深度学习与PyTorch笔记22
过拟合&欠拟合
数据模态
在讲解过拟合和欠拟合之前,先说一下数据的真实的模态,也叫数据的真实分布或者 P r ( x ) P_r(x) Pr(x)。
线性模型:
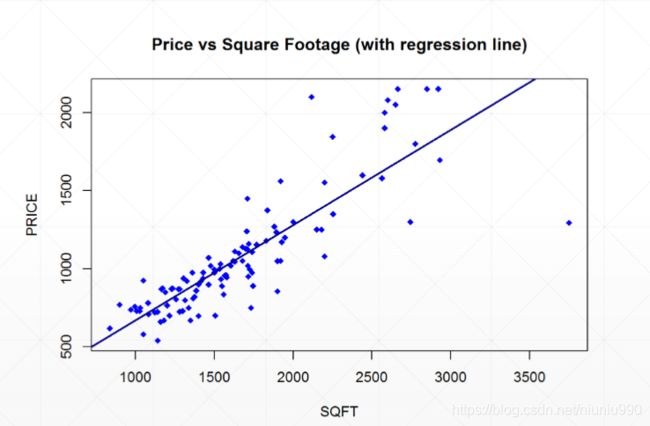
非线性模型:

已经提前知道数据的分布但是不知道具体的参数,比如房价与面积的倍数。我们不但对 P r ( x ) P_r(x) Pr(x)的类型不知,观察时还有误差。
y = w ∗ x + b + ϵ y=w*x+b+\epsilon y=w∗x+b+ϵ , ϵ ∼ N ( 0.01 , 1 ) \epsilon \sim N(0.01,1) ϵ∼N(0.01,1)
l o s s = ( W X + b − y ) 2 loss=(WX+b-y)^2 loss=(WX+b−y)2
衡量模型的学习能力
用一个模型去学习数据的分布时会优先选择不同类型的模型,比如使用不同次方的多项式,如下图所示:
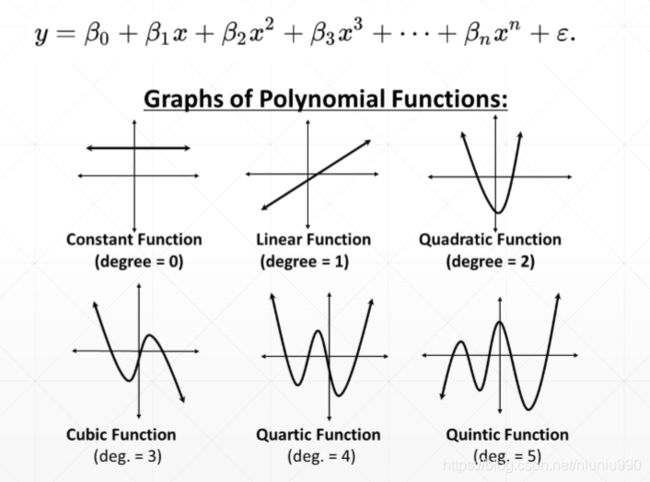
怎么衡量不同类型的模型的学习能力(model capacity)。
y = β 0 + β 1 x + β 2 x 2 + β 3 x 3 + ⋯ + β n x n + ϵ y=\beta_0+\beta_{1}x+\beta_{2}x^{2}+\beta_{3}x^{3}+\cdots+\beta_{n}x^{n}+\epsilon y=β0+β1x+β2x2+β3x3+⋯+βnxn+ϵ
常数时学习能力最弱,幂次越大能表达的情况越复杂。深度学习层数越深,学习能力越强。
Underfitting&Overfitting
- Case1:Estimated
- Case2:Ground-truth
现实生活中更多出现的是overfitting。我们需要解决两个问题,怎么检测overfitting(how to detect),怎么减少overfitting(how to reduce)。
how to detect
Train-Val-Test划分
print('train:',len(train_db),'test:',len(test_db))
train_db,val_db=torch.utils.data.random_split(train_db,[50000,10000])
print('db1:',len(train_db),'db2:',len(val_db))
train_loader=torch.utils.data.DataLoader(
train_db,
batch_size=batch_size,shuffle=True)
val_loader=torch.utils.data.DataLoader(
val_db,
batch_size=batch_size,shuffle=True)
将一个60k的样本划分为一个50k和一个10k。用Val来反馈。
K-fold cross-validation
先将Train与Val合并,再重新分出validation,好处是,长时间下去,每一个数据集都有可能参与进去,每次都做切换。
how to reduce overfitting
- More date
- Constraint model complexity
- shallow
- regularization
- Dropout
- Data argumentation
- Early Stopping
这里讲一下regularization
迫使参数的范数接近于0,减少模型复杂度。
对于一个二分类问题,他的loss为
J ( θ ) = − 1 m ∑ i = 1 m [ y i l n y ^ i + ( 1 − y i l n ( 1 − y ^ i ) ] J(\theta)=-\frac{1}{m}\sum_{i=1}^{m}[y_{i}ln \widehat{y}_{i}+(1-y_{i}ln(1-\widehat{y}_{i})] J(θ)=−m1i=1∑m[yilny i+(1−yiln(1−y i)]
加上一项,取权重的一范数
J ( θ ) = − 1 m ∑ i = 1 m [ y i l n y ^ i + ( 1 − y i l n ( 1 − y ^ i ) ] + λ ∑ i = 1 n ∣ θ i ∣ J(\theta)=-\frac{1}{m}\sum_{i=1}^{m}[y_{i}ln \widehat{y}_{i}+(1-y_{i}ln(1-\widehat{y}_{i})]+\lambda\sum_{i=1}^{n}|\theta_{i}| J(θ)=−m1i=1∑m[yilny i+(1−yiln(1−y i)]+λi=1∑n∣θi∣
θ i \theta_{i} θi为 w i b i w_{i}b_{i} wibi, λ \lambda λ相当于learning rate。
为什么范数接近于0,模型的复杂度会减小。
y = β 0 + β 1 x + β 2 x 2 + β 3 x 3 + ⋯ + β n x n + ε y=\beta_{0}+\beta_{1}x+\beta_{2}x^{2}+\beta_{3}x^{3}+\cdots+\beta_{n}x^{n}+\varepsilon y=β0+β1x+β2x2+β3x3+⋯+βnxn+ε
参数 β \beta β越小,曲线越平滑。或者说高阶参数趋近于0,模型退化成低阶。Enforce Weights close to 0.有时也叫weight decay。
常用的两种regularization
L1-regularization
J ( θ ) = − 1 m ∑ i = 1 m [ y i l n y ^ i + ( 1 − y i l n ( 1 − y ^ i ) ] + λ ∑ i = 1 n ∣ θ i ∣ J(\theta)=-\frac{1}{m}\sum_{i=1}^{m}[y_{i}ln \widehat{y}_{i}+(1-y_{i}ln(1-\widehat{y}_{i})]+\lambda\sum_{i=1}^{n}|\theta_{i}| J(θ)=−m1i=1∑m[yilny i+(1−yiln(1−y i)]+λi=1∑n∣θi∣
regularization_loss=0
for param in model.parameters():
regularization_loss+=torch.sum(torch.abs(param)) #先求绝对值,再求和
classify_loss=criteon(logits,target)
loss=classify_loss+0.01*regularization_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
L2-regularization(最常用,pytorch方便)
J ( W ; X , y ) + 1 2 λ ⋅ ∣ ∣ W ∣ ∣ 2 J(W;X,y)+\frac{1}{2}\lambda\cdot||W||^{2} J(W;X,y)+21λ⋅∣∣W∣∣2
λ \lambda λ是个超参数,需要人为调整。
device=torch.device('cuda:0')
net=MLP().to(device)
optimizer=optim.SCD(net.parameters(), lr=learning_rate, weight_decay=0.01)
criteon=nn.CrossEntropyLoss().to(device)
没有overfitting就设置weight-decay的话会导致性能急剧下降。