机器学习————keras与循环神经网络
文章目录
- keras
- keras的优点
- 通过keras建立序列模型
- keras案例
- 循环神经网络RNN
- 什么是循环神经网络
- RNN模型
- RNN的前向传播的算法
- RNN的反向传播的算法
keras
keras的优点
Keras是一个高层神经网络API,Keras由纯Python编写而成并基Tensorflow、Theano以及CNTK后端。
keras具有以下优点:
简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性)
支持CNN和RNN,或二者的结合
无缝CPU和GPU切换
通过keras建立序列模型
序列模型
序列模型属于通用模型的一种,这种模型各层之间是依次顺序的线性关系,
在第K层合第K+1层之间可以加上各种元素来构造神经网络这些元素可以通过一个列表来制定,然后作为参数传递给序列模型来生成相应的模型。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Activation
# Dense相当于构建一个全连接层,32指的是全连接层上面的神经元的个数
layers = [Dense(32, input_shape=(784, )),
Activation('relu'),
Dense(10),
Activation('softmax')]
model = Sequential(layers)
# 打印模型的形状
model.summary()
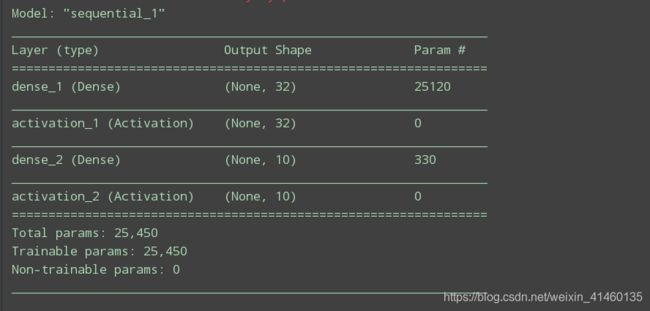
keras案例
"""
IMDB数据集是Keras内部集成的
IMDB数据集包含来自互联网的50000条严重两极分化的电影评论,
该数据被分为用于训练的25000条评论和用于测试的25000条评论,
训练集和测试集都包含50%的正面评价和50%的负面评价
该数据集已经经过预处理:评论(单词序列)已经被转换为整数序列,其中每个整数代表字典中的某个单词
"""
from keras.datasets import imdb
from keras.preprocessing import sequence
"""
首先对数据进行预处理
"""
max_features = 10000 # 作为特征的单词数量, 仅保留训练数据的前10000个最常出现的单词,低频单词将被舍弃,这样得到的向量数据不会太大,便于处理
maxlen = 500 # 在这么多单词之后截断文本(这些单词都属于前max_features个最常见的单词)
batch_size = 32
print('Loading data...')
(input_train, y_train), (input_test, y_test) = imdb.load_data(num_words=max_features) # 加载数据集
print(len(input_train), 'train sequences')
print(len(input_test), 'test sequences')
print(input_train[0])
"""
这一段代码可以将某条评论迅速解码为英文单词
"""
# word_index = imdb.get_word_index() # 拿到imdb的字典
# reverse_word_index = dict([(value, key) for (key, value) in word_index.items()]) # 把索引和单词对应起来
# decoded_review = ' '.join([reverse_word_index.get(i-3, '?') for i in input_train[0]]) # 0,1,2 是padding, start of sequence和unknown, 所以要跳过
# print(decoded_review)
"""
我们不能将整数序列直接输入神经网络,需要先将列表转换为张量,转换方式有两种
1. 填充列表
将长为nb_samples的序列转化为(nb_samples, nb_timesteps)2D numpy array。
如果提供了参数maxlen,那么nb_timesteps=maxlen,否则其值为最长序列的长度
如果设定长度为500, 那么超过500的部分舍弃,不到500则补0
2. 对列表进行one-hot编码
"""
print('Pad sequences (samples x time)')
input_train = sequence.pad_sequences(input_train, maxlen=maxlen)
input_test = sequence.pad_sequences(input_test, maxlen=maxlen)
print('input_train shape:', input_train.shape)
print('input_test shape:', input_test.shape)
"""
用Embedding层和SimpleRNN层来训练模型
嵌入层: 嵌入层将正整数(下标)转换为具有固定大小的向量,嵌入层只能出现在第一层
使用嵌入层的原因
为了把一个稀疏的矩阵变密集,换言之就是降维
最好将Embedding层理解为一个字典,将整数索引(表示特定单词)映射为密集向量。
它接受整数作为输入,并在内部字典中查找这些整数,然后返回相关联的向量。
Embedding层实际上是一种字典查找
Dense Layer:全名叫做densely connected layer(密集连接层),也叫fully connected layer(全连接层)
"""
from keras.layers import Embedding, Dense, SimpleRNN
from keras.models import Sequential
model = Sequential()
model.add(Embedding(max_features, 32))
model.add(SimpleRNN(32))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
history = model.fit(input_train, y_train,
epochs=10,
batch_size=128,
validation_split=0.2)
"""
显示训练和验证的损失和精度
history类对象包含两个属性,分别是epoch和history
当mertics=['acc']的时候,history就会包含val_loss, val_acc, loss, acc四个key值
"""
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc)+1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
循环神经网络RNN
什么是循环神经网络
循环神经网络,Recurrent Neural Network。神经网络是一种节点定向连接成环的人工神经网络。这种网络的内部状态可以展示动态时序行为。不同于前馈神经网络的是,RNN可以利用它内部的记忆来处理任意时序的输入序列,这让它可以更容易处理如不分段的手写识别、语音识别等。
RNN模型
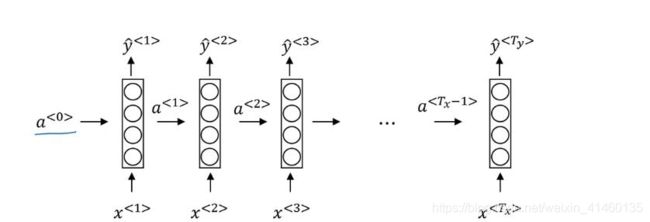
从上图可以看到,原来输入数据到标签是从左到右的顺序,现在变成了单个数据点对应输出的结构,且是自下而上的。
这里的一层只有一个数据中的一个标签对应关系。
同时,为了给序列之间的数据关系建模,层与层之间用一个变量a连接,
这样序列数据中的后一个数据的输入就会把前面的信息给编码进去,
进而解决原来模型上不同位置之间特征不共享的问题。
RNN的前向传播的算法
对于任意一个序列索引号t,我们隐藏状态$h^{(t)} 由 由 由x{(t)}$和$h({(t-1)} $得到:
h ( t ) = σ ( z ( t ) ) = σ ( U x ( t ) + W h ( t − 1 ) + b ) h^{(t)} = \sigma(z^{(t)}) = \sigma(Ux^{(t)} + Wh^{(t-1)} +b ) h(t)=σ(z(t))=σ(Ux(t)+Wh(t−1)+b)
其中σ为RNN的激活函数,一般为tanh, b为线性关系的偏倚。
序列索引号t时模型的输出$o^{(t)} $的表达式比较简单:
o ( t ) = V h ( t ) + c o^{(t)} = Vh^{(t)} +c o(t)=Vh(t)+c
在最终在序列索引号t时我们的预测输出为:
y ^ ( t ) = σ ( o ( t ) ) \hat{y}^{(t)} = \sigma(o^{(t)}) y^(t)=σ(o(t))
通常由于RNN是识别类的分类模型,所以上面这个激活函数一般是softmax。
通过损失函数 L ( t ) L^{(t)} L(t),比如对数似然损失函数,我们可以量化模型在当前位置的损失,即 y ^ ( t ) \hat{y}^{(t)} y^(t)和 y ( t ) y^{(t)} y(t)的差距。
RNN的反向传播的算法
前面用初始化的联结权重计算的输出层值和实际值肯定会有很大的偏差,我们需要对连接权重进行优化,此时就需要使用反向传播算法。
现在假设经过前向传播算法计算的某个输出值为ykyk,表示输出层的第kk个输出,而其实际的值为tktk(训练样本的标签值是已知的,不然怎么训练)。那么误差函数定义如下:
E=1/2∑k(yk−tk)^2
反向传播算法是通过梯度下降的方法对联结权重进行优化,所以需要计算误差函数对联结权重的偏导数。
反向传播算法的完整过程如下:
1.初始化联结权重wijwij.
2.对于输入的训练样本,求取每个节点输出和最终输出层的输出值.
3.对输出层求取δk=(yk−tk)∗H′(ak)δk=(yk−tk)∗H′(ak)
4.对于隐藏层求取δj=H′(ak)∗∑kδk∗wjkδj=H′(ak)∗∑kδk∗wjk
5.求取输出误差对于每个权重的梯度:∂En∂wji=δj∗zi∂En∂wji=δj∗zi
6.更新权重:wm+1=wm+α∂E∂w