pyhanlp文本分类与情感分析
语料库
本文语料库特指文本分类语料库,对应IDataSet接口。而文本分类语料库包含两个概念:文档和类目。一个文档只属于一个类目,一个类目可能含有多个文档。比如搜狗文本分类语料库迷你版.zip,下载前请先阅读搜狗实验室数据使用许可协议。
用Map描述
这种关系可以用Java的Map
用文件夹描述
这种树形结构也很适合用文件夹描述,即:
/**
* 加载数据集
*
* @param folderPath 分类语料的根目录.目录必须满足如下结构:
* 根目录
* ├── 分类A
* │ └── 1.txt
* │ └── 2.txt
* │ └── 3.txt
* ├── 分类B
* │ └── 1.txt
* │ └── ...
* └── ...
* 文件不一定需要用数字命名,也不需要以txt作为后缀名,但一定需要是文本文件.
* @param charsetName 文件编码
* @return
* @throws IllegalArgumentException
* @throws IOException
*/
IDataSet load(String folderPath, String charsetName) throws IllegalArgumentException, IOException;
例如:
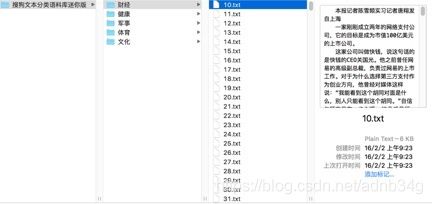
每个分类里面都是一些文本文档。任何满足此格式的语料库都可以直接加载。
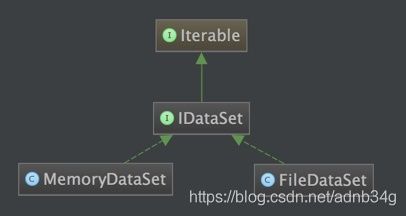
数据集实现
考虑到大规模训练的时候,文本数量达到千万级,无法全部加载到内存中,所以本系统实现了基于文件系统的FileDataSet。同时,在服务器资源许可的情况下,可以使用基于内存的MemoryDataSet,提高加载速度。两者的继承关系如下:
训练
训练指的是,利用给定训练集寻找一个能描述这种语言现象的模型的过程。开发者只需调用train接口即可,但在实现中,有许多细节。
分词
目前,本系统中的分词器接口一共有两种实现:
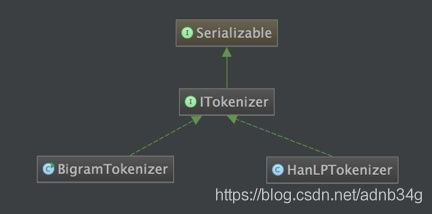
但文本分类是否一定需要分词?答案是否定的。 我们可以顺序选取文中相邻的两个字,作为一个“词”(术语叫bigram)。这两个字在数量很多的时候可以反映文章的主题(参考清华大学2016年的一篇论文《Zhipeng Guo, Yu Zhao, Yabin Zheng, Xiance Si, Zhiyuan Liu, Maosong Sun. THUCTC: An Efficient Chinese Text Classifier. 2016》)。这在代码中对应BigramTokenizer. 当然,也可以采用传统的分词器,如HanLPTokenizer。 另外,用户也可以通过实现ITokenizer来实现自己的分词器,并通过IDataSet#setTokenizer来使其生效。
特征提取
特征提取指的是从所有词中,选取最有助于分类决策的词语。理想状态下所有词语都有助于分类决策,但现实情况是,如果将所有词语都纳入计算,则训练速度将非常慢,内存开销非常大且最终模型的体积非常大。
本系统采取的是卡方检测,通过卡方检测去掉卡方值低于一个阈值的特征,并且限定最终特征数不超过100万。
调参
对于贝叶斯模型,没有超参数需要调节。
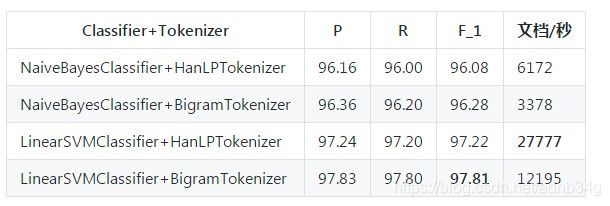
训练
本系统实现的训练算法是朴素贝叶斯法,无需用户关心内部细节。另有一个子项目实现了支持向量机文本分类器,可供参考。由于依赖了第三方库,所以没有集成在本项目中。相关性能指标如下表所示:
模型
训练之后,我们就得到了一个模型,可以通过IClassifier#getModel获取到模型的引用。该接口返回一个AbstractModel对象,该对象实现了Serializable接口,可以序列化到任何地方以供部署。 反序列化后的模型可以通过如下方式加载并构造分类器:
NaiveBayesModel model = (NaiveBayesModel) IOUtil.readObjectFrom(MODEL_PATH);
NaiveBayesClassifier naiveBayesClassifier = new NaiveBayesClassifier(model);
分类
通过加载模型,我们可以得到一个分类器,利用该分类器,我们就可以进行文本分类了。
IClassifier classifier = new NaiveBayesClassifier(model);
目前分类器接口中与文本分类有关的接口有如下三种:
/**
* 预测分类
*
* @param text 文本
* @return 所有分类对应的分值(或概率, 需要enableProbability)
* @throws IllegalArgumentException 参数错误
* @throws IllegalStateException 未训练模型
*/
Map
/**
* 预测分类
* @param document
* @return
*/
Map
/**
* 预测分类
* @param document
* @return
* @throws IllegalArgumentException
* @throws IllegalStateException
*/
double[] categorize(Document document) throws IllegalArgumentException, IllegalStateException;
/**
* 预测最可能的分类
* @param document
* @return
* @throws IllegalArgumentException
* @throws IllegalStateException
*/
int label(Document document) throws IllegalArgumentException, IllegalStateException;
/**
* 预测最可能的分类
* @param text 文本
* @return 最可能的分类
* @throws IllegalArgumentException
* @throws IllegalStateException
*/
String classify(String text) throws IllegalArgumentException, IllegalStateException;
/**
* 预测最可能的分类
* @param document 一个结构化的文档(注意!这是一个底层数据结构,请谨慎操作)
* @return 最可能的分类
* @throws IllegalArgumentException
* @throws IllegalStateException
*/
String classify(Document document) throws IllegalArgumentException, IllegalStateException;
classify方法直接返回最可能的类别的String形式,而predict方法返回所有类别的得分(是一个Map形式,键是类目,值是分数或概率),categorize方法返回所有类目的得分(是一个double数组,分类得分按照分类名称的字典序排列),label方法返回最可能类目的字典序。
线程安全性
类似于HanLP的设计,以效率至上,本系统内部实现没有使用任何线程锁,但任何预测接口都是线程安全的(被设计为不储存中间结果,将所有中间结果放入参数栈中)。
情感分析
可以利用文本分类在情感极性语料上训练的模型做浅层情感分析。目前公开的情感分析语料库有:中文情感挖掘语料-ChnSentiCorp,语料发布者为谭松波。
接口与文本分类完全一致,请参考com.hankcs.demo.DemoSentimentAnalysis。
性能指标
一般来讲,受到语料库质量的约束(部分语料库的分类标注模糊或有重叠),我们评测一个分类器时,必须严谨地注明在哪个语料库以何种比例分割数据集下得到这样的测试结果。
版本库中有一个在搜狗语料库上的测试com.hankcs.demo.DemoTextClassificationFMeasure,含有完整的参数,请自行运行评估。