
最近项目中用到这个nb的玩意,所以就花时间研究了下,同时整理下助自己记忆。这个猛虎上山的logo就是rocksdb官方的logo。 同时借用官网的一句话来综述下: 一个持久性的key-value存储,为了更快速的存储环境而生。
rocks特性
rocksdb是一个可嵌入的C++库, 可用于存储任意大小字节流的key, value 结构。支持的方法有Put, Get, Delete, 传统的数据库的常用方法CRUD.其中update这个方法对rocksdb来说也是一种Put方法。同时因为rocksdb是按key的顺序存储数据,所以还支持Iterator迭代的方法,即就是定位到数据库中的一个key后,可以从这个key开始正向的扫描,也可以逆向的扫描。同时支持PrefixExtractor前缀迭代,假设我们存储的key有20位,前10位为时间信息,那么我们可以根据前缀迭代把某个时间段的数据拉出来,这个需要我们在创建数据库时配置PrefixExtractor的位数为10,默认是0。同时rocksdb支持快照Snapshot, 每次以只读方式Get数据时都会创建一个快照,在这个时间点之前的数据对Get可见,之后不可见。同时rocksdb还提供一些用户可定义的filter, 比如提供bloomfilter可以优化读性能;提供DB级别的ttlfilter, 使得超过过期时间的数据在compaction过程中被删除。
Rocksdb还支持写入的原子性,数据的持久化,数据校验,数据压缩,数据备份,数据缓存等一些特性。
写逻辑
我们从一条数据对写入来了解rocksdb的存储结构吧。
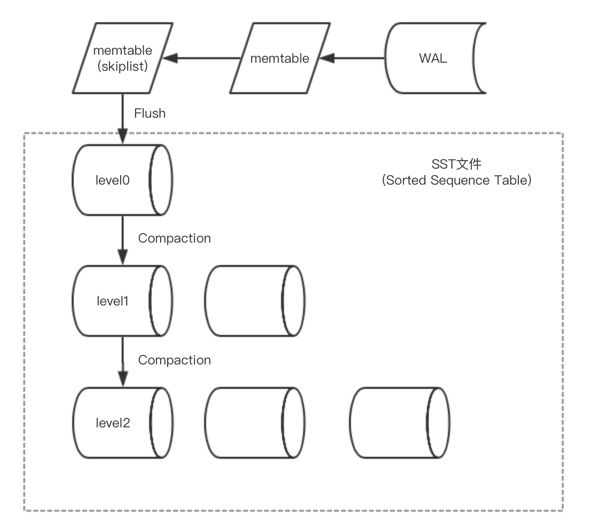
首先当一条数据写入rocksdb时, 会将这条记录封装成一个batch, 也可以是多条记录一个batch,由batch来保证原子操作。就是一个batch里的数据要么全部成功要么全部失败。
第一步先以日志的形式落地磁盘,记write ahead log, 落地成功后再写入memtable。这里记录wal的原因就是防止重启时内存中的数据丢失。所以在db重新打开时会先从wal恢复内存中的mentable. 可配置WAL保存在可靠的存储里。
这里的memtable是在内存中的一个跳表结构(skiplist)。每一个节点都是存储着一个key, value. 跳表可使查找的复杂度为logn, 同时插入数据非常简单。每个batch独占memtable的写锁。这个是为了避免多线程写造成的数据错乱。
当memtable的数据大小超过阈值(write_buffer_size)后,会新生成一个memtable继续写,将前一个memtable保存为只读memtable.
当只读memtable的数量超过阈值后,会将所有的只读memtable合并并flush到磁盘生成一个SST文件。这里的SST属于level0, level0中的每个SST有序,整个level0不一定有序。
当level0的sst文件数超过阈值或者总大小超过阈值,会触发compaction操作,将level0中的数据合并到level1中。同样level1的文件数超过阈值或者总大小超过阈值,也会触发compaction操作, 这时候随机选择一个sst合并到更高层的level中。这里有两点比较重要,1:level1 及其以上的level都整体有序。每个sst存储一个范围的数据互不交叉互不重合;2: level1 以上的 compaction操作可以多线程执行,前提是每个线程所操作的数据互不交叉。
那么这样数据就由内存流入到高层的level。我们理想状态下,所有的数据都存在非level0的一层level上。这样可以保证最高效的查询速度。所以对rocksdb来说, 每次写都保证着原子性,所有数据都会落地到磁盘,保证着数据的可靠性和持久性。
读逻辑
同样,我们看一条数据是如何被读取的。
首先RocksDB中的每一条记录(KeyValue)都有一个LogSequenceNumber,从最初的0开始,每次写入加1。lsn在memtable中单调递增。之前提到的snapshot即就是基于lsn实现,每次以只读模式打开时,记录一个lsn, 大于该lsn的key不可见。
首先读操作先访问memtable。跳表的时间复杂度可达到logn, 如果不存在会访问level0, 而level0整体不是有序的, 所以会按创建时间由新到老依次访问每一个sst文件。所以时间复杂度为m*logn。如果仍不存在,则继续访问level1,由于level1及其以上的level都整体有序,所以只需要访问一个sst文件即可。 直到查找到最高层或者找到这个key。所以读操作可能会被放大好多倍。
rocksdb做了几点优化,一点是为每个SST提供一个可配置的bloomfilter. 每个level的配置不一样。这样可以快速的确认一个key在不在某个SST中,这点以牺牲磁盘空间来换取时间。另一点是提供可配置的cache, 用于保存访问过的key在内存中, 这里有一点就是它缓存的是某个key在SST文件中的整个block里的记录。
存储结构之memtable
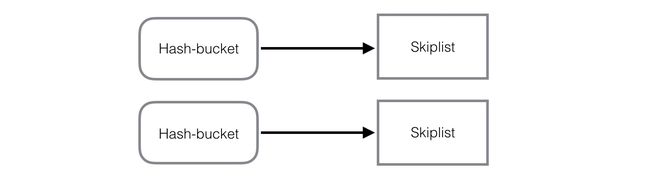
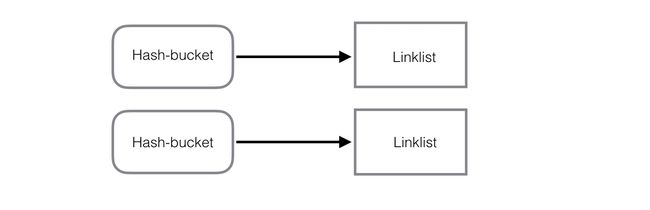
rocksdb的memtable, 默认是skiplist跳表结构, 但它也同时支持hash-skiplist, hash-linklist结构。在创建数据库时,可配置选择存储合适结构。什么时候选择合适的结构类型,这块还值得研究。如果将所有的数据都保存到内存中,这时候用hash-linklist是不是更合适呢。
skiplist 结构:

hash-skiplist结构:
hash-linklist结构:
存储结构之SST
SST(Sorted Sequence Table)
SST作为rocksdb第二个存储方式, 它的数据主要以block块的方式存储,默认是4k大小。ps之所以默认设定4k是因为我们一般的操作系统存储的每个页刚好是4k, 这样每次加载一份数据一个block刚好就是一页。这样就不会造成,block过大需要分页存储或者block过小一页存储一个block造成内存浪费。

其中每个block以最后的crc码来效验数据的正确性。
根据block存储的不同数据可以分为多种类型。其中Datablock里存储着压缩的key, value 记录,是数据层。Metablock存储着filter的数据,其中bloomfilter, prefix_bloomfilter, 还有用户自定义的一些filter的数据存在这里。 Metablock Index记录着filter的大小偏移量等信息。Indexblock记录着每一个Datablock的最大key和最小key的偏移量等信息。 Footer记录着Metablockindex块的偏移量和大小以及Indexblock的偏移量和大小等信息。

Flush操作
* 首先当只读memtable的数量大于阈值,如果没有其它线程flush,则将该次操作加入队列。
* 遍历skiplist,通过迭代器逐一扫描key-value,将key-value写入到data-block,
* 如果data block大小已经超过阈值,或者key-value对是最后的一对,则触发一次block-flush, 同时根据压缩算法对block进行压缩,并生成对应的index block记录;
* 所有数据更新完后, 写入index block,meta block,metaindex block以及footer信息到文件尾;
* 并将变化sst文件的元信息写入manifest文件。 同时清理wal日志文件。
Compaction操作
* rocksdb会定期的检测每个level的状态, 并为每个level计算score. score通过level实际的size/base_size来计算;level0的score是通过实际sst数/ level0 的sst文件数阈值计算。
* 如果score>1 则会触发compaction, 找score最大的level,根据一定策略从中选择一个sst文件进行compaction.
* 根据这个sst文件的minkey, maxkey找到leveln+1层中有重叠的sst文件。 多个sst文件进行归并排序,生成新的有序sst文件。
* 将变化的sst文件的信息写入manifest文件。
数据库文件结构

SST
rocksdb的数据文件, 严格说包含SST文件,还有内存中的memtable数据。
memtable写入到一定阈值,可能是这个参数max_total_wal_size(待验证),会flush memtable里的数据到SST level0文件。level0文件的key不一定是有序的,但leveln(n>0)的key必然是有序的.
可通过ldb工具来查看SST的内容
```
# ../ldb --db=./data/fansnum_tail scan
1162218773 : 34
1162222073 : 4433
1162231091 : 1025
1162231094 : 4
1162231403 : 72
1162233913 : 66
1162241104 : 35
./db_bench --db=/data1/xiaodong28/PacketServer/PacketComputation/offline_update/fansnum/ --benchmarks=fillrandom --num=10000 --compression_type=none
```
MANIFEST
*MANIFEST*: 记录rocksdb最近的状态变化日志。其中包含manifest日志 和最新的文件指针 *CURRENT*, 记录最近的MANIFEST
manifest日志: *MANIFEST-(seq number)*, 记录一系列版本更新记录。
在RocksDB中任意时间存储引擎的状态都会保存为一个Version(也就是SST的集合),而每次对Version的修改都是一个VersionEdit,而最终这些VersionEdit就是 组成manifest-log文件的内容
```
/data1/rocksdb/rocksdb/bin/ldb --path=./fansnum/MANIFEST-000014 manifest_dump
```
log
WAL文件。 rocksdb在写数据时, 先会写WAL,再写memtable。为了避免crash时, memtable的数据丢失。服务重启时会从该文件恢复memtable。
OPTIONS
rocksdb的配置文件, 配置参数说明可参考下一小节。
IDENTITY
存放当前rocksdb的唯一标识
LOCK
LOCK 进程的全局锁,DB一旦被open, 其他进程将无法修改,报类似以下错误。
```
Open rocksdb ../data/fansnum_rocksdb/ failed, reason: IO error: while open a file for lock: ../data/fansnum_rocksdb//LOCK: Permission deniedCommand init, costtime: 0.946000 ms
```
LOG
rocksdb的操作日志文件, 可配置定期的统计信息写入LOG. 可通过info_log_level调整日志输出级别; 通过keep_log_file_num限制文件数量 等等。
写数据测试
对于rocksdb的写操作做了个测试数据分析:
* 测试机器是20CPU, 32G的内存, STAF磁盘
* 测试数据库的总key量为3.9亿,大小为5.2G。
* 最终生成的数据文件大小为2.63G, 数据压缩比为50.6%,
* 生成的level结构为Level0没有数据,Level1 5个sst文件,总大小290.22M; Level2 43个文件,总大小2.35G. 我们从level文件结构可以看出结果还是比较好的,比如查一个key,只需读level1和level2中各一个sst文件即可。
* 总compaction次数255次,写磁盘总数据量为22.9G, 写放大为8.7,这就相当于在这次测试中平均每条记录写了8.7次磁盘。而且这个值会随着数据量的增大而增大。
* 总耗时1140s, 平均每秒写34.2w条数据。
读性能测试
针对LRUcache, 做了一个读性能的测试的数据分析
测试机器是20CPU, 32G的内存, STAF磁盘, 测试数据库的总key量为3.9亿, 数据库大小为2.63G,测试数据的key量为1kw。根据创建不同大小的LRUcache, 主要关注了两个性能指标,平均耗时和cache命中率。其中db默认的cache是8M的LRUcache。上图可以看出随着cache大小的增加, 平均耗时再递减,命中率在递增。16GB的cache可以将所有数据全部存在cache中。那时查询一个key的平均耗时需要3.3微妙。

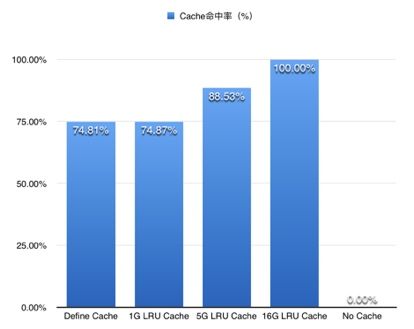


从上图可以看出不同比例的数据的最大耗时, 比如在配置cache的db中,95%数据的都可以在14微秒之内返回, 99%的数据都可以在25微秒之内返回。配置最大cache时单线程访问可以达到30w的qps。
可优化的点
写放大
由于存在数据的compaction操作,所以rocksdb实际总的写磁盘数据量并不是等同于输入的数据量, 我们看下我写一次全量粉丝数的数据量5.2G, 经过压缩后2.63G, 直到所有数据更新完成后写磁盘的量达到22.9G, 近8.7倍的写放大。
读放大
同时rocksdb也存在读放大,基于之前的读操作内容,我们可以知道一次get操作可能包含多次读磁盘操作。而且每次读一个记录会将该记录所在的block都读入内存。
空间放大
空间放大主要表现在数据的更新和删除实际都在compaction操作中执行,这样在compaction之前一个key在数据库中会存好多份记录。这样造成的空间的浪费。
应用场景
通过以上对rocksdb的了解,rocksdb比较适合小规模数据存储,因为数据量越大,其写放大,读放大,空间放大就会越严重, 但具体到什么规模这个还定义不了,当前我们本地存储10G左右的数据,性能杠杠的。适用于对写性能要求高,同时有大量内存来缓存SST数据以达到快速读取的场景。适用于存储变长key,value的场景。