Pytorch torchvision构建Faster-rcnn(二)----基础网络
torchvision中提供了通过Resnet + FPN的方式构建基础网络,这里以resnet50为例实现基础网络的构建。
目录
BackboneWithFPN
IntermediateLayerGetter
FeaturePyramidNetwork
BackboneWithFPN
类BackboneWithFPN的在backbon_utils.py中,功能是给骨干网络加上FPN,定义如下:
class BackboneWithFPN(nn.Sequential):
def __init__(self, backbone, return_layers, in_channels_list, out_channels):
body = IntermediateLayerGetter(backbone, return_layers=return_layers)
fpn = FeaturePyramidNetwork(
in_channels_list=in_channels_list,
out_channels=out_channels,
extra_blocks=LastLevelMaxPool(),
)
super(BackboneWithFPN, self).__init__(OrderedDict(
[("body", body), ("fpn", fpn)]))
self.out_channels = out_channels使用时的几个参数:
- backbone : 骨干网络
- return_layers : 需要做fpn的layer的dict
- in_channels_list : return_layer对应的channels
一个简单的使用例子:
import torch
import torchvision.models as models
import torchvision.models.detection.backbone_utils as backbone_utils
backbone = models.resnet50()
return_layers = {'layer1': 0, 'layer2': 1, 'layer3': 2, 'layer4': 3}
in_channels_list = [256,512,1024,2048]
out_channels = 256
resnet_with_fpn = backbone_utils.BackboneWithFPN(backbone,
return_layers,in_channels_list,out_channels)
resnet_with_fpn返回的是一个orderDict,包含了5个fpn后的feature,channel分别为160,80,40,20,10:
input = torch.Tensor(4,3,640,640)
output = resnet_with_fpn(input)
# output是一个OrderedDict
print(type(output))
>>>
for k,v in output.items():
print(k)
print(v)
>>> 0
torch.Size([4, 256, 160, 160])
1
torch.Size([4, 256, 80, 80])
2
torch.Size([4, 256, 40, 40])
3
torch.Size([4, 256, 20, 20])
pool
torch.Size([4, 256, 10, 10])
下面要讲一下BackboneWithFPN中的两个重要组件:
-
IntermediateLayerGetter
-
FeaturePyramidNetwork
IntermediateLayerGetter
关于IntermediateLayerGetter,torchvision给出定义是这样的:
Module wrapper that returns intermediate layers from a model
参数定义:
- model : 输出特征的网络
- return_layers : 一个dict,key是要输出的feature名字,value是要被封装成的新名字。
其实意思就是返回特定层的feature,这个feature通过输入return_layers参数来控制,看一下官方给的使用例子:
Examples::
>>> m = torchvision.models.resnet18(pretrained=True)
>>> # extract layer1 and layer3, giving as names `feat1` and feat2`
>>> new_m = torchvision.models._utils.IntermediateLayerGetter(m,
>>> {'layer1': 'feat1', 'layer3': 'feat2'})
>>> out = new_m(torch.rand(1, 3, 224, 224))
>>> print([(k, v.shape) for k, v in out.items()])
>>> [('feat1', torch.Size([1, 64, 56, 56])),
>>> ('feat2', torch.Size([1, 256, 14, 14]))]可以看到通过指定参数return_layers={'layer1': 'feat1', 'layer3': 'feat2'},IntermediateLayerGetter返回了resnet18中的layer1和layer3,并封装成了新的名字'feat1'和'feat2',这也符合我们的设定,从feature size上看,layer1做了4倍下采样,layer3做了16倍下采样。
注意:这里的return_layer返回的一定是包含这个key的最后一个layer。比如在resnet中,我们知道layer1是一整个block组成的模块,IntermediateLayerGetter返回的将是整个layer1模块中的最后一层。
FeaturePyramidNetwork
FeaturePyramidNetwork的定义:
Module that adds a FPN from on top of a set of feature maps.
其实这个才是BackboneWithFPN的核心组件,功能也很明确,将FPN加到给定的feature maps中。
参数定义:
- in_channels_list : 输入feature的channels
- out_channels : 输出feature的channels(统一值)
- extra_blocks : 如果你想对某些层做额外的操作需要传入这个参数,注意extra_blocks一定要继承自ExtraFPNBlock类。
官方给的使用例子:
Examples::
>>> m = torchvision.ops.FeaturePyramidNetwork([10, 20, 30], 5)
>>> # get some dummy data
>>> x = OrderedDict()
>>> x['feat0'] = torch.rand(1, 10, 64, 64)
>>> x['feat2'] = torch.rand(1, 20, 16, 16)
>>> x['feat3'] = torch.rand(1, 30, 8, 8)
>>> # compute the FPN on top of x
>>> output = m(x)
>>> print([(k, v.shape) for k, v in output.items()])
>>> # returns
>>> [('feat0', torch.Size([1, 5, 64, 64])),
>>> ('feat2', torch.Size([1, 5, 16, 16])),
>>> ('feat3', torch.Size([1, 5, 8, 8]))]注意FeaturePyramidNetwork的输入和输出均为OrderedDict,可以看到输入的feat0/feat2/feat3经过FPN后通道数均变成了5。
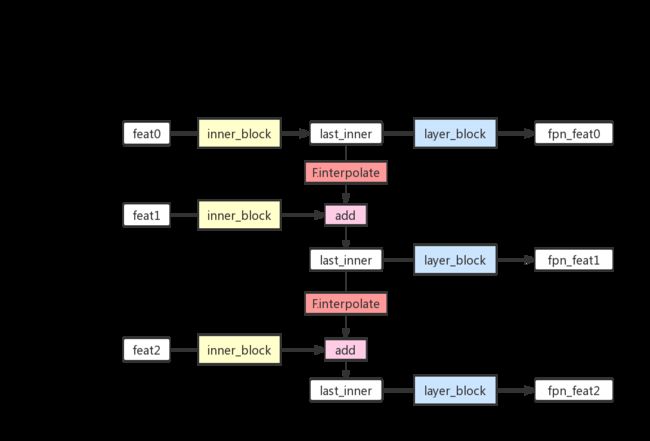
这里觉得FeaturePyramidNetwork的对FPN的实现写的还蛮简洁精妙的,这里对其中的forward部分做一些注释:
def forward(self, x):
# 输入的x是OrdereDict,将key和value解包成list
names = list(x.keys())
x = list(x.values())
# innner_blocks是一个包含很多个1*1卷积的ModuleList
# inner_block通过1*1卷积改变输入feature的通道数到out_channels
# 对于top的feature只做inner_block输出就好了
last_inner = self.inner_blocks[-1](x[-1])
results = []
results.append(self.layer_blocks[-1](last_inner))
# 因为已经对top feature做过处理,所以循环中[:-1][::-1]刨除对top feature的操作
for feature, inner_block, layer_block in zip(
x[:-1][::-1], self.inner_blocks[:-1][::-1], self.layer_blocks[:-1][::-1]
):
if not inner_block:
continue
# 先对输入的feature的inner_block的1*1卷积
inner_lateral = inner_block(feature)
feat_shape = inner_lateral.shape[-2:]
# last_inner是保存的邻近top层的feature
# interpolate即上采样upsample
inner_top_down = F.interpolate(last_inner, size=feat_shape, mode="nearest")
# 融合当前feature和top层feature
last_inner = inner_lateral + inner_top_down
# 降feature插入到result list的最前面
results.insert(0, layer_block(last_inner))
# 如果定义了extra_blocks,则对x特定的层做额外操作
# 比如这里实现的fpn中对last feature做了maxpooling后当做一个新的feature输出
if self.extra_blocks is not None:
results, names = self.extra_blocks(results, x, names)
# make it back an OrderedDict
out = OrderedDict([(k, v) for k, v in zip(names, results)])
return out可以对照着下图看一下代码中的变量和注释(灵魂画手只能帮大家到这里了):
至此,torchvision中backbone + fpn的操作实现完毕,不妨来看看torchvision是怎么使用的,在torchvision/models/detection/backbone_utils.py中可以看到这部分代码:
def resnet_fpn_backbone(backbone_name, pretrained):
# 定义backbone(resnet)
backbone = resnet.__dict__[backbone_name](
pretrained=pretrained,
norm_layer=misc_nn_ops.FrozenBatchNorm2d)
# 冻结除layer2/layer3/layer4外的其他层
for name, parameter in backbone.named_parameters():
if 'layer2' not in name and 'layer3' not in name and 'layer4' not in name:
parameter.requires_grad_(False)
# 需要做fpn的层是layer0~3,并且将fpn返回的feature封装了新的名字‘0’~‘3’
return_layers = {'layer1': 0, 'layer2': 1, 'layer3': 2, 'layer4': 3}
# 输出特征通道统一为256
in_channels_stage2 = 256
# 对应layer0~3的输入通道,为256~256*8
in_channels_list = [
in_channels_stage2,
in_channels_stage2 * 2,
in_channels_stage2 * 4,
in_channels_stage2 * 8,
]
out_channels = 256
# 返回BackboneWithFPN实例
return BackboneWithFPN(backbone, return_layers, in_channels_list, out_channels)这样通过调用resnet_fpn_backbone函数,就会生成一个对应resnet+fpn的骨干网络模型。