李宏毅DLHLP.04.Speech Recognition.2.• Connectionist Temporal Classification (CTC) and more
文章目录
- 介绍
- CTC模型
- CTC训练
- alignment
- 结果 略
- 结巴问题
- RNN Transducer (RNN-T)
- RNA
- RNN-T
- 解决alignment
- Neural Transducer
- 窗口大小
- MoChA
- 总结
介绍
本门课程是2020年李宏毅老师新课:Deep Learning for Human Language Processing(深度学习与人类语言处理)
课程网站:http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
B站视频:https://www.bilibili.com/video/BV1EE411g7Uk?t=222
公式输入请参考:在线Latex公式
本节介绍剩下四个seq2seq模型:
• Connectionist Temporal Classification (CTC)
• RNN Transducer (RNN-T)
• Neural Transducer
• Monotonic Chunkwise Attention (MoChA)
CTC模型
模型只有一个Encoder,这个Encoder是用单向的RNN的,因为如果使用双向RNN,意味着要看完整句话才能做识别,无法做实时识别。输入经过Encoder得到结果后,经过线性的分类器,得到token distribution,右边是线性分类器的结构。
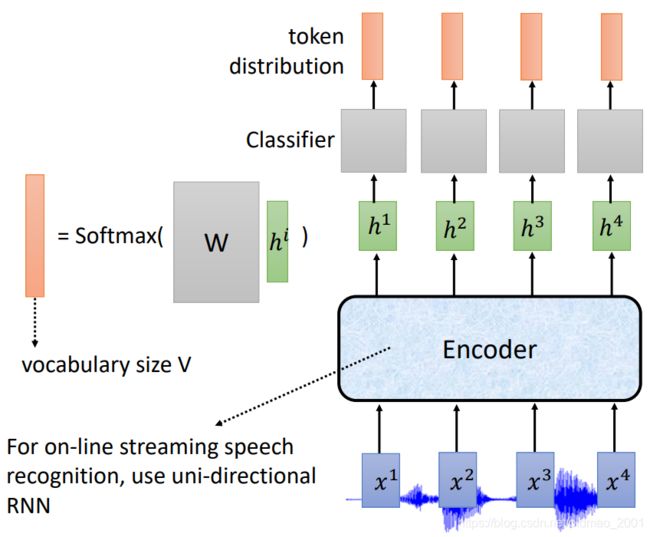
这里需要注意,由于是实时识别,所以encoder的输入acoustic feature会比较的密集,如此密集的acoustic feature不一定会和词对应起来,所以在线性分类器上,加了一个空 ϕ \phi ϕ,意思是当前的acoustic feature如果识别不了就先标记为 ϕ \phi ϕ,等到acoustic feature累积能够识别某个词为止。
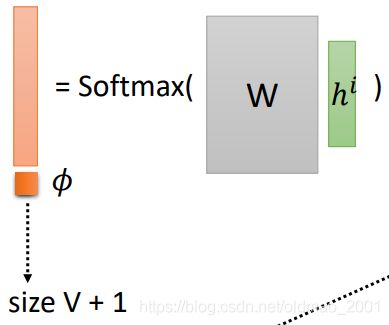
在处理输出的时候:
• Input T acoustic features, output T tokens (ignoring down sampling)
• Output tokens including ϕ \phi ϕ, merging duplicate tokens, removing ϕ \phi ϕ
看到空去掉,看到重复的合并
例如:

CTC训练
根据CTC的模型训练得到的结果按理要和ground truth做一对一的交叉熵,然后反向传播。
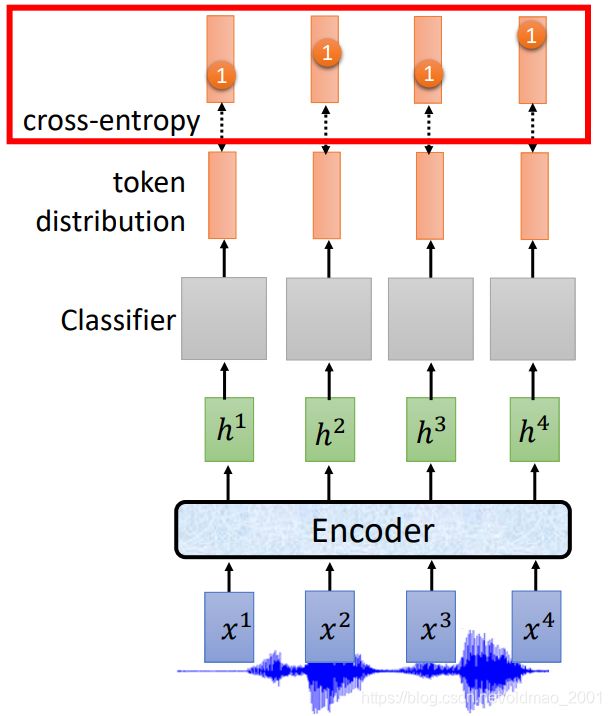
但是我们发现
声音的acoustic feature和ground truth不是一一对应的。例如下面输入四个acoustic feature,但是ground truth只有两个字符。

alignment
因此需要用到alignment的技术,把ground truth的两个字符变成:


至于如何穷举所有的alignment可能性,如何将同一个acoustic feature对应到多个alignment结果,这些下一小节讲。
结果 略
结巴问题
由于CTC只有一个encoder,Decoder部分实际上就是线性分类器来完成的。
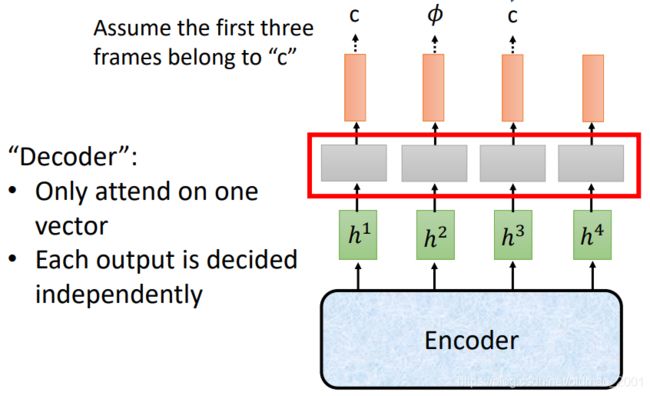
如上图所示,Decoder每次只处理一个acoustic feature,每个Decoder的输出是没有关联的。
假设现在前三个acoustic feature对应的token是【c】,那么本来最上面那里应该输出三个【c】才对,但是由于不知名原因导致了第二个Decoder得到结果是 ϕ \phi ϕ,那么按照CTC的标准:
看到空去掉,看到重复的合并
上面的【c ϕ \phi ϕc】的结果就是【cc】这个就是结巴了。
老师还给出了解决方案就是CTC和LAS的encoder并联后同时训练。
RNN Transducer (RNN-T)
RNA
Recurrent Neural Aligner
[ Sak, et al., INTERSPEECH’17]
上小节中的CTC Decoder: take one vector as input, output one token
RNA就是把CTC中的线性分类器换为LSTM,就搞定。每次都会看前个step的输出

上面的CTC和RNA都是吃一个输入,吐一个输出,我们想:Can one vector map to multiple tokens?
for example, 【th】只有一个音,【 θ \theta θ】但是想要模型听到【 θ \theta θ】输出两个字母。
简单解决方案是将【th】定为一个token,因为token是我们自己定义的。
但是我们希望模型更加的flexible,无论什么样的数据丢过来都可以识别,减少人工干预的部分。
这就是RNN-T模型
RNN-T
RNN-T模型是给定一个输入后,一直输出直到停止(出现 ϕ \phi ϕ表示输出完成,可以看下一个输入)。
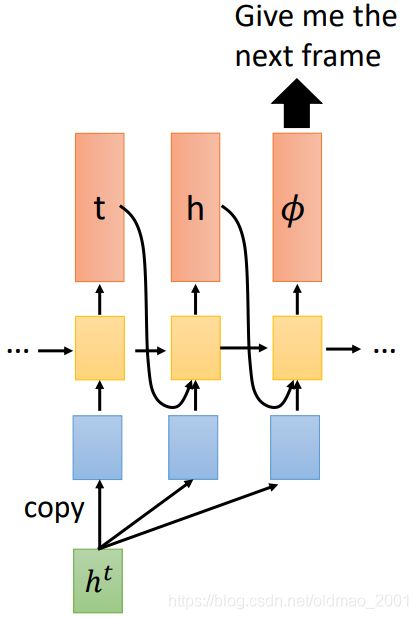
整个例子就是:
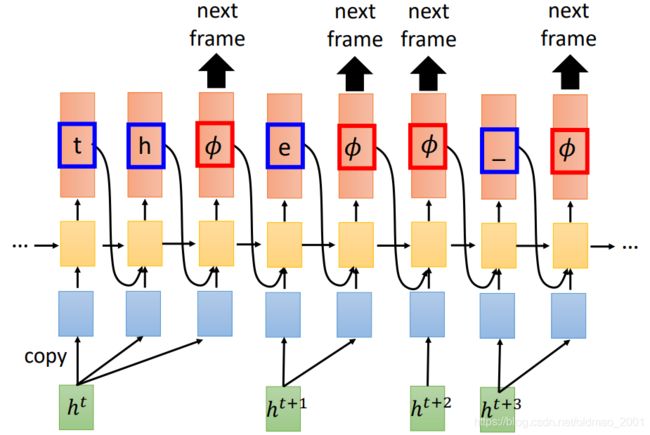
上图中【_】表示空格
由于每个输入都是以【 ϕ \phi ϕ】输出作为结尾,因此:There are T 【 ϕ \phi ϕ】 in the output.
这里注意RNN-T和CTC一样存在需要alignment问题。
例如:四个输入,两个输出

由于有四个输入,因此输出应该有四个【 ϕ \phi ϕ】

这样的组合还有很多种,All of them are used in training! (How?!)来看看如何做。
解决alignment
会在RNN-T模型上再加一个LM模型(这个不知道可以看下NLP训练营)然后用LM模型的输出接入到RNN-T模型中,这里需要注意LM模型如果碰到【 ϕ \phi ϕ】 则忽略
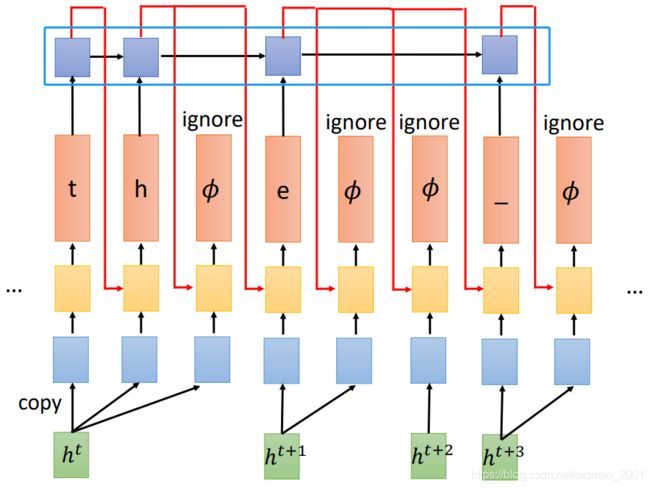
关于为什么忽略【 ϕ \phi ϕ】
• Language Model can train from text (easy to collect), no ϕ \phi ϕ in text. LM模型可以单独用文本直接训练,文本中本来就没有 ϕ \phi ϕ
• It is critical for training algorithm. 第二个原因是后面要对所有穷举输出进行处理,所以要忽略 ϕ \phi ϕ,这个在下一节讲。
Neural Transducer
前面的CTC, RNA, RNN-T模型都是每次只读一个acoustic feature,感觉效率较低,Neural Transducer一次读一把acoustic feature,然后再对窗口内的acoustic feature进行attention,由attention来决定要看那些acoustic feature:

模型如下,给定一个窗口的输入后,一直输出直到停止(出现 ϕ \phi ϕ表示输出完成,可以看下一个窗口的输入)。
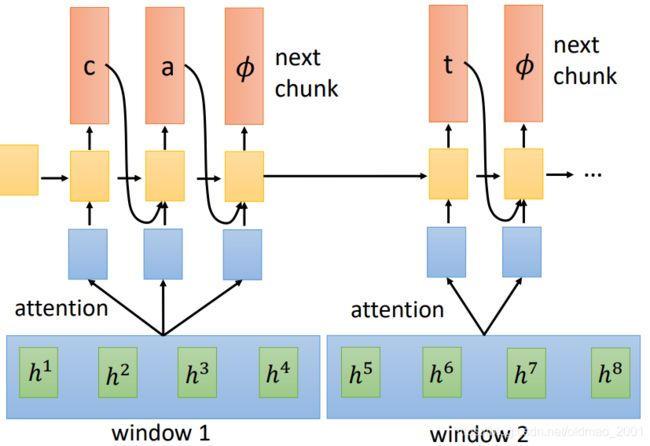
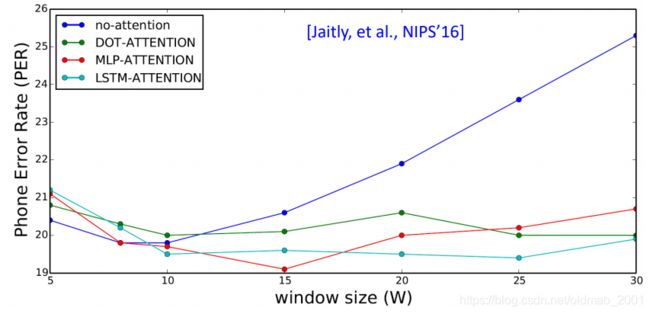
窗口大小
原文结果:横坐标是窗口大小
MoChA
Monotonic Chunkwise Attention
其思想主要是相对于Neural Transducer模型而言,引入了动态的window大小。类似attention的操作,吃两个向量,输出yes/no
yes表示window放这里
no表示window大小右移一位
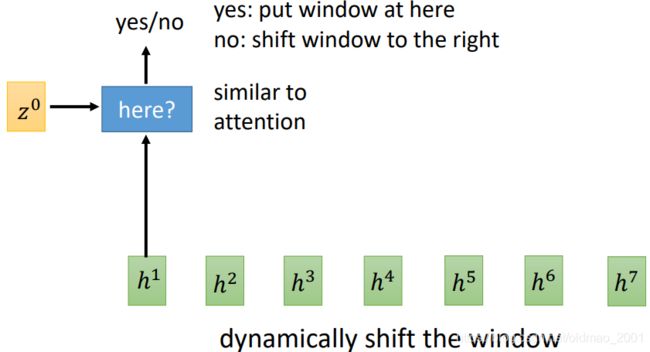
例如:

MoChA每次只会Decode一个token,这里没有【 ϕ \phi ϕ】

至于中间判断window的yes/no的地方无法求导,反向传播如何弄可以看原文。这块老师之前的课程里面也有讲:Improving Sequence Generation by GAN
总结
LAS: 就是 seq2seq
CTC: decoder 是 linear classifier 的 seq2seq
RNA: 输入一个东西就要输出一个东西的 seq2seq
RNN-T: 输入一个东西可以输出多个东西的 seq2seq
Neural Transducer: 每次输入一个 window 的 RNN-T
MoCha: window 移东伸缩自如的 Neural Transducer