hbase 写入数据有以下三种方式:
1.利用hbase提供的api写入
2.通过mr任务将数据写入
3.通过bulkload工具将数据写入
前两种写入方式在面对大数据量写入的时候效率会很低下,因为它们都是通过请求regionserver将数据写入,这期间数据会先写入memstore,memstore达到阈值后会刷写到磁盘生成hfile文件,hfile文件过多时会发生compaction,如果region大小过大时也会发生split。这些因素都会影响hbase数据写入的效率,因此在面临大数据写入时,这两种方式是不合适的。
而bulkload正好解决了这个问题,bulkload工具是将数据直接写入到hfile文件中,写入完毕后,通知hbase去加载这些hfile文件,因此可以避免上述耗时的因素,大大增加了数据写入的效率。下面就来讲述下如何利用bulkloan加载数据。
这里通过hbase shell创建一个person表,person表有两个列族分别为 "basic","social",结果如下图所示:

注:因为这里讲解的是bulkload加载数据,因此对于rowkey的设计没有做过多的处理
输入源为txt格式文件,格式类型如下所示:

这里通过mr任务生成hfile文件,再通过bulkload下载hfile到hbase中去,mr任务代码如下:
package com.zjc.spark;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* Created by zjc on 2018/12/26.
*/
public class sparkApplication10 {
public static class bulkLoadextends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {
String[] strs = value.toString().split(",");
String rowKey = strs[0];
ImmutableBytesWritable ibw =new ImmutableBytesWritable(Bytes.toBytes(rowKey));
Put put =new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes("basic"), Bytes.toBytes("name"), Bytes.toBytes(strs[1]));
put.addColumn(Bytes.toBytes("basic"), Bytes.toBytes("age"), Bytes.toBytes(strs[4]));
put.addColumn(Bytes.toBytes("basic"), Bytes.toBytes("birth"), Bytes.toBytes(strs[5]));
put.addColumn(Bytes.toBytes("social"), Bytes.toBytes("idnum"), Bytes.toBytes(strs[2]));
put.addColumn(Bytes.toBytes("social"), Bytes.toBytes("phone"), Bytes.toBytes(strs[3]));
put.addColumn(Bytes.toBytes("social"), Bytes.toBytes("sex"), Bytes.toBytes(strs[6]));
put.addColumn(Bytes.toBytes("social"), Bytes.toBytes("address"), Bytes.toBytes(strs[7]));
put.addColumn(Bytes.toBytes("social"), Bytes.toBytes("company"), Bytes.toBytes(strs[8]));
context.write(ibw, put);
}
}
public static Configurationconf =null;
public static Connectionconn =null;
public static Tablet =null;
public static RegionLocatorlocator =null;
public static Adminadmin =null;
static {
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "自个儿的zk地址");
}
public static void main(String[] args) {
try {
//获得hbase 表资源
conn = ConnectionFactory.createConnection(conf);
t =conn.getTable(TableName.valueOf("person"));
locator =conn.getRegionLocator(TableName.valueOf("person"));
admin =conn.getAdmin();
//定义一个mr job
Job job = Job.getInstance();
job.setJarByClass(sparkApplication10.class);
//定义map任务输出key value 类型
job.setMapperClass(sparkApplication10.bulkLoad.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
//定义输入输出文件格式类型
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(HFileOutputFormat2.class);
//定义输入输出文件路径
FileInputFormat.addInputPath(job, new Path("/test6/"));
FileOutputFormat.setOutputPath(job, new Path("/tmp/"));
//配置bulkLoad
HFileOutputFormat2.configureIncrementalLoad(job, t, locator);
boolean b = job.waitForCompletion(true);
//hbase 下载hfile文件
LoadIncrementalHFiles load =new LoadIncrementalHFiles(conf);
load.doBulkLoad(new Path("/tmp/"), admin, t, locator);
}catch (Exception e) {
System.out.println(e);
}finally {
//resources closed
}
}
}
然后将该项目打成一个jar包,将jar包提交到yarn运行,执行结果如下:
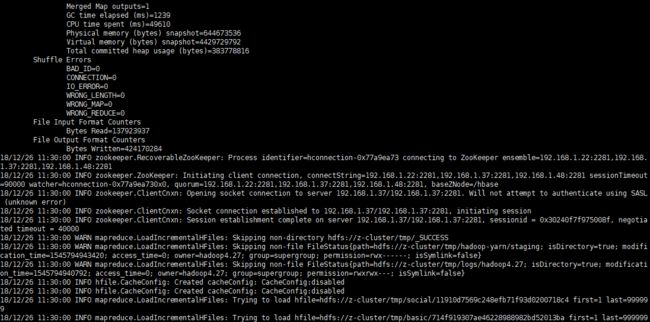
查看hbase shell 表中是否有导入的数据:
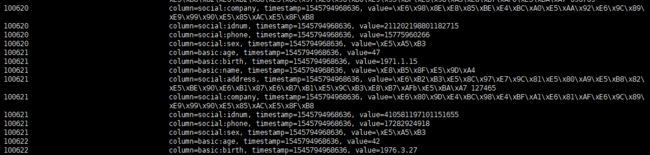
到此,数据导入成功,笔者亲测,7000w的数据量3台虚拟机默认配置导入到Hbase中仅花费40分钟不到。本篇文章中主要运用mr 任务将数据导入到hbase中,bulkload也支持spark导入,不过spark官方文档主要运用scala来实现的。等有机会的时候再研究研究java实现方式的。