DICOM医学图像处理:Dcmtk与fo-dicom保存文件的不同设计模式之“同步VS异步”+“单线程VS多线程”
一、背景:
最近一直在做DCM相关的编程工作,以前项目使用C++居多,所以使用DCMTK开源库,而目前团队使用C#居多,所以需要转向使用fo-dicom库,由于前一篇专栏文章DICOM医学图像处理:利用fo-dicom发送C-Find查询Worklist在调试过程中需要对DIMSE信息进行手动保存,偶然间发现了dcmtk开源库与fo-dicom开源库在保存dcm文件时使用的方式差异很大,因此决定研究一下,期望通过对比分析来看一下孰优孰劣。
二、dcmtk与fo-dicom保存文件函数的源码剖析:
1)dcmtk中DcmFileFormat的saveFile
saveFile中将文件写入状态划分为四种,即ERW_init 、ERW_ready、ERW_inWork、ERW_notInitialized四个状态。针对不同的状态进行不同的处理,因此可以认为dcmtk中的文件保存使用的是“状态机”方式,这有点类似于我以前用C++写过的一个自解析C++代码的程序,也是通过判别当前的环境来设定不同的状态,从而跳转到不同的操作中 。状态机(State Machine)这种方式在数字电路、编译原理中是很常见的(http://blog.chinaunix.net/uid-14880649-id-3011358.html),只不过dcmtk在文件写入过程中用到的是最直观的状态机而已(http://blog.csdn.net/xgbing/article/details/2784127)。
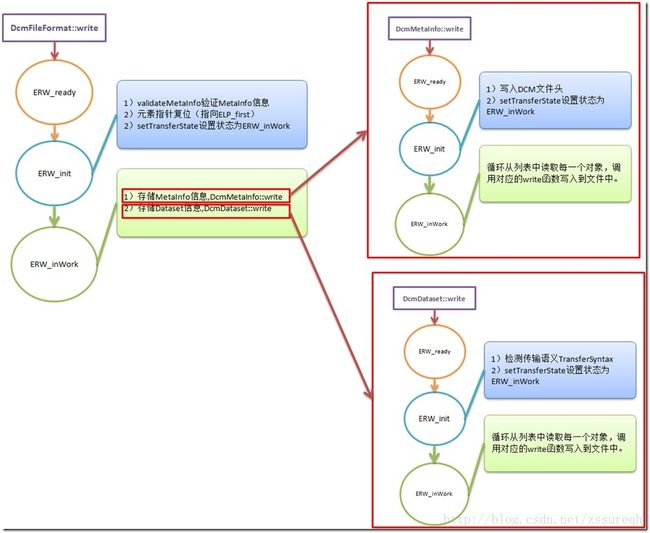
状态机可以简单的理解为“特定状态,针对输入字符,发生状态改变,没有额外的行为”,在DCMTK中实现的状态机可能并不是十分符合原始状态机的定义,因为各个状态的跳转并非是按照当前输入来决定的,而是根据DCM文件当前写入的程度(是否可以理解为事件?)来设定各个状态(即ERW_XXX四个状态),不同的阶段分别需要完成格式检查、写入准备、写入、写入完成。
状态机的编程写法有两种,竖写法——即针对每一种状态下发生的种种事件来进行分类处理;横写法——即针对每一种事件所能引起的状态改变来分类处理(详情参见http://blog.csdn.net/tomsen00/article/details/4932789),dcmtk的文件保存函数中使用的就是“竖写法”,因为各个状态之间有先后顺序,并非无序的跳转,必须先完成前缀(Preamble),然后才能写信息元(MetaInfo)、最后是真正的数据体(Dataset)。另外比较特殊的是:由于DCM文件本身的自包含性,即MetaInfo与Dataset两部分的互嵌套性(可参照我以前的博文http://blog.csdn.net/zssureqh/article/details/9275271),针对于DCM文件的不同部分又分别利用“状态机”来控制各部分的写入确保顺利进行。
2)fo-dicom中Dicom的Save

DicomFileWriter类中的同步函数Write内直接发起了异步调用请求,代码如下:
public void Write(IByteTarget target, DicomFileMetaInformation fileMetaInfo, DicomDataset dataset) {
EndWrite(BeginWrite(target, fileMetaInfo, dataset, null, null));
}
从上图中可以看出这是C#中较早期提出的一种异步编程模型——APM,针对于dcm文件的文件头、文件元信息、文件数据体三个不同的部分,通过异步回调的方式依次进行。这与dcmtk中采用的“状态机”实现的结果是一样的,对于各个状态的有序控制也是相同的,那么两者到底有何区别?fo-dicom既然是对dcmtk的重新封装,这是否就意味着异步回调方式优于状态机方式呢?
三、dcmtk与fo-dicom保存文件实际检测:
既然从原理上目前还并未找到很好的解释,或者说还没有完全理解两种方式的本质区别,那么我们先直接从两者的运行结果来实际体验一下两者的区别。
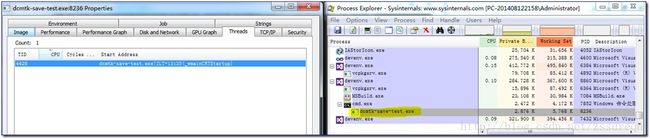
1)ProcessExplorer
简单的构造C++控制台程序和C#的控制台程序,分别利用dcmtk的saveFile和fo-dicom的Save,具体代码如下:
// dcmtk-save-test.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include "dcmtk/config/osconfig.h"
#include "dcmtk/dcmdata/dctk.h"
#include "dcmtk/dcmdata/dcpxitem.h"
#include "dcmtk/dcmjpeg/djdecode.h"
#include "dcmtk/dcmjpeg/djencode.h"
#include "dcmtk/dcmjpeg/djcodece.h"
#include "dcmtk/dcmjpeg/djrplol.h"
int _tmain(int argc, _TCHAR* argv[])
{
Sleep(15000);
DcmFileFormat mDcm;
mDcm.loadFile("d:\\DcmData\\test2.dcm");
mDcm.saveFile("d:\\DcmData\\dcmtk-test2.dcm");
return 0;
}using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Dicom;
using Dicom.Network;
using Dicom.Log;
using System.Threading;
namespace FindSCU1
{
class Program
{
static void Main(string[] args)
{
Thread.Sleep(1000);
DicomFile mDcm = DicomFile.Open(@"D:\DcmData\test2.dcm");
mDcm.Save(@"d:\DcmData\fo-test2.dcm");
Console.Read();
}
}
}利用ProcessExplorer观察两种库在保存文件时的实际性能。
第一是dcmtk开源库的saveFile函数的实际性能分析,
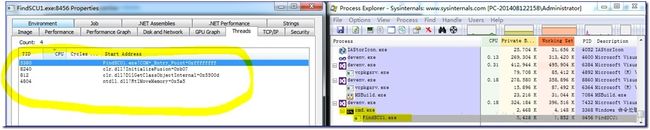
第二是fo-dicom的Save函数的性能分析,下图中给出了多线程的创建、挂起和终止。


由此可以看出fo-dicom的Save函数使用了多线程异步编程的模式来完成dcm文件的写入,从性能分析中可以直观的看出来多线程的fo-dicom版本在时间上有所提高,但是在其他的消耗方面有所增加(当然这里的分析不够科学,因为C#的基础运行环境要比C++复杂的多,所以不能简单的归结为fo-dicom采用了APM的结果)
2)vshost.exe插曲:
第一次利用ProcessExplorer查看两个模拟程序的性能时,可以正常的看到fo-dicom版本的多个线程(如上面的图所示),但是在第二次调试过程中一直未在ProcessExplorer工具中找到我自己的工程。

后来发现是由于启动的是vshost.exe调试容器,我们的程序是在该容器中运行的。通过右键打开工程属性,选择“调试”选项,将“启用Visual Studio承载进程”选项去掉,重新编译启动后,即可在ProcessExplorer中顺利看到我们的FINDSCU1.exe进程。

四、C#中的异步编程模式:
说实话刚转向C#领域不久,对于内部出现的众多委托和事件绑定,以及复杂的跳转流程还摸不着头绪,主要的是对内部的机制和所产生的性能影响没有一个更清晰的认识,单纯的学习使用委托、事件,以及异步编程的众多模式不难,但是更应该、更难的是要了解微软为什么要给C#增加这么多的新特性?如是,必然有他的理由,要从根本上了解引入该机制的原因才能更好的使用C#的众多新特性。下面简单的介绍一下C#的几种异步编程方式,由于目前还未真正搞清楚模式的本质区别和性能方面的差异,所以就不详细分析了,有兴趣的可以参考下一节中我提出的一些疑问,或许会有一些启发。
这里引用他人的一句话:所谓模式,其实是一种方法,就如同设计模式一样,是从工程实践中总结出来的解决相似或特定问题的一种惯用手段。常见的异步模式包括:
1)APM模式:BeginXXX/EndXXX,IAsyncResult
这就是我们上述提到的fo-dicom版的Save函数中使用的模式,该模式是C#中很早提出的异步模型,比较直接易懂。
2)EAP模式:基于事件的异步模式,常见的有Windows Form、MethodNameAsync、Event
该部分模式主要源于C#中提出的新的“事件”的概念,这不同于现实生活中的具体的发生在某一时间和某一空间的事件,其实是对Windows操作系统中消息的再封装(博文http://blog.csdn.net/fan158/article/details/6178392对C#中的事件有一个详细的分析)消息可以理解为操作系统记录运行过程中所发生的真实事件的抽象,可在各个应用程序之间进行传递,而C#的Event对消息的封装使得消息可以与其对应的响应函数绑定在一起,为开发者提供了更大的便利,但是其本质是没有改变的,即当某一事件发生时会触发与事件相绑定的处理函数(这也是计算机底层经常用到的一种实现机制,如中断向量表)。
EAP模式是针对于Windows From编程而提出的,是对APM模式的改进,使得编程人员操作更方便,且内部也是采用的APM模式来实现的。
3)TAP模式:基于任务的异步模式,常见的有MethodNameAsync、Task、Task
4)C#5.0中的async和await引入的异步编程模式
对于后两种异步模式接触不多,但是本质的原理是相同的,都需要利用线程池(也可以说多线程)和事件(消息)来配合完成异步操作,后续会进一步的学习。
最后谈一下自己对异步编程的理解,为什么会出现异步编程?为什么我们要异步?原因只有一个——“效率”,高效利用计算机的各项资源。打个比方,你去饭馆吃饭,点菜的肯定跟做菜的不是同一个人(当然也有这种极端情况哈),为什么要将这两种工作分开呢?原因就是完成两个事情所需要的时间和精力完全不同,点菜简单快速,要求就是准确理解客户要求,而做菜复杂缓慢,要求就是要做出好的口味。如果让做菜的人也负责点菜,只有两种方式,一种就是客户需要等菜做完才能点菜,而这就浪费了客户很长的时间,影响了客户的体验;一种就是做菜的过程中出来听客户点菜,而这就打断了炒菜的节奏,自然菜就没法吃了。无论哪种情况发生,长此以往估计饭馆也离倒闭不远了。这个情景在计算机内部也经常发生,用户的各种操作、各种需求也存在着差异,有的需要进行长时间的运算(垃圾回收、碎片整理),有的则需要快速的响应(例如UI界面),那么在计算机领域,大牛们是怎么解决的呢?像Intel大牛们就致力于提升计算机本身的性能,期望提供无穷的资源来满足用户的各种需求,这就好比饭馆请更多的厨师,当厨师数量永远大于客户数量的时候问题自然就解决啦(当然这种情况真实世界是不会存在的)——基于这种情况,就衍生出了真正的并行编程、并行计算;而像微软的大牛们则致力于发展新的使用模式,期望更高效更合理的利用有限的资源,这就好比先让厨师抽一段时间、一段很短的时间集中接受客人的点菜,然后再拿出更长的时间来做菜,只要时间分配合理,也会使大多数客户满意,再进步一点的话就是花很少的成本请一名专门负责点菜的服务员,负责给客户点菜,如是厨师就可以安心在厨房炒菜啦——针对这种情况,就出现了我们提到的众多异步编程模式,完成端口就很像我所说的饭馆的情况:创建完成端口后,系统会提前开辟部分线程,这与CPU的核心数有关,基本规律是:线程数=2*CPU核心数+1(这就好比请了多名厨师),同时给完成端口分配一个消息队列(这就好比点菜的笔记本);随后系统用一个轻量级的线程快速的接受用户的响应并负责添加到消息队列中(这就好比专门请一名服务员点菜),当消息队列非空时,线程池的线程就会取出其中的消息进行相应的处理操作(这就好比多名厨师按照时间先后顺序来处理菜单)。这样就可以高效的满足用户的大多需求,当然上述两种情况只是真实世界中各种情况的两个极端例子而已,因此在真实的世界中为了提高效率会有更多的方式,例如厨师可以按照菜的种类来分别炒,服务员也可以按照座位的容量来合理安排点菜的顺序,等等……
然而当厨师数量、服务员数量急剧扩大的时候,彼此之间工作的配合就显得越来越重要,这就好比异步编程中的同步概念,需要协调各个异步运行的线程之间的协作,尤其是访问共享资源时,或者当一个事情的核心步骤需要有序进行的时候,例如fo-dicom的Save函数对dcm的Preamble、MetaInfo和Dataset的保存。为了提高开发者的效率,使得现有的有效的处理事务的模式可以方便快捷的使用,就有了C#中的APM、EAP、Task和async+await等种种异步编程模式。
五、思考
从C++转到C#不久,一直对C++情有独钟,要想C++中的完成端口、是否与C#中的线程池有异曲同工之妙,C++的文件流、I/O流与C#的文件流、I/O流有何大的区别,后续要深入分析一下。
1)线程池与完成端口
在《CLR via C# 第三版》中指出了,在CLR内部就是通过使用完成端口技术来实现的“线程池”,以前我在进行DCM文件异步传输时专门分析过完成端口的优良性能(参见博文:完成端口学习笔记(一):完成端口+控制台 实现文件拷贝、完成端口学习笔记(二):完成端口实现机制的仿真)

完成端口是Windows编程中极力提倡的一种编程方式,通过使用线程池和消息队列来配合,可以高效的实现计算密集型和IO密集型操作。在我的前两篇博文中对“完成端口”有一个详细的剖析,也可参照上一节中列举的例子来简单的了解一下。
2)异步编程与状态机
直接给出几篇关于异步编程和状态机的精彩博文:
http://msdn.microsoft.com/zh-cn/magazine/hh456403.aspx
http://blog.chinaunix.net/uid-14880649-id-3011358.html
http://blog.csdn.net/tomsen00/article/details/4932789
C#5.0引入的async和await新版异步编程模式,其在编译器内部就是将异步编程用状态机来模拟实现。正如上所述,所谓的异步编程模式仅仅就是一种经验的总结,一种惯用手法,更夸张点来说C#从APM到如今的async和await的改进其实都是对经验的总结和以前模式的改进,当然这就需要操作系统和C#语言底层的内嵌支持才能实现,才能给开发者的工作带来方便。
在此简单的总结一下目前自己的体会,dcmtk单线程的saveFile函数利用状态机来完成使得程序流程清晰、简洁,对于后续代码的维护也提供了便利;fo-dicom的APM异步编程模式,通过启动线程池的方式在实现效率上有了一定的提升,另外也将dcm文件保存划分成了独立而又相关的几个部分,能够分别的检测和捕捉异常,对于程序的安全运行也有一定的帮助。可以说fo-dicom是使用APM异步编程模型来模拟了dcm文件的同步写入,这其中又利用了C#的FileStream流的异步特性而已。关于FileStream类在《CLR via c#》中27.8.8小节中有详细的介绍,大家可以体会一下。
六、参考资料:
上面的分析并未真正找到我想要的答案,因此后续还要继续阅读相关的书籍和资料,争取尽快找到想要的结果,写这篇博文的时候主要参考的书籍如下,推荐看先看英文版,随后再看中文版,那样理解可能会更透彻,因为翻译的毕竟不是第一手资料嘛。
《CLR via C#》(中文第三版)
《C# 5.0 in a Nutshell》(英文版)
后续专栏博文介绍:
1)AETitle在C-FIND和C-MOVE请求中的设置问题
2)Dicom中的MPPS服务介绍
3)C#的异步编程模式在fo-dicom中的应用
时间:2014-09-22