【Django 009】Django2.2视图函数详解(一):正则表达式获取url中路径信息以及反向解析
MTV模型中的V,也就是视图函数,是Django的重点。我们分几个小节来详细看看视图函数的多个功能。由浅入深,这一小节就先来看看如何获取客户端访问的url中的路径信息。
我是T型人小付,一位坚持终身学习的互联网从业者。喜欢我的博客欢迎在csdn上关注我,如果有问题欢迎在底下的评论区交流,谢谢。
文章目录
- 操作环境
- 视图响应
- url组成
- 路由匹配
- 获取url的路径信息
- 正则中的小括号
- 不带名称提取
- 带名称提取
- 小括号提取路径信息实战
- 硬编码与反向解析
- 反向解析实际操作
- url中提取的路径信息怎么办?
- 总结
操作环境
先总结下我的操作环境:
- Centos 7
- Python 3.7
- Pycharm 2019.3
- Django 2.2
因为Django长期支持版本2.2LTS和前一个长期支持版本1.11LTS有许多地方不一样,需要小心区分。
视图响应
视图响应的本质就是一个响应函数,用户请求了一个url,对应到后端的一个响应函数。
视图函数的返回分为两大类:
- json数据
- 网页
url组成
一个url由多个部分组成,以下面这个url来说明
http://www.testurl.com/search/?key=xxx&token=xxx#main
- http - 这部分为协议名,常见的就是http和https
- www.testurl.com - 协议后面的两个斜线和接下来的单斜线之间是IP和端口,http没特别注明端口是80端口,https是443端口。IP是通过DNS查询得到
- /search/ - 问号之前的内容是路径,在Django中就是通过这一部分来进行路由匹配,这也是我们这一小节关注的部分
- key=xxx&token=xxx - 问号之后井号之前的内容是查询参数,也叫QueryString,这将是我们下一小节关注的部分
- main - 井号后面的内容是页面的锚点,在html页面中定位
服务器不仅仅是路由,还会从url中获取信息,然后传递给视图函数,从而返回个性化的结果。对于后端来说,这些信息可以从路径中获取,也可以从查询参数或者是POST传递的内容中获取。我们这一节看看前者,下一节再看后者。
路由匹配
用户在浏览器输入url,例如http://127.0.0.1:8000/info/xiaofu/,Django去除url中的ip和端口,根据剩余的路径进行路由匹配,然后分配给对应的视图函数。
在匹配的时候要注意,类似于iptables的判断规则,Django的路由规则也是从上到下进行匹配,如果前面已经有匹配的路由,就不会继续往下走了。要注意的是,如果是Django2.2之前的版本,Django采用url方法进行正则匹配,类似re.match(pattern,url)的匹配规则,一旦在url的开头找到了pattern就认为匹配上,即使url和pattern并不是完全一致。
Django 2.2使用path方法进行字符串匹配,只有最有匹配才会进行路由。但是使用正则匹配的re_path方法还是会存在上述的问题。
例如,在App/urls.py中设定如下路由规则
re_path(r'hehe/',views.hehe),
re_path(r'hehehe/',views.hehehe),
那么在访问127.0.0.1:8000/app/hehehe的时候会执行views.hehe函数。
关于匹配规则后面的斜线,在写规则的时候不要忘记加,因为多数浏览器会在我们输入完url以后自动帮我们加上斜线。
获取url的路径信息
路径是用来做路由判断的,所以从路径中获取信息,就要从路由判断的地方着手。
在上一节的基础上,创建一个叫Two的app,在settings.py中注册,同时创建Two/urls.py文件,也在根目录下的urls.py中注册。
下面就试着从http://127.0.0.1:8000/two/index/id/中将id信息给提取出来,因为id不是唯一的,这里就要采用正则的方法来进行路由匹配和提取了。
这里需要说一下,如果想要进行正则表达式来进行匹配,Django 2.2以后使用re_path方法来实现,其和默认的path方法的对比可以参考我的另一篇博客《Django 2.2的path使用正则表达式匹配url的方法》。
下面补充下正则表达式中如何通过小括号来完成提取操作的。
正则中的小括号
python中的正则模块re使用小括号来进行提取。
例如
In [8]: re.match(r'index/(\d+)/$','index/1314/').group(1)
Out[8]: '1314'
如果有多个小括号,这里的group必须要从1开始,0的话代表所有内容。
如果想给每个小括号内的内容取一个名字也有固定格式(?P,例如
n [9]: re.match(r'index/(?P\d+)/$','index/1314/').group('id')
Out[9]: '1314'
不带名称提取
在Two/urls.py中设定路由规则,同时用小括号把想要提取的内容提取出来
urlpatterns = [
re_path(r'index/(\d+)/',views.index),
]
这一条路由规则会将匹配到的url中末尾的数字部分拿出来,传递给对应的view函数,这里就是index。
新建view函数如下
def index(request,id):
return HttpResponse(id)
因为从路由那儿多传递来了一个参数,所以这里的view函数的参数也要多一个,名字随意。之后如果访问的url是http://127.0.0.1:8000/two/index/1234/那么就会在网页上打印出1234来。
带名称提取
像上面这样提取信息是没有问题的,不过假设路径很长,其中有多个信息要提取的话可能会造成多个参数含义的不清晰,而且参数获取顺序和view函数传递顺序不能变。这时候最好是用上面提到的给提取信息命名的办法来更清晰地进行提取。
例如修改路由规则如下
re_path(r'index/(?P\d+)/(?P\w+)/',views.index),
这样就提取出了两个信息,分别命名为num和name。
然后修改view函数如下
def index(request,num,name):
return HttpResponse('num:{},name:{}'.format(num,name))
注意这里函数的参数名一定要和前面的命名一致才可以,顺序先后无所谓。
这时候如果访问http://127.0.0.1:8000/two/index/1314/xiaofu/,网页上就会显示
num:1314,name:xiaofu
小括号提取路径信息实战
下面通过一个实战来练习一下上面的内容。
首先在models中创建两个模型,注意其中的外键关系
class Company(models.Model):
c_name = models.CharField(max_length=30)
class Employee(models.Model):
e_name = models.CharField(max_length=16)
e_company = models.ForeignKey(Company, on_delete=models.CASCADE)
创造迁移,然后迁移到数据库,最后往两张表中添加点数据,如下
| id | c_name |
|---|---|
| 1 | Xiaomi |
| 2 | Dami |
| 3 | Laomi |
| id | e_name | e_company_id |
|---|---|---|
| 1 | James | 1 |
| 2 | Xiaofu | 1 |
| 3 | Davis | 2 |
| 4 | Wade | 2 |
| 5 | Zion | 3 |
| 6 | Gigi | 3 |
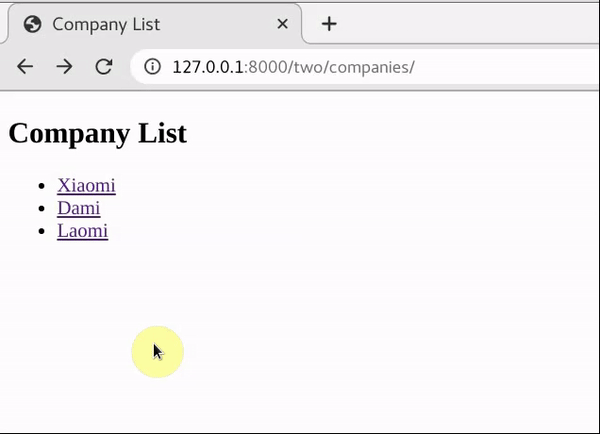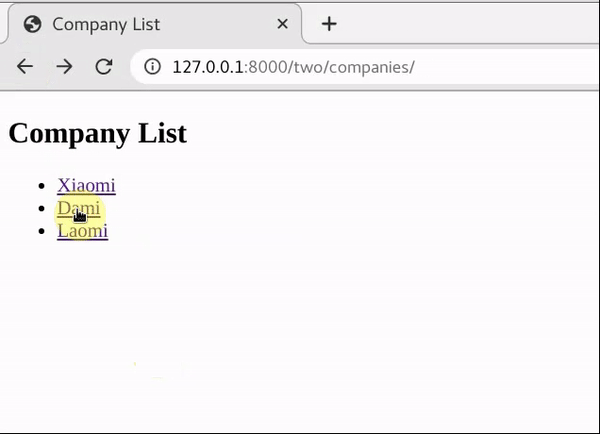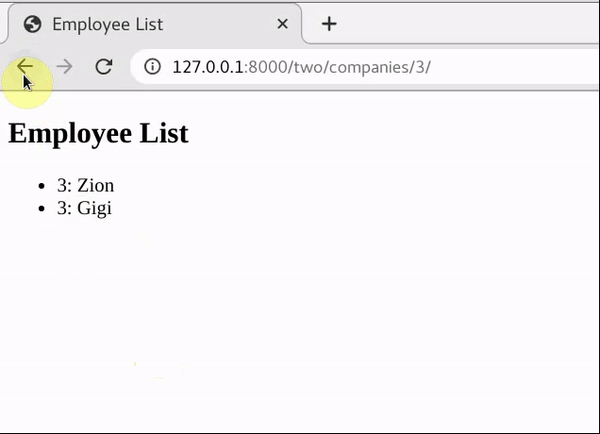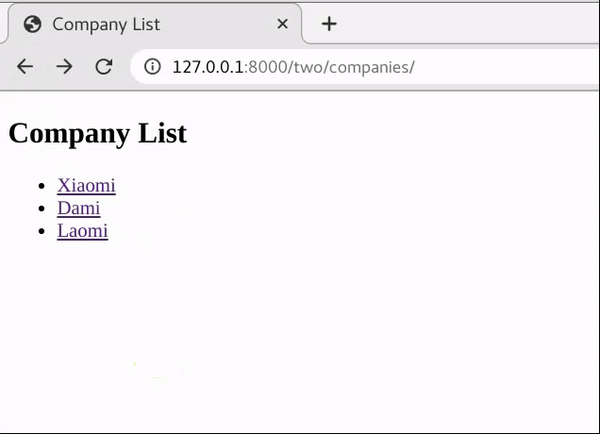
下面的目标是制作一个网页返回公司的列表,并且点击每个公司的名字会显示该公司的员工信息。
首先创建返回公司列表的路由,view函数,模板页面,如下
path('companies/', views.companies),
def companies(request):
result = Company.objects.all()
context = {
'companies': result
}
return render(request,'company_list.html',context=context)
Company List
Company List
{% for company in companies %}
- {{ company.c_name }}
{% endfor %}
重点就是这里的模板文件,对每一个公司名都做了一个链接,跳转的地址为当前url+’/’+公司id。这是使用相对路径的用法。举个例子,用户访问http://127.0.0.1:8000/two/companies/到了这个页面,之后点击Xiaomi,就会跳转到http://127.0.0.1:8000/two/companies/1。关于页面跳转的路径问题,可以参考我的另一篇博客《HTML通过href实现页面跳转的几种不同路径写法》。
接下来就是从跳转的url中获取这个id信息了。创建另一个员工信息的路由,view函数,模板文件如下
re_path(r'companies/(?P\d)/',views.employees),
def employees(request,id):
result = Employee.objects.filter(e_company_id=id)
context = {
'employees': result
}
return render(request,'employee_list.html',context=context)
因为前面提取出的信息用id来命名,所以这里view函数的第二个参数只能是id
Employee List
Employee List
{% for employee in employees %}
- {{ employee.e_company_id }}: {{ employee.e_name }}
{% endfor %}
这样就达到了目的,效果如下gif所示
硬编码与反向解析
既然说到了页面跳转,就不得不说一下硬编码与反向解析的问题。
上面的模板h5中实现页面跳转使用的是一条写死的路径,也就是http://127.0.0.1:8000/two/companies/1,假设有一天老板觉得这个url不太好,要改为http://127.0.0.1:8000/index/homes/1之类的就麻烦了,不仅urls.py中要改,也许h5文件里面有很多的跳转href都要改。有没有类似于编程中定义变量的方式,改一个变量的内容,所有的值都一劳永逸都改了呢?
有!这个变量就是命名空间。
在项目根路由中为include进来的应用级别路由指定一个namespace值,然后在应用级别的路由中指定一个name值,这样在h5中进行跳转时就可以利用这两个变量来进行url的解析。
下面用实例来看看怎么做。
反向解析实际操作
首先在根路由urls.py中修改下路由如下
path('test/',include(('Two.urls', 'test_namespace'))),
Django2.2这里include方法要接一个二维tuple,分别是import方式的路由模块(也就是import时候怎么写这里也怎么写),和namespace的名字。
或者,这里依然像下面这么写
path('test/',include('Two.urls')),
但是在应用级别路由App/urls.py中开头添加下面这一行声明也是可以,这里的app_name不需要任何import,直接使用
app_name = 'test_namespace'
设定好了namespace,然后在应用级别的路由规则中设定name如下
path('companies/1/',views.test, name='test_name')
此后在view函数test返回的h5中利用过滤器url可以进行反向解析
{{ company.c_name }}
这样子点击h5中的公司名字就会返回http://127.0.0.1:8000/NAMESPACE/NAME这样的url,即使后来再修改namespace和name的url值,这里也不需要额外地维护了。
但是又有一个问题出来了,如果要像上面那样通过正则表达式提取信息又该怎么办呢?
url中提取的路径信息怎么办?
这里也比较好理解,从url提取了多少信息,在反向解析为url的时候传递多少个进去就好了。
还是以上面点击公司名返回公司对应员工列表为例,修改应用级别的路由规则如下
re_path(r'companies/(?P\d)/',views.employees, name='test_name'),
那么在反向解析的时候只需要传递一个id进去即可,h5中如下
{{ company.c_name }}
模板语言中url过滤器使用可以参见官方文档
如果有多个信息,就用空格隔开进行赋值即可,例如
路由规则如下的话
re_path(r'companies/(?P\w+)/(?P\d)/',views.employees, name='test_name'),
反向解析时候如下
{{ company.c_name }}
当然,别忘记view函数的参数也得有两个,而且名字必须得是id和name才可以。
总结
这一小节我们成功从客户端访问的url中提取出了路径信息,这个只是小试牛刀,毕竟通过路径来实现多样性和个性化的访问查询还是很少,更多的情况下是通过查询参数和POST传递的内容。下一节我们再看看如何获取这一类的信息。