(除了Embedding之外)。第一个模块高维稀疏地关注嵌入学习功能,第二个模块用于密集学习功能来自第一个模块。嵌入学习在CPU上处理,通过学习到的Embedding从CPU转移到GPU,同时利用SSD储存模型参数。
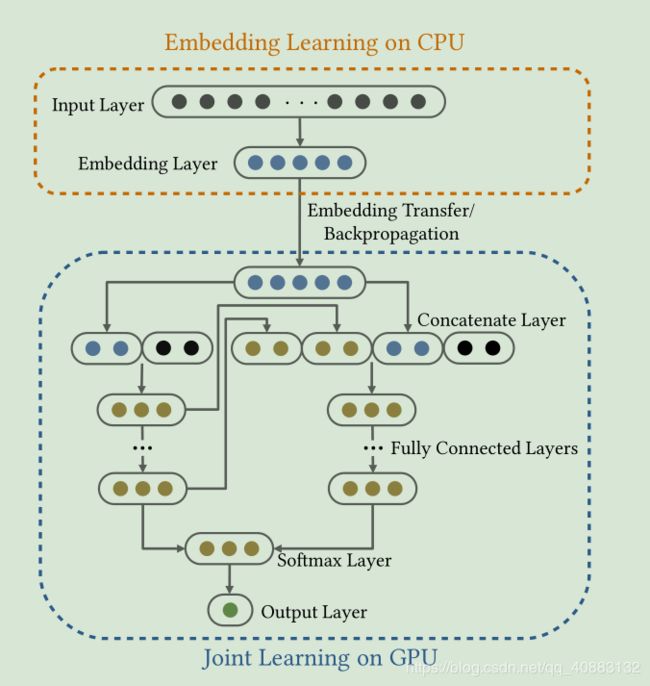
Embedding Learning on CPU(嵌入学习):SSD和CPU之间访问迅速,通过SSD储存模型参数,然后学习到Embedding输入到下一层。
Joint Learning on GPU(联合学习):联合学习的投入包括密集的个性化功能和学习的嵌入。个性化功能通常来自包括标题创意文本,用户个性化的行为,以及与广告相关的各种元数据。如果我们直接串联这些要素和馈送的神经网络,重要信息个性化功能可能无法得到充分的探索,从而点击率预测结果不准确。因此,我们设计了几个深度神经网络,共同学习有意义的表示最终的CTR预测。如图1所示,联合学习该模块包含几个(图中两个)深度神经网络。每个网络都将学习的嵌入和一种个性化信息一起作为输入层。然后几个应用完全连接的层以帮助捕获交互以自动方式设置功能。这些的最后隐藏层网络组合在一起用于softmax层和输出层点击率预测。
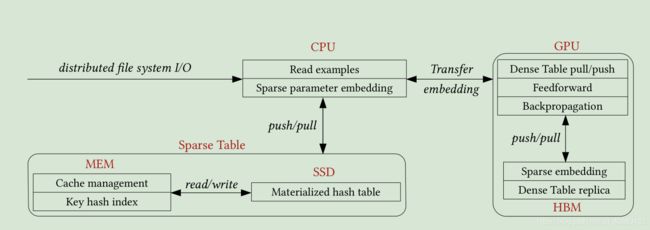
AIBOX系统设计:
SPARSE TABLE
将稀疏表存储到SSD的参数有效。它利用内存作为SSD的快速缓存,同时减少了SSD I / O,并提供低延迟的SSD访问。 它包含两个主要组件,密钥哈希索引和二级缓存管理。
- Key Hash Index
- 为了通过功能键访问SSD上的参数文件,我们必须为
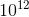 个参数存储个密钥到文件的映射在点击率预测模型中将每个密钥到文件的映射存储为内存中的64位值对需要1.6 TB =(8字节密钥+ 8字节的SSD偏移量)×,超过了1 TB的内存预算。 我们必须仔细设计关键哈希索引和SSD上的文件结构,以减少内存占用量。我们引入了分组功能,该功能将密钥映射到组ID这样每个组都包含m个关键点,即group(key)→{0,1,···, / m − 1}。在这里10个12键被划分为 / m组。将密钥分组后,我们可以保留内存中的组到文件映射作为内存消耗仅是原始密钥到文件映射的1 / m。由于键是从1到10 12连续,可以很容易地观察通过均匀地划分键空间来获得,例如group(key)→密钥mod / m。我们设置m =⌊BLOCK/(8 + sizeof(value))⌋,其中BLOCK是SSD的I / O单元,由SSD决定块大小(通常为4096),8表示密钥占用的字节,以及sizeof(value)是值(模型参数)的大小(以字节为单位),它是在我们的点击率预测模型中大约有50个字节。 m永远不会设置为小于⌊BLOCK/(8 + sizeof(value))⌋的值,因为SSD访问必须从磁盘获取块字节。 m太小是次优的。另一方面,我们选择的m越大,则密钥哈希索引的内存占用空间就越小。但是,大m会导致一个大组,因为我们必须从SSD读取多个页面才能得到一个组。因此,当组到文件的映射在内存中占据可接受的空间时,我们设置的m值是最佳的。当块大小远大于值的大小时,这是正确的。作为内存占用量的折衷,分组策略的缺点是即使从当前的迷你批处理中未引用磁盘,也要从磁盘获取同一组中的值,这会浪费I / O带宽。 一种可能的优化是将具有较高共现性的特征分组在一起,例如,预训练学习的哈希函数以最大化特征共现性。 这属于垂直划分的另一个研究领域,不在本文的讨论范围之内。 此外,通过缓存管理组件可以减少此缺点,在缓存组件中,我们跳过了从磁盘读取缓存密钥的组。
个参数存储个密钥到文件的映射在点击率预测模型中将每个密钥到文件的映射存储为内存中的64位值对需要1.6 TB =(8字节密钥+ 8字节的SSD偏移量)×,超过了1 TB的内存预算。 我们必须仔细设计关键哈希索引和SSD上的文件结构,以减少内存占用量。我们引入了分组功能,该功能将密钥映射到组ID这样每个组都包含m个关键点,即group(key)→{0,1,···, / m − 1}。在这里10个12键被划分为 / m组。将密钥分组后,我们可以保留内存中的组到文件映射作为内存消耗仅是原始密钥到文件映射的1 / m。由于键是从1到10 12连续,可以很容易地观察通过均匀地划分键空间来获得,例如group(key)→密钥mod / m。我们设置m =⌊BLOCK/(8 + sizeof(value))⌋,其中BLOCK是SSD的I / O单元,由SSD决定块大小(通常为4096),8表示密钥占用的字节,以及sizeof(value)是值(模型参数)的大小(以字节为单位),它是在我们的点击率预测模型中大约有50个字节。 m永远不会设置为小于⌊BLOCK/(8 + sizeof(value))⌋的值,因为SSD访问必须从磁盘获取块字节。 m太小是次优的。另一方面,我们选择的m越大,则密钥哈希索引的内存占用空间就越小。但是,大m会导致一个大组,因为我们必须从SSD读取多个页面才能得到一个组。因此,当组到文件的映射在内存中占据可接受的空间时,我们设置的m值是最佳的。当块大小远大于值的大小时,这是正确的。作为内存占用量的折衷,分组策略的缺点是即使从当前的迷你批处理中未引用磁盘,也要从磁盘获取同一组中的值,这会浪费I / O带宽。 一种可能的优化是将具有较高共现性的特征分组在一起,例如,预训练学习的哈希函数以最大化特征共现性。 这属于垂直划分的另一个研究领域,不在本文的讨论范围之内。 此外,通过缓存管理组件可以减少此缺点,在缓存组件中,我们跳过了从磁盘读取缓存密钥的组。
- 为了通过功能键访问SSD上的参数文件,我们必须为
- Bi-level Cache Management
- Sparse Table Operators
- File Management
原文翻译:
摘要:
翻译:作为世界上主要的搜索引擎之一,百度的赞助商搜索早已采用深度神经网络(DNN)广告点击率(CTR)预测模型2013。百度在线广告系统使用的输入期货(又称“凤凰巢”)具有很高的维度(例如,甚至数千亿个功能),而且还非常疏。百度产品使用的点击率模型的大小系统可以超过10TB。这带来了巨大的挑战用于培训,更新和在生产中使用此类模型。对于百度的广告系统,保持模型培训过程非常高效,因此工程师(以及搜索者)能够快速优化和测试他们的新模型,或者新的功能。而且,数十亿的用户广告点击历史记录条目每天都有货,必须迅速对模型进行重新训练因为点击率预测是一项非常耗时的任务。百度的当前的点击率模型是在MPI(消息传递接口)上训练的集群,需要较高的容错能力和同步性这会导致昂贵的通信和计算成本。当然,集群的维护成本也很大。本文介绍AIBox,这是一个用于培训点击率的集中式系统通过使用solid-状态驱动器(SSD)和GPU。由于内存限制GPU,我们将点击率模型仔细划分为两部分:第一部分适用于CPU,另一个适用于GPU。我们进一步介绍固态硬盘上的二级缓存管理系统来存储10TB参数,同时提供低延迟访问。广泛的经验指导生产数据显示新系统的有效性。AIBox具有大型MPI训练能力,而只需要集群成本的一小部分。
介绍:
百度是全球领先的搜索引擎提供商之一搜索系统(又称“凤凰巢”)预先针对广告的点击率(CTR)的神经网络(DNN)模型,最早于2013年做出决定。点击率预测起着关键作用确定最佳广告空间分配,因为它会直接影响用户体验和广告盈利能力。 通常,点击率预测需要多种资源作为输入,例如,查询广告相关性,广告功能和用户画像。它可以确定用户点击的概率在给定的广告上。 最近,深度学习在以下方面取得了巨大的成功计算机视觉和自然语言处理。 启发据此,提出了用于CTR预测的学习方法任务。 与常用逻辑回归比较,深度学习模型可以大大改善准确性,大大增加了培训成本。
在百度搜索广告的当前生产系统中,我们模型的训练过程既耗费资源又耗时消耗。 通过参数服务器训练模型在具有数百个MPI(消息传递接口)的群集中成千上万的CPU节点数。 生产中使用的主要模型是尺寸超过10TB,并在特殊硬件上存储/管理。的参数服务器解决方案遭受节点故障和网络的困扰太多节点环境中的故障。 更糟糕的是,参数服务器中的同步会阻止训练计算机并导致大量的网络通信开销,而异步训练框架具有模型收敛的可能性每个工作程序节点上的模型过时导致的障碍。
这里有令人着迷的机会和挑战来改善赞助搜索的生产系统,在许多不同的方面位置。积极研究人员的一个领域可以提高“召回”的质量(广告)调用CTR模型之前。 例如,百度向社区分享了这样的技术论文,建立在快速的近邻搜索算法之上和最大的内部产品搜索技术。
在本文中,我们将介绍百度的另一项重大并举改善在线广告系统,即从MPI集群到GPU的CTR模型训练。 而使用用于机器学习和科学计算的GPU已成为惯例,使用GPU训练商业点击率模型会议:目前仍然带来许多重大挑战。 最著名的挑战原因是训练数据大小为PB(PeteByte)大小,并且经过训练的模型的大小超过10TB。 训练数例子可能多达数千亿的功能可能达到数千亿(我们通常使用2 64作为功能空间大小的便捷替代。) 数据馈送到该模型也非常稀疏,只有几百个每个特征向量的非零项。
作为一个商业赞助的搜索系统,任何模型压缩技术都不应影响预测性能(收益)。事实上,即使是很小的(例如0。1%的预测准确度下降将导致不可接受的收入损失。事实上,整个系统已经进行了高度优化,几乎没有冗余(例如,参数已经被小心地量化为整数),这种方式似乎没有多少改进的余地。流行的模型压缩技术,如下采样和散列,对于训练具有超高维(例如,数千亿个特征)和极稀疏(例如,每个特征中只有几百个非零项)的训练数据的商业CTR模型来说,效果较差。研究报告中常见的论据,如“只需0分就能将培训成本降低一半”。3%的精度损失“,不再在这个行业工作。另一方面,DNN-CTR模型的训练在百度是一项日常工作,工程师和数据科学家必须对许多不同的模型/特性/策略/参数进行实验,并且必须非常频繁地训练andre-train-CTR模型。硬件(如MPI集群)的成本和能耗可能非常高。为了应对这些挑战,我们展示了AIBox,这是一种新颖的集中式系统在单个节点上训练这种巨大的机器学习模型。 AIBox使用新兴的硬件SSD(固态驱动器和GPU),以存储大量参数并加速神经网络训练的繁重计算。 作为集中式系统,AIBox直接消除了分布式系统中由网络通信引起的那些弊端。 此外,与大型计算集群中的数千个节点相比,单节点AIBox的硬件故障数量要少几个数量级。 此外,由于仅需要内存锁和GPU片上通信,因此可以显着降低单个节点中的同步成本。 与分布式环境相比,没有通过网络传输数据。尽管如此,AIBox的设计仍面临两个主要挑战。
第一个挑战是将10TB规模的模型参数存储在单个节点上。当容量超过1 TB时,内存价格将上涨。当模型将来变得更大时,它是不可伸缩的,并且在现实世界中的大规模生产中不可行。由于成本高昂,我们无法将整个10TB参数存储在主存储器中。 PCIe总线上新兴的非易失性内存Express(NVMe)SSD的延迟比硬盘驱动器低50倍以上。我们利用SSD作为辅助存储来保存参数。但是,SSD有两个缺点。首先,就延迟而言,SSD仍比主内存慢两个数量级,从而导致训练过程中的参数访问和更新速度较慢。 SSD的另一个缺点是,SSD中的存储单元只能持续数千个写周期。因此,我们必须维护有效的内存缓存以隐藏SSD延迟并减少磁盘写入SSD的时间。第二个挑战是在单个上使用多个GPU节点加快训练计算。最近,单Nvidia Tesla V100具有32 GB高带宽内存(HBM)达到15.7 TFLOPS,是47倍比高端服务器CPU节点(Intel Xeon系列)更快学习推理。这提供了独特的机会签署具有可比计算能力的多GPU计算节点集群性能。但是,当前的现成GPU确实可以没有TB规模的HBM。我们无法保留整个点击率预测GPU HBM中的神经网络。在这项工作中,我们提出了一本小说方法(第2节)将神经网络分为两部分。第一部分是占用大量内存并在CPU上进行过训练的。另一个网络的一部分是计算密集型的,而输入功能的迭代次数。我们在GPU上训练它。训练数据模型参数在主存储器之间传输以及多GPU的HBM。但是,主内存和GPU HBM受PCIe总线限制带宽。较高的GPU数值计算性能为当通信带宽成为瓶颈时,阻塞-颈部。新兴的NVLink 和NVSwitch 技术在不涉及PCIe的情况下实现直接GPU到GPU的通信公共汽车。我们使用NVLink并设计了一个内置HBM参数服务器减少GPU数据传输
总结工作如下:
- 我们引入AIBox(受SSD和GPU加速的单个节点)来训练具有10TB参数的CTR预测模型。 单节点设计范例消除了昂贵的网络通信和分布式系统的同步成本。 据我们所知,AIBox是第一个为实际机器学习而设计的集中式系统如此大规模的应用
- 我们展示了一种将大型CTR预测模型分为两部分的新颖方法。 分区之后,我们能够将内存密集型训练部分保留在CPU上,而将内存受限的GPU用于计算密集型部分来加速训练。
- 我们建议使用稀疏表,通过在SSD上存储模型参数并利用内存作为快速缓存来减少SSD I / O延迟。 此外,我们实现了一个3级流水线,该流水线与网络,稀疏表和CPU-GPU学习阶段的执行重叠。
- 我们通过将其与包含10个PB示例的真实CTR预测数据上的75个节点的分布式集群解决方案进行比较,进行了广泛的实验,以评估该提议的系统。 它显示了AIBox的有效性-AIBox具有与群集解决方案相当的培训性能,而只需要我们为群集支付的费用的不到1/10。
点击率预估神经网络
工业大规模网络经过大规模的设计和培训,缩放数据示例以帮助预测广告的点击率准确,快速和可靠。 百度点击率预测中的功能模型通常是极其稀疏的特征(例如,数百个或甚至数千亿个功能),只有很少的数量-每个向量ber(例如几百个)非零值。 这个巨大存储后,DNN模型的参数大小超过10TB仅对非零参数进行仔细量化。 因为GPU的HBM容量有限,因此保持GPU的HBM中整个模型的10TB参数。
在本文中,我们介绍了训练的两模块架构,在CPU + GPU上使用庞大的DNN CTR模型。第一个模块高维稀疏地关注嵌入学习功能,第二个模块用于密集学习功能来自第一个模块。嵌入学习在CPU上处理,以帮助学习低维密集嵌入-丁表示。由于10TB的内存密集型问题参数使得无法维持整个模型在训练过程中存储内存,我们利用SSD来存储模型参数。可以从SSD到CPU快速访问参数。通过将学习到的嵌入向量从CPU转移到GPU,计算密集型联合学习模块可以充分利用用于CTR预测的功能强大的GPU。在联合学习模式中例如,通过以下方法对几个完全连接的神经网络进行建模嵌入作为输入。这些神经网络的最后一层连接在一起以进行最终的点击率预测。图1显示了设计的CTR神经网络模型的概述。我们将在以下小节中介绍该模型的详细信息。
- Embedding Learning on CPUs: 嵌入学习模块旨在映射高维将稀疏向量(例如10 12个维度)稀疏成低维密集表示形式。 如图1所示,嵌入学习该模块包括高维稀疏特征的输入层和输出嵌入层。 ReLU用作激活功能。 自10 12开始,此模块主要占用大量内存功能导致10TB规模的模型参数,这是不可行的将所有参数加载到主存储器中。 为了学习嵌入时,我们将10TB参数存储到SSD中。 由于SSD和CPU之间的有效访问速度,我们可以轻松地从SSD加载参数并学习CPU上的嵌入。
- Joint Learning on GPUs:计算高维CPU上的嵌入后稀疏功能,我们将嵌入从CPU转移到GPU,以实现点击率预测过程。联合学习的投入包括密集的个性化功能和学习的嵌入。个性化功能通常来自各种来源,包括标题创意文本,用户个性化的行为,以及与广告相关的各种元数据。如果我们直接串联这些要素和馈送的神经网络,重要信息个性化功能可能无法得到充分的探索,从而点击率预测结果不准确。因此,我们设计了几个深度神经网络,共同学习有意义的表示最终的CTR预测。如图1所示,联合学习该模块包含几个(图中两个)深度神经网络。每个网络都将学习的嵌入和一种个性化信息一起作为输入层。然后几个应用完全连接的层以帮助捕获交互以自动方式设置功能。这些的最后隐藏层网络组合在一起用于softmax层和输出层点击率预测
为了有效地学习以前的神经网络,表示是从第一个和最后一个隐藏的对象中提取的层,然后与当前输入层连接联合学习的神经网络。 具体来说,第一个隐藏层表示低级特征学习并提取最相关的来自输入层的信息。 最后一个隐藏层显示高级特征学习,并为最终CTR预测检测最抽象但最有用的信息。 我们结合了先前网络中最有意义的低层和最强大的高层信息,以获更准确的点击率预测结果。
AIBOX SYSTEM OVERVIEW
将稀疏表存储到SSD的参数有效。它利用内存作为SSD的快速缓存,同时减少了SSD I / O,并提供低延迟的SSD访问。 它包含两个主要组件,密钥哈希索引和二级缓存管理。
SPARSE TABLE
- Key Hash Index
- 为了通过功能键访问SSD上的参数文件,我们必须为个参数存储个密钥到文件的映射在点击率预测模型中将每个密钥到文件的映射存储为内存中的64位值对需要1.6 TB =(8字节密钥+ 8字节的SSD偏移量)×,超过了1 TB的内存预算。 我们必须仔细设计关键哈希索引和SSD上的文件结构,以减少内存占用量。我们引入了分组功能,该功能将密钥映射到组ID这样每个组都包含m个关键点,即group(key)→{0,1,···, / m − 1}。在这里10个12键被划分为 / m组。将密钥分组后,我们可以保留内存中的组到文件映射作为内存消耗仅是原始密钥到文件映射的1 / m。由于键是从1到10 12连续,可以很容易地观察通过均匀地划分键空间来获得,例如group(key)→密钥mod / m。我们设置m =⌊BLOCK/(8 + sizeof(value))⌋,其中BLOCK是SSD的I / O单元,由SSD决定块大小(通常为4096),8表示密钥占用的字节,以及sizeof(value)是值(模型参数)的大小(以字节为单位),它是在我们的点击率预测模型中大约有50个字节。 m永远不会设置为小于⌊BLOCK/(8 + sizeof(value))⌋的值,因为SSD访问必须从磁盘获取块字节。 m太小是次优的。另一方面,我们选择的m越大,则密钥哈希索引的内存占用空间就越小。但是,大m会导致一个大组,因为我们必须从SSD读取多个页面才能得到一个组。因此,当组到文件的映射在内存中占据可接受的空间时,我们设置的m值是最佳的。当块大小远大于值的大小时,这是正确的。作为内存占用量的折衷,分组策略的缺点是即使从当前的迷你批处理中未引用磁盘,也要从磁盘获取同一组中的值,这会浪费I / O带宽。 一种可能的优化是将具有较高共现性的特征分组在一起,例如,预训练学习的哈希函数以最大化特征共现性。 这属于垂直划分的另一个研究领域,不在本文的讨论范围之内。 此外,通过缓存管理组件可以减少此缺点,在缓存组件中,我们跳过了从磁盘读取缓存密钥的组。
- 为了通过功能键访问SSD上的参数文件,我们必须为
- Bi-level Cache Management
- 高速缓存管理设计受到以下两个挑战的指导:SSD的访问性能和寿命。
- 首先,内存访问延迟约为纳秒级而SSD需要几微秒的时间来查看数据,因为SSD比内存慢大约1000倍,但是,参数点击率中的数据稀疏和偏斜,导致不到1%的参数迷你批处理中引用了一个。 它为我们提供了建立内存缓存系统的机会在有限的内存预算中经常使用的“热参数”。
- 第二个挑战是仅SSD的物理属性允许对每个存储单元进行数千次写入。 参数是在培训的每次迭代中更新。 它将大大如果及时更新参数,则可以缩短SSD的使用寿命。高速缓存管理还充当参数缓冲区。 缓冲的在不涉及SSD I / O的情况下在内存中更新参数。当缓冲区到达缓冲区时,它们会延迟地存储到SSD容量和缓存替换策略将其交换出缓存
- 高速缓存管理设计受到以下两个挑战的指导:SSD的访问性能和寿命。
- Sparse Table Operators
- File Management
后续更新