【大模型LoRa微调】Qwen2.5 Coder 指令微调【代码已开源】
本文需要用到的代码已经放在GitHub的仓库啦,别忘了给仓库点个小心心~~~
https://github.com/LFF8888/FF-Studio-Resources
第001个文件哦~
一、引言:大语言模型与指令微调
1.1 大语言模型发展简史
随着深度学习的飞速发展,特别是Transformer架构在自然语言处理(NLP)领域的成功,大语言模型(LLM, Large Language Model)成为近年来最受关注的热点方向之一。从最初的基于LSTM的语言模型,到基于Attention机制的Transformer,再到不断在规模和数据上进行扩展的GPT系列、BERT系列、T5系列以及最新的Qwen、Llama等,这些模型在各种任务(如语言理解、生成、翻译、代码生成等)上都展示了强大的能力。
然而,面对这些规模庞大、参数动辄上亿乃至上百亿的模型,若要让它们在特定任务(如客服对话、特定领域问答、代码生成等)上发挥更大价值,就需要进行微调(Fine-tuning)。传统微调往往需要在大模型的所有参数上做反向传播和更新,这对于硬件资源和数据存储都有相当高的要求。为解决这一问题,一些参数高效微调(PEFT, Parameter-Efficient Fine-Tuning)的技术应运而生,例如 LoRA(Low-Rank Adaptation)、Prefix Tuning、Adapter等。这些方法大大降低了微调所需的训练成本,使得在有限的算力资源下进行指令微调成为可能。
1.2 指令微调(Instruction Tuning)
指令微调(Instruction Tuning)的核心思想是:通过给模型添加某种“指令”或“提示”(prompt),让模型学会根据特定的指令来回答问题或完成任务。与普通的微调相比,指令微调更强调**模型对指令(Prompt)**的理解,以及在不同的情景下如何生成符合指令要求的回答。如今,大量研究都表明,进行指令微调后的模型更适合应用于真实场景,对话风格更自然,也更倾向于服从或理解用户的指令。
1.3 Qwen2.5 Coder 32B 指令微调简介
Qwen2.5 Coder 是一款基于阿里云开源的 Qwen (千万亿级别Token训练规模) 系列模型所衍生的代码生成/理解模型。这里的“32B”代表它拥有 320亿左右的可训练参数量级。由于Qwen2.5 Coder具备很好的代码理解和生成能力,非常适合在例如编程问题解答、代码生成、代码修正、与代码相关的上下文理解等场景下应用。
本篇教程的目标,是利用LoRA微调技术,对Qwen2.5 Coder 32B模型进行指令微调。通过这样的微调,我们可以获得一个在限定领域(如某些编程任务)或有特定风格指令(如以对话形式要求回答编程问题)的模型,而且微调所需要的成本也相对较低。
二、环境准备
在本文示例中,可使用Google Colab环境(笔者使用的是 Tesla L4 GPU 24G显存 ),或者其他有GPU的环境也可以。需要准备的步骤包括:
- 登录/连接到具有GPU支持的Notebook环境。
- 确保安装了
pip等常用工具。 - 运行时类型选择GPU(在Google Colab中可以选择“运行时”->“更改运行时类型”->“硬件加速器:GPU”)。
- 安装所需依赖,例如
unsloth、transformers、datasets、peft、trl等。
三、代码结构与主要流程介绍
以下示例代码已经以notebook形式给出,主要包含以下几个部分:
- 安装依赖:安装
unsloth等库,它包含了简化训练和推理的工具函数。 - 模型初始化:加载Qwen2.5 Coder 32B模型(支持4位量化,以降低显存占用)。
- LoRA适配器配置:对模型添加LoRA层,指定需要训练的权重、秩、缩放因子等。
- 数据准备:通过
datasets库加载数据集,并转换为Qwen2.5特定的聊天格式(对话模板)。 - 数据格式转换:如有需要,将ShareGPT格式的对话转换成Hugging Face通用形式。
- 模型训练:使用HuggingFace的
SFTTrainer进行微调,可指定训练批次大小、学习率、步数等。 - 推理测试:利用微调好的模型进行推理,尝试问答、代码生成,或者对话式测试。
- 模型保存:保存LoRA权重或将微调后的完整模型合并并输出,以便后续部署或分享。
接下来,我们会对上述各步骤进行更详细的讲解。
四、理论基础:LoRA与指令微调背后的原理
4.1 LoRA原理简述
LoRA(Low-Rank Adaptation)是参数高效微调的一种方法,核心思想是:假设大模型中的某些矩阵(例如Attention中的Q、K、V等投影矩阵)在需要进行更新时,可以分解成低秩矩阵的形式,并只在这部分低秩矩阵上进行训练更新。这样一来,可以显著减少需要训练的参数量。例如:
- 原始全量微调:可能需要更新数十亿甚至上百亿参数。
- LoRA微调:只需要更新百余万甚至更少的参数。
由于更新的参数量大幅减少,我们也能降低对计算资源的需求,使得在消费级GPU上对大模型进行微调成为可能。
4.2 指令微调与对话格式
对于Qwen2.5 Coder这种对话风格或代码生成风格的模型,通常使用“系统提示 + 用户输入 + 模型回答”这样一个多轮对话的格式。通过指令微调,让模型更擅长理解在对话上下文中所传递的意图或问题,并给出合理的回答。
在“Qwen-2.5”的对话格式示例中,我们会使用类似的标记:
<|im_start|>system
You are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>
<|im_start|>user
What is 2+2?<|im_end|>
<|im_start|>assistant
It's 4.<|im_end|>
在实际训练时,我们会将所有对话数据按照这种格式进行拼接,从而让模型学会“当role=system时如何处理,当role=user时如何处理,以及当role=assistant时如何回答”。
4.3 数据掩码(Mask)与只训练回答部分
在对话式微调中,通常希望模型只对“assistant”部分的文本负责,用户或系统的提示部分不计入损失梯度。这可以通过在序列标签中设置-100来对非回答部分进行掩码。这样,就能在训练中只让模型“关注”自己的回答,减少不必要的干扰,并且能够更好地学习回答风格。
五、详细代码与实操流程
下面的代码片段已经在Notebook中给出。为方便阅读,这里会对关键点进行分段说明,并插入部分代码片段做演示。读者可以在Google Colab或者其他Jupyter Notebook环境中拷贝运行。
5.1 安装依赖
!pip install unsloth
unsloth 是一个整合了参数微调、模型量化、对话格式处理等多功能的Python库,内部封装了一些快捷API,可显著简化模型微调和推理流程。
安装完成后,可使用 import unsloth 测试是否成功。
5.2 模型初始化
在这一步,我们指定要加载的模型名称、最大序列长度、数据类型等。考虑到Colab等环境普遍显存有限,我们把 load_in_4bit 设置为 True 来使用4位量化形式。
from unsloth import FastLanguageModel
import torch
# 基础配置参数
max_seq_length = 2048 # 最大序列长度
dtype = None # 自动检测数据类型
load_in_4bit = True # 使用4位量化以减少内存使用
# Qwen系列模型列表(这里选用Qwen2.5-Coder-32B-Instruct)
qwen_models = [
"unsloth/Qwen2.5-Coder-32B-Instruct",
"unsloth/Qwen2.5-Coder-7B",
"unsloth/Qwen2.5-14B-Instruct",
"unsloth/Qwen2.5-7B",
"unsloth/Qwen2.5-72B-Instruct",
]
# 加载预训练模型和分词器
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Qwen2.5-Coder-32B-Instruct",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
完成后,你就获得了一个可以进行前向推理的Qwen2.5 Coder 32B模型以及对应的分词器。此时如果你运行一下nvidia-smi,会看到显存占用比不使用4bit量化时要低不少。
5.3 LoRA适配器配置
要进行参数高效微调,我们需要给模型“注入”LoRA层。这里指定LoRA的秩 r=16,目标模块包括Attention部分的Q、K、V、O,以及一些MLP层;同时指定use_gradient_checkpointing选项可进一步节省显存。
model = FastLanguageModel.get_peft_model(
model,
r = 16, # LoRA秩
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
完成后,你的模型就携带了可训练的LoRA权重。在微调过程中,主要会更新LoRA新增的权重,不会对原始大模型权重做修改,从而极大地减少需要反向传播和存储的参数量。
5.4 数据准备与对话格式化
-
加载数据集:示例中使用了Maxime Labonne的FineTome-100k。读者也可以换成自己准备的对话数据或者ShareGPT格式数据。
-
Qwen对话模板:使用
unsloth.chat_templates.get_chat_template()来设定分词器的对话模板为“qwen-2.5”,从而在数据预处理中可直接调用tokenizer.apply_chat_template()。 -
格式转换:如果你的数据是ShareGPT格式,可以先用
unsloth.chat_templates.standardize_sharegpt标准化为Hugging Face常规格式后,再用formatting_prompts_func配置对话格式。
示例代码:
from unsloth.chat_templates import get_chat_template
# 配置分词器使用qwen-2.5对话模板
tokenizer = get_chat_template(
tokenizer,
chat_template = "qwen-2.5",
)
def formatting_prompts_func(examples):
"""格式化对话数据的函数"""
convos = examples["conversations"]
# 将对话结构映射成qwen-2.5形式的文本
texts = [tokenizer.apply_chat_template(convo, tokenize=False, add_generation_prompt=False) for convo in convos]
return { "text" : texts, }
# 加载数据集
from datasets import load_dataset
dataset = load_dataset("mlabonne/FineTome-100k", split="train")
随后进行标准化与格式化:
from unsloth.chat_templates import standardize_sharegpt
dataset = standardize_sharegpt(dataset)
dataset = dataset.map(formatting_prompts_func, batched=True,)
5.5 仅对助手回复进行训练
在对话式数据中,我们往往只想优化模型回答时的部分。可以借助 unsloth.chat_templates.train_on_responses_only() 来自动创建标签掩码,让用户输入部分不参与损失计算:
from unsloth.chat_templates import train_on_responses_only
trainer = train_on_responses_only(
trainer,
instruction_part = "<|im_start|>user\n", # 用户输入区分符
response_part = "<|im_start|>assistant\n", # 模型回答区分符
)
在训练前可以查看 trainer.train_dataset[5]["input_ids"] 以及对应的 trainer.train_dataset[5]["labels"],发现用户部分在labels中会被替换为-100,从而不计算损失。
5.6 配置并开始训练
这里用SFTTrainer来进行微调,核心参数包括:
per_device_train_batch_size:每张卡上的batch大小gradient_accumulation_steps:梯度累积步数warmup_steps:学习率预热max_steps:总训练步数learning_rate:初始学习率fp16/bf16:是否使用16位或bf16混合精度optim="paged_adamw_8bit":8bit Adam优化器,可进一步节省显存
示例代码如下:
from trl import SFTTrainer
from transformers import TrainingArguments, DataCollatorForSeq2Seq
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer),
dataset_num_proc=4,
packing=False,
args=TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
warmup_steps=5,
max_steps=100,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=1,
optim="paged_adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
report_to="none",
),
)
然后开始训练:
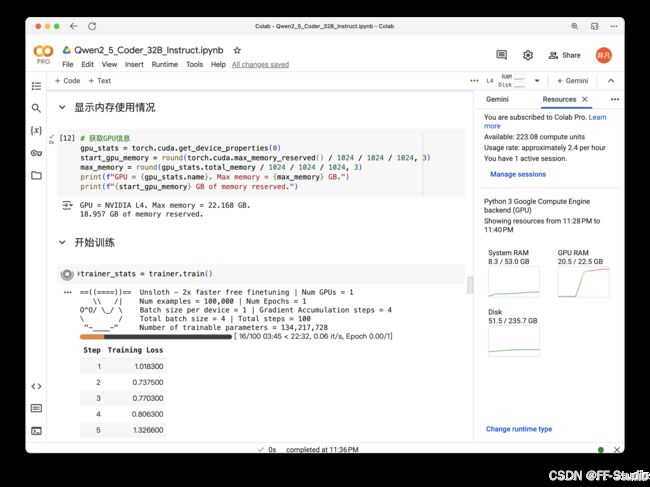
trainer_stats = trainer.train()
训练过程中可以随时使用nvidia-smi监控GPU显存,以及查看日志中打印的loss值。若显存不足,可再次减小batch size或其他超参数。
5.7 查看训练结果及显存
训练完成后,可查看一些简单的训练统计信息,以及显存消耗情况:
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
...
print(f"Peak reserved memory = {used_memory} GB.")
若你看到显存大概在几GB左右,说明LoRA微调确实有效地减少了显存使用。
六、模型推理:测试微调效果
在完成LoRA微调后,可以直接调用微调好的模型进行推理,或做进一步测试。
6.1 基本推理
利用FastLanguageModel.for_inference(model)来开启推理模式,并在生成时可以配置temperature、min_p等参数。示例代码:
from unsloth.chat_templates import get_chat_template
# 配置推理用的分词器
tokenizer = get_chat_template(
tokenizer,
chat_template = "qwen-2.5",
)
FastLanguageModel.for_inference(model)
# 构造测试输入(对话形式)
messages = [
{"role": "user", "content": """Here is a programming problem for testing:
**Matrix Chain Multiplication Optimization**
### Problem:
Given a chain of matrices `A1, A2, ..., An`...
"""}
]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
).to("cuda")
outputs = model.generate(
input_ids = inputs,
max_new_tokens = 64,
use_cache = True,
temperature = 1.5,
min_p = 0.1
)
print(tokenizer.batch_decode(outputs))
如果一切正常,你会看到一段模型生成的文本,用来解答这个矩阵连乘优化问题。
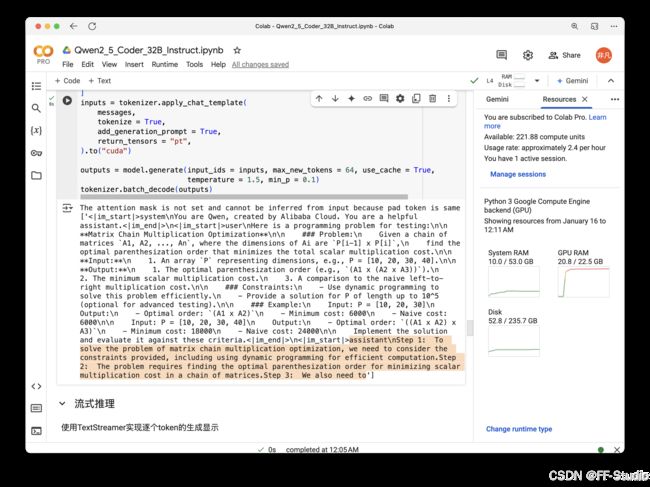
6.2 流式推理
为了更好地观察模型的生成过程,可以使用TextStreamer实现token-by-token的流式输出:
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt=True)
_ = model.generate(
input_ids=inputs,
streamer=text_streamer,
max_new_tokens=128,
use_cache=True,
temperature=1.5,
min_p=0.1
)
你会在控制台或Notebook下看到模型一字一句地生成文本的过程,非常直观。
七、模型保存与部署
7.1 保存LoRA适配器
如果只想保存LoRA微调后的权重,可以执行:
model.save_pretrained("lora_model")
tokenizer.save_pretrained("lora_model")
这样就会在本地生成一个lora_model文件夹,里面包含LoRA权重和分词器文件。需要注意的是:这并不包含原始基础模型,后续加载时需要合并到相同或兼容的基础模型上。
7.2 合并并保存完整模型
若希望使用合并后的完整模型(例如,在推理时只加载一个权重文件),可以使用save_pretrained_merged或其他类似的方法,将LoRA权重与原模型权重进行合并,然后得到一个新的完整模型:
if False:
model.save_pretrained_merged("model", tokenizer, save_method="merged_16bit")
上面示例中使用save_method="merged_16bit"即保存成16位浮点格式。若想节省空间,也可保存成4位量化格式。然后,就可在加载时直接使用from_pretrained一次性加载。
7.3 上传到Hugging Face Hub
如果你希望与他人分享模型,可以将本地的LoRA权重或合并后的完整模型上传至HuggingFace Hub。
示例(假设你已经在 HuggingFace 上创建了一个仓库 your_name/lora_model):
model.push_to_hub("your_name/lora_model", token="YOUR_HF_TOKEN")
tokenizer.push_to_hub("your_name/lora_model", token="YOUR_HF_TOKEN")
这样就能在任何地方直接使用类似 model = AutoPeftModelForCausalLM.from_pretrained("your_name/lora_model") 的方式加载了。
八、常见问题与解答
-
Q:显存不够怎么办?
A:可以尝试以下方案:- 减小
r、lora_alpha等LoRA配置,减少可训练的参数量。 - 缩小
max_seq_length,减少每次处理的序列长度。 - 减少batch size或增加
gradient_accumulation_steps。 - 使用更低精度的量化(如4位或8位)来加载基础模型。
- 减小
-
Q:为什么要只对assistant部分计算loss?
A:在对话任务中,系统提示和用户输入并不是由模型来预测的部分,只计算模型回答部分的loss才能让模型专注于回答输出,减少不必要的干扰,从而收敛更快且质量更好。 -
Q:我有自己的对话数据,怎么转换格式?
A:如果是自定义的对话数据集,可以先对每一轮对话做角色标注(system/user/assistant),并尽量整理成类似ShareGPT或Hugging Face对话格式,然后再用standardize_sharegpt()或自定义的函数进行转换。最后用apply_chat_template()生成最终的可训练文本。 -
Q:LoRA微调后模型推理速度会变慢吗?
A:理论上有一点开销,因为LoRA层在推理时也要与原模型层合并计算。但由于LoRA规模远小于原模型,通常这部分开销较小。同时,如果在推理前进行了权重合并(merged weights),那么推理速度和原模型基本相同。 -
Q:如何验证模型是否真的学到了指令风格?
A:可以准备一批简单的对话测试集,比如让用户在对话中提出一些不在训练集里的问题,或要求模型以特定口吻回答。若模型能正确理解指令风格,并给出合理答复,说明指令微调有效。
九、展望
在实际应用中,Qwen2.5 Coder 32B的微调成果可应用于以下场景:
- 交互式编程问答:在IDE或在线平台中为开发者提供编程调试建议、错误解释等。
- 代码生成与完善:根据自然语言描述,生成可运行的示例代码,并根据反馈修正错误或优化性能。
- 教育场景:在编程教学中,为学生提供自动答疑与演示示例,提升教学效率。
- 文档与注释自动化:对已有代码自动生成详细的注释或文档说明,减少文档编写工作量。
随着更多数据涌现以及LoRA和其他参数高效微调技术的不断演进,大模型在各自领域的落地能力将会越来越强。指令微调已经成为让模型完成特定任务、体现特定个性与风格的一项关键手段。
十、后续可探索的方向
- 多语言或跨模态微调:若你想让模型支持多语言对话或处理多模态信息(如图像、音频),可以在LoRA层上进一步扩展,并准备对应领域的数据集。
- RLHF(Human Feedback):在指令微调的基础上,可以接入人类反馈强化学习(RLHF),从而在多轮对话和复杂场景中获得更人性化、对齐度更高的回答。
- 更大规模的训练数据:如果能获取到更多带有指令标签的高质量对话数据,指令微调的效果可能更显著。
- 量化和加速:继续研究如何在4位甚至更低精度上保持模型可用的同时,进一步降低部署成本,实现超大模型的本地实时推理。
十一、参考与致谢
- unsloth GitHub Repo:提供了许多封装好的LoRA训练、模型量化、对话模版处理等API。
- Hugging Face Transformers:大语言模型的重要基础库,在社区中极具影响力。
- TRL (Transformer Reinforcement Learning):一个用于对GPT等语言模型进行强化学习调优的库,也提供SFTTrainer等模型微调功能。
- Maxime Labonne’s FineTome-100k 数据集:用于对话形式的训练数据集示例。
若各位读者在阅读此篇教程或者动手实践的过程中遇到任何疑问,可在评论区留言。希望本篇博客文章能够帮助你快速上手Qwen2.5 Coder 32B的指令微调,并在实际应用中灵活运用这种高效微调技术,打造出更智能、更符合需求的大模型应用!
祝各位在大模型与NLP道路上不断精进、学有所成!