《深入浅出强化学习 原理入门》读书笔记(1)
目录
前言
强化学习的分类
仿真环境
强化学习基础
MDP
环境搭建:
前言
- 其他人的读书笔记资源
- pdf和代码资源
- 这个是作者的知乎专栏
- 作者的知乎
豆瓣的褒贬不一,如果有VPN其实可以直接开始看国外的教程,如果英文不好,可以选择看这本书。把中间的不懂的概念补上去的话其实这本书挺不错的。
强化学习知乎教程推荐
强化学习知乎2018论文推荐
前六章很大部分参考了David Silver的网络课程,以及强化学习鼻祖Richard S. Sutton等人所著的Reinforcement Learning: An Introduction;后面则是作者自己的论文阅读得到的姿势。(致敬了不少家伙),所以我想,如果有能力看外国入门视频,然后阅读外国文献,将会有很大的帮助。
虽然豆瓣上的评分不高,但是也许是因为我没有看过英文视频以及之前就接触过MDP的原因我看着还行,只是作者没有将论文攥写的标准放在书上,所以很多表述不清,或者就看起来很水
强化学习是解决决策优化问题的,更准确的说是解决序贯决策问题,与深度学习不同,强化学习有两个主题:环境(状态)、智能体。最简单的决策优化问题就是马尔科夫决策过程,Markov Decision Process,简称MDP,面对有限多的状态,采取有限多可选的动作,在特定的状态下的收益也是明确的,这个问题是经典的决策优化问题模型,可以用动态规划来解决,但是随着对环境以及决策体的深入研究,有限的状态集合也会变成无限的状态集合,状态有时候也不能被完全观测到,该怎么办呢?强化学习现在就是为了解决这个问题。
强化学习的分类
- 基于模型的强化学习;无模型的强化学习。一般基于模型的效率高,无模型的通用性高。
- 根据策略更新和学习⽅法:基于值函数的强化学习算法(学习值函数,最后根据值函数采用贪婪策略)、基于直接策略搜索的强化学习算法(策略参数化)以及AC的⽅法(联合值函数和直接策略搜索)
-
根据环境返回的回报函数是否已知,强化学习算法可以分为正向强化学习和逆向强化学习。
为了提升强化学习的效率和实⽤性,学者们⼜提出了很多强化学习算法,如分层强化学习、元强化学习、多智能体强化学习、关系强化学习和迁移强化学习等。
仿真环境
使用openAI 的gym ,现在已经可以用anaconda下载。学会了gym之后,openAI还有其他比如如universe、roboschool 和baselines的开源强化学习软件
接触编程语言第一件事就是helloworld,接触新板子第一件事就是点灯,接触RL的第一件事,就是用GYM实现一个小的demo
教程:https://blog.csdn.net/philthinker/article/details/79810249
https://blog.csdn.net/pursuit_zhangyu/article/details/79734265
https://blog.csdn.net/ewba_gis_rs_er/article/details/84671406
这里的程序不是完整的程序.render是刷新,然后才可以下面的操作,用win10pip install gym之后打开默认的python,输入下面东西出来一个窗口后就卡住了。不过出现了就算是环境装好了。
import gym env = gym.make('CartPole-v0') env.reset env.render()
强化学习基础
就像控制算法也是由经典控制算法到线代控制算法,从线性到非线性,我们会学习很多强化学习的先验知识MDP,看看这种基于模型的问题是如何解决的,然后通过这个基本的模型引申到加入这个模型中的参数未知,我们是如何使用强化学习来解决的。
我们知道,强化学习最基本的原理如下图
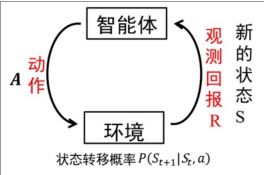
解释:智能体每次通过现在的状态以及自己的策略决策做出动作A,环境根据智能体的动作进行相应的状态转移到下一个状态,环境基于St和A给出相应的回报R,不断的循环,产生很多组,St A R数据,学习算法根据这些数据修改相应的策略,然后再进行环境交互最后到达策略最优。
为了简化问题,我们假设下一个状态仅仅和上一个状态有关系,而和前一个状态之前的状态没有关系,这样的性质称为马尔可夫性。数学表示:P[St+1|St]=P[St+1|S1,S2,...,St] (已知当前状态St的条件下发生St+1的概率和知道全部状态的条件下发生的概率相同)
知道了这个就可以定义马尔可夫过程了,用(S,P)表示,S是状态的有限集合,假设是n维向量,P是nxn的矩阵,
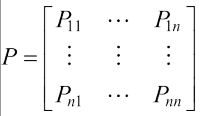
P11表示从S1到S1的概率。但是马尔可夫过程只表示了环境,缺少RL中重要的一点,智能体的决策。
于是我们在这个基础上加上A R y来引出MDP,马尔可夫决策过程。
MDP
之前在数模国赛RGV的调度问题时候,就把问题建立成MDP问题求解,算是了解一点。这里的A表示action:智能体做出的动作,P变成状态转移概率,是包含了动作的转移概率,P(St+1=s`|St=s,At=a]表示在状态s下采取动作 ,下一刻状态变成s`的概率。R是回报函数
,下一刻状态变成s`的概率。R是回报函数
那么我们某次决策策略可以用Π(a|s)=p[At=a|St=s]表示,是状态为s的时候我们选择某个动作的概率,Π就表示不同状态不同的动作概率分步。如果说这个机器人特别死板贪心,那么这个概率在某一个状态下就会出现某一个动作的概率为1,其他都为0的情况。
我们的决策是策略产生的,我们对策略的好坏可以化为对一个个决策获得的回报的函数,这里我们使用累计回报函数Gt

因为决策是有概率的,所以从某个状态出发经过的状态序列也是随机的

所以我们利用Gt的期望作为描述一个状态的价值,这个叫做状态值函数
 (原始定义)
(原始定义)
这个式子的含义是在Π的策略下,从s出发的所有序列的累计回报的期望
一个问题,我们希望求出每一个状态的值函数,而且我们总会希望往值函数大的状态前进
相应的我们也定义一个在特定状态下做出特定动作会得到的累计奖励的期望的定义:状态行为值函数
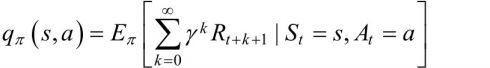 (原始定义)
(原始定义)
比如一个函数是双变量的函数,表示了一个三维空间中的曲面f(x,y)=x+y^2,求其关于x的期望,我们可以得到f(y)=y^2这个平面穿过原点与y轴平行,我说这个是因为我们的Gt是一个多变量的函数,输入一个s,以及确定策略之后,是由Rt+1,Rt+2....线性构成的,所以可知我们的状态值函数求期望的时候,是对每一个状态都求取期望,那么在对St+1的状态的奖励Rt+1求取期望的时候,由于马尔可夫性,只有St这个变量与R(t+1)有关 【假设(R(t+1)=f(S(t))) f是决定回报的某种函数】 知道了这个我们就可以推出贝尔曼方程了
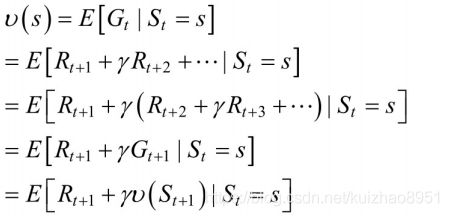
最后两行的展开

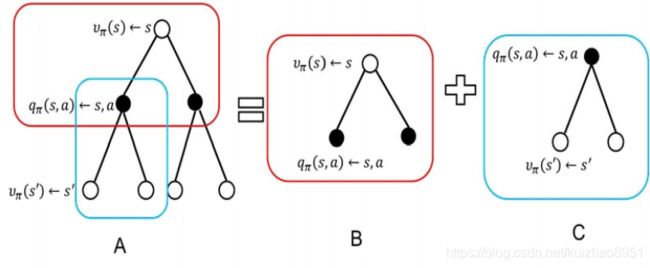
同样我们可以得到状态动作值函数的贝尔曼方程
![]()
又由定义可知


上面两个式子联立

所以你可以知道需要知道这一状态的q(s,a)需要Rsa Pss`a VΠ(s`),计算过程如下图
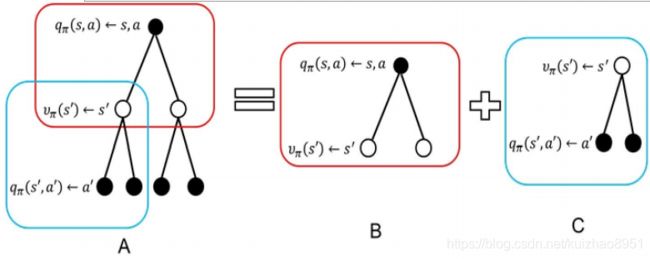
每一个s都会有n个动作可以做,每一个动作都会有回报,并且以一定概率到新的状态,每一个状态的回报又等于这些不同动作的概率加权的状态行为值函数之和……
我们计算状态值函数的目的是为了构建学习算法,让算法从数据中得到最优的策略。啥意思,就是我们需要不断的改进算法,使得算法可以在所有决策中选择都选择最优决策 以及最优状态行为值函数
以及最优状态行为值函数
,由此我们可以联立贝尔曼方程得到贝尔曼最优方程:

所以,如果我们知道了最优状态动作值函数,那么我们直接选择这个最优的动作即可(概率为1),这个策略是贪婪 ,当然还有其他 的策略,比如![]() 、
、![]() 、
、![]()
贪婪:
![]()
 、
、
 、
、
最后
我们就会从
得到

红色部分表示最佳决策
环境搭建:

机器人初始状态任意,X死亡,红圈找到金币。
下面是环境的代码grid_mdp.py
import logging
import numpy
import random
from gym import spaces
import gym
logger = logging.getLogger(__name__)
class GridEnv(gym.Env):
metadata = {
'render.modes': ['human', 'rgb_array'],
'video.frames_per_second': 2
}
def __init__(self):
self.states = [1,2,3,4,5,6,7,8] #状态空间
self.x=[140,220,300,380,460,140,300,460]
self.y=[250,250,250,250,250,150,150,150]
self.terminate_states = dict() #终止状态为字典格式
self.terminate_states[6] = 1
self.terminate_states[7] = 1
self.terminate_states[8] = 1
self.actions = ['n','e','s','w']#东西南北
self.rewards = dict(); #回报的数据结构为字典
self.rewards['1_s'] = -1.0
self.rewards['3_s'] = 1.0
self.rewards['5_s'] = -1.0
self.t = dict(); #状态转移的数据格式为字典
self.t['1_s'] = 6
self.t['1_e'] = 2
self.t['2_w'] = 1
self.t['2_e'] = 3
self.t['3_s'] = 7
self.t['3_w'] = 2
self.t['3_e'] = 4
self.t['4_w'] = 3
self.t['4_e'] = 5
self.t['5_s'] = 8
self.t['5_w'] = 4
self.gamma = 0.8 #折扣因子
self.viewer = None
self.state = None
def getTerminal(self):
return self.terminate_states
def getGamma(self):
return self.gamma
def getStates(self):
return self.states
def getAction(self):
return self.actions
def getTerminate_states(self):
return self.terminate_states
def setAction(self,s):
self.state=s
def _step(self, action):#输入动作,输出下一个时刻的状态、回报、是否中止和调试信息,调试信息可以为空,但是不能缺少,可以用{}来代替
#系统当前状态
state = self.state
if state in self.terminate_states:
return state, 0, True, {}
key = "%d_%s"%(state, action) #将状态和动作组成字典的键值
#状态转移
if key in self.t:
next_state = self.t[key]
else:
next_state = state
self.state = next_state
is_terminal = False
if next_state in self.terminate_states:
is_terminal = True
if key not in self.rewards:
r = 0.0
else:
r = self.rewards[key]
return next_state, r,is_terminal,{}
def _reset(self):#随机初始化机器人的状态
self.state = self.states[int(random.random() * len(self.states))]
return self.state
def render(self, mode='human', close=False):#画图 可视化
if close:
if self.viewer is not None:
self.viewer.close()
self.viewer = None
return
screen_width = 600
screen_height = 400
if self.viewer is None:
from gym.envs.classic_control import rendering#调用rendering中的画图函数
#创建600*400的窗口
self.viewer = rendering.Viewer(screen_width, screen_height)
#创建网格世界
self.line1 = rendering.Line((100,300),(500,300))
self.line2 = rendering.Line((100, 200), (500, 200))
self.line3 = rendering.Line((100, 300), (100, 100))
self.line4 = rendering.Line((180, 300), (180, 100))
self.line5 = rendering.Line((260, 300), (260, 100))
self.line6 = rendering.Line((340, 300), (340, 100))
self.line7 = rendering.Line((420, 300), (420, 100))
self.line8 = rendering.Line((500, 300), (500, 100))
self.line9 = rendering.Line((100, 100), (180, 100))
self.line10 = rendering.Line((260, 100), (340, 100))
self.line11 = rendering.Line((420, 100), (500, 100))
#创建第一个骷髅
self.kulo1 = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(140,150))
self.kulo1.add_attr(self.circletrans)
self.kulo1.set_color(0,0,0)
#创建第二个骷髅
self.kulo2 = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(460, 150))
self.kulo2.add_attr(self.circletrans)
self.kulo2.set_color(0, 0, 0)
#创建金条
self.gold = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(300, 150))
self.gold.add_attr(self.circletrans)
self.gold.set_color(1, 0.9, 0)
#创建机器人
self.robot= rendering.make_circle(30)
self.robotrans = rendering.Transform()
self.robot.add_attr(self.robotrans)
self.robot.set_color(0.8, 0.6, 0.4)
self.line1.set_color(0, 0, 0)
self.line2.set_color(0, 0, 0)
self.line3.set_color(0, 0, 0)
self.line4.set_color(0, 0, 0)
self.line5.set_color(0, 0, 0)
self.line6.set_color(0, 0, 0)
self.line7.set_color(0, 0, 0)
self.line8.set_color(0, 0, 0)
self.line9.set_color(0, 0, 0)
self.line10.set_color(0, 0, 0)
self.line11.set_color(0, 0, 0)
self.viewer.add_geom(self.line1)
self.viewer.add_geom(self.line2)
self.viewer.add_geom(self.line3)
self.viewer.add_geom(self.line4)
self.viewer.add_geom(self.line5)
self.viewer.add_geom(self.line6)
self.viewer.add_geom(self.line7)
self.viewer.add_geom(self.line8)
self.viewer.add_geom(self.line9)
self.viewer.add_geom(self.line10)
self.viewer.add_geom(self.line11)
self.viewer.add_geom(self.kulo1)
self.viewer.add_geom(self.kulo2)
self.viewer.add_geom(self.gold)
self.viewer.add_geom(self.robot)
if self.state is None: return None
#self.robotrans.set_translation(self.x[self.state-1],self.y[self.state-1])
self.robotrans.set_translation(self.x[self.state-1], self.y[self.state- 1])
return self.viewer.render(return_rgb_array=mode == 'rgb_array')
有了这个py文件之后我们就可以注册这个环境了
- 讲环境文件(grid_mdp.py)拷贝到gym安装目录文件夹中(因为要使用rendering模块),我因为是用windows的anaconda安装的,位置是D:\ANACONDA\Lib\site-packages\gym\envs\classic_control
- 打开文件夹D:\ANACONDA\Lib\site-packages\gym\envs\classic_control下的
 加入这句话
加入这句话 - 进入
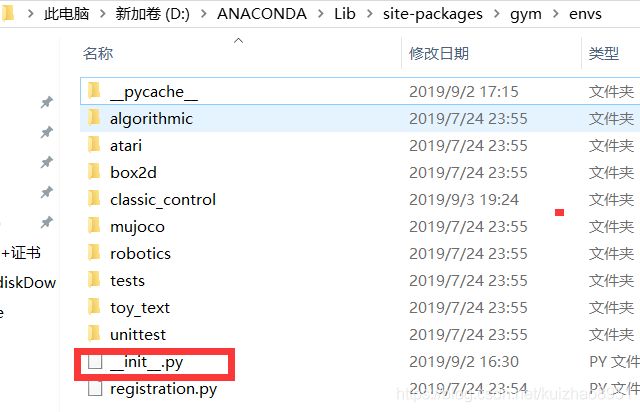 ,添加代码:
,添加代码:
register(
id='GridWorld-v0',
entry_point='gym.envs.classic_control:GridEnv',
max_episode_steps=200,
reward_threshold=100.0,
)注意要顶格,第一个是id 随便,第二个是函数入口,后面原则上不用。
打开shell输入
import gym
env=gym.make('GridWorld-v0')
env.reset()
env.render()出乎意料的一些小状况:可能是因为版本不兼容


if hasattr(env, "_reset") and hasattr(env, "_step") and not getattr(env, "_gym_disable_underscore_compat", True):

前一个说是改版了 没有定义 reset啥的 所以我按照住址把false改成了true,但是还是报错找不到实现,看来源码写的有问题,或者跟这一版本不兼容