1.什么是Hadoop
1.1 Hadoop历史渊源
Doug Cutting是Apache Lucene创始人, Apache Nutch项目开始于2002年,Apache Nutch是Apache Lucene项目的一部分。2005年Nutch所有主要算法均完成移植,用MapReduce和NDFS来运行。2006年2月,Nutch将MapReduce和NDFS移出Nutch形成Lucene一个子项目,命名Hadoop。
Hadoop不是缩写,而是虚构名。项目创建者Doug Cutting解释Hadoop的得名:“这个名字是我孩子给一个棕黄色的大象玩具命名的。我的命名标准就是简短,容易发音和拼写,没有太多的意义,并且不会被用于别处。小孩子恰恰是这方面的高手。”
1.2 狭义的Hadoop
个人认为,狭义的Hadoop指Apache下Hadoop子项目,该项目由以下模块组成:
- Hadoop Common: 一系列组件和接口,用于分布式文件系统和通用I/O
- Hadoop Distributed File System (HDFS?): 分布式文件系统
- Hadoop YARN: 一个任务调调和资源管理框架
- Hadoop MapReduce: 分布式数据处理编程模型,用于大规模数据集并行运算
狭义的Hadoop主要解决三个问题,提供HDFS解决分布式存储问题,提供YARN解决任务调度和资源管理问题,提供一种编程模型,让开发者可以进来编写代码做离线大数据处理。
1.3 广义的Hadoop
个人认为,广义的Hadoop指整个Hadoop生态圈,生态圈中包含各个子项目,每个子项目为了解决某种场合问题而生,主要组成如下图:
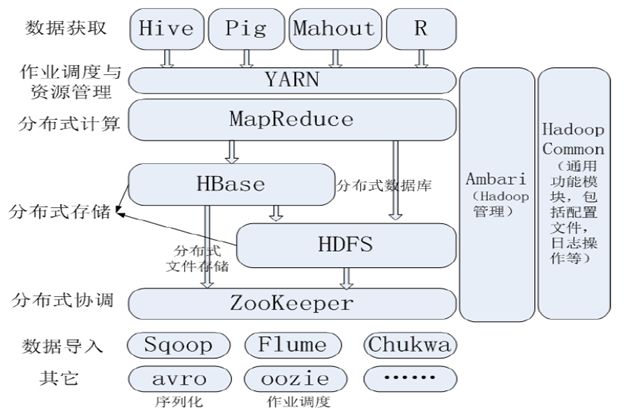
2.Hadoop集群部署两种集群部署方式
2.1 hadoop1.x和hadoop2.x都支持的namenode+secondarynamenode方式

2.2 仅hadoop2.x支持的active namenode+standby namenode方式

2.3 Hadoop官网关于集群方式介绍
1)单机Hadoop环境搭建
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/SingleCluster.html
2)集群方式
集群方式一(hadoop1.x和hadoop2.x都支持的namenode+secondarynamenode方式)
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-common/ClusterSetup.html
集群方式二(仅hadoop2.x支持的active namenode+standby namenode方式,也叫HADOOP HA方式),这种方式又将HDFS的HA和YARN的HA单独分开讲解。
HDFS HA(zookeeper+journalnode)http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
HDFS HA(zookeeper+NFS)http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailability
YARN HA(zookeeper)http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
生产环境多采用HDFS(zookeeper+journalnode)(active NameNode+standby NameNode+JournalNode+DFSZKFailoverController+DataNode)+YARN(zookeeper)(active ResourceManager+standby ResourceManager+NodeManager)方式,这里我讲解的是hadoop1.x和hadoop2.x都支持的namenode+secondarynamenode方式,这种方式主要用于学习实践,因为它需要的机器台数低,但存在namenode单节点问题
3.Hadoop安装
3.1 所需软件包
- JavaTM1.7.x,必须安装,建议选择Sun公司发行的Java版本。经验证目前hadoop2.7.1暂不支持jdk1.6,这里用的是jdk1.7,下载地址为:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
- ssh 必须安装并且保证 sshd一直运行,以便用Hadoop 脚本管理远端Hadoop守护进程。
- hadoop安装包下载地址:http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz
3.2 环境
- 操作系统: Red Hat Enterprise Linux Server release 5.8 (Tikanga)
- 主从服务器:Master 192.168.181.66 Slave1 192.168.88.21 Slave2 192.168.88.22
3.3 SSH免密码登录
首先需要在linux上安装SSH(因为Hadoop要通过SSH链接集群其他机器进行读写操作),请自行安装。Hadoop需要通过SSH登录到各个节点进行操作,我用的是hadoop用户,每台服务器都生成公钥,再合并到authorized_keys。
1.CentOS默认没有启动ssh无密登录,去掉/etc/ssh/sshd_config其中2行的注释,每台服务器都要设置。 修改前:

- #RSAAuthentication yes
- #PubkeyAuthentication yes
修改后(修改后需要执行service sshd restart):
- RSAAuthentication yes
- PubkeyAuthentication yes
后续请参考http://aperise.iteye.com/blog/2253544
3.4 安装JDK
Hadoop2.7需要JDK7,JDK1.6在Hadoop启动时候会报如下错误
- [hadoop@nmsc1 bin]# ./hdfs namenode -format
- Exception in thread "main" java.lang.UnsupportedClassVersionError: org/apache/hadoop/hdfs/server/namenode/NameNode : Unsupported major.minor version 51.0
- at java.lang.ClassLoader.defineClass1(Native Method)
- at java.lang.ClassLoader.defineClassCond(ClassLoader.java:631)
- at java.lang.ClassLoader.defineClass(ClassLoader.java:615)
- at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:141)
- at java.net.URLClassLoader.defineClass(URLClassLoader.java:283)
- at java.net.URLClassLoader.access$000(URLClassLoader.java:58)
- at java.net.URLClassLoader$1.run(URLClassLoader.java:197)
- at java.security.AccessController.doPrivileged(Native Method)
- at java.net.URLClassLoader.findClass(URLClassLoader.java:190)
- at java.lang.ClassLoader.loadClass(ClassLoader.java:306)
- at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:301)
- at java.lang.ClassLoader.loadClass(ClassLoader.java:247)
- Could not find the main class: org.apache.hadoop.hdfs.server.namenode.NameNode. Program will exit.
1.下载jdk-7u65-linux-x64.gz放置于/opt/java/jdk-7u65-linux-x64.gz.
2.解压,输入命令tar -zxvf jdk-7u65-linux-x64.gz.
3.编辑/etc/profile,在文件末尾追加如下内容
- export JAVA_HOME=/opt/java/jdk1.7.0_65
- export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
- export PATH=$PATH:$JAVA_HOME/bin
4.使配置生效,输入命令,source /etc/profile
5.输入命令java -version,检查JDK环境是否配置成功。
- [hadoop@nmsc2 java]# java -version
- java version "1.7.0_65"
- Java(TM) SE Runtime Environment (build 1.7.0_65-b17)
- Java HotSpot(TM) 64-Bit Server VM (build 24.65-b04, mixed mode)
- [hadoop@nmsc2 java]#
3.5 安装Hadoop2.7
1.只在master上下载hadoop-2.7.1.tar.gz并放置于/opt/hadoop-2.7.1.tar.gz.
2.解压,输入命令tar -xzvf hadoop-2.7.1.tar.gz.
3.在/home目录下创建数据存放的文件夹,hadoop/tmp、hadoop/hdfs、hadoop/hdfs/data、hadoop/hdfs/name.
4.配置/opt/hadoop-2.7.1/etc/hadoop目录下的core-site.xml
- xml version="1.0" encoding="UTF-8"?>
- xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <configuration>
- <property>
- <name>fs.trash.intervalname>
- <value>1440value>
- property>
- <property>
- <name>fs.defaultFSname>
- <value>hdfs://192.168.181.66:9000value>
- property>
- <property>
- <name>hadoop.tmp.dirname>
- <value>file:/home/hadoop/tmpvalue>
- property>
- <property>
- <name>io.file.buffer.sizename>
- <value>131072value>
- property>
- <property>
- <name>dfs.namenode.handler.countname>
- <value>200value>
- <description>The number of server threads for the namenode.description>
- property>
- <property>
- <name>dfs.datanode.handler.countname>
- <value>100value>
- <description>The number of server threads for the datanode.description>
- property>
- configuration>
- xml version="1.0" encoding="UTF-8"?>
- xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <configuration>
- <property>
- <name>dfs.namenode.name.dirname>
- <value>file:/home/hadoop/hdfs/namevalue>
- property>
- <property>
- <name>dfs.datanode.data.dirname>
- <value>file:/home/hadoop/hdfs/datavalue>
- property>
- <property>
- <name>dfs.replicationname>
- <value>3value>
- property>
- <property>
- <name>dfs.namenode.secondary.http-addressname>
- <value>192.168.181.66:9001value>
- property>
- <property>
- <name>dfs.client.socket-timeoutname>
- <value>600000/value>
- property>
- <property>
- <name>dfs.datanode.max.transfer.threadsname>
- <value>409600value>
- property>
- configuration>