mysql - 第3课 - 如何优化索引
注:当前测试mysql版本:mysql5.7,编码utf8mb4
注意:是否走索引是跟数据量有关的。
测试数据脚本:
DROP TABLE IF EXISTS `t_student`;
CREATE TABLE `t_student` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`std_name` varchar(30) NOT NULL,
`age` tinyint(3) unsigned NOT NULL,
`class_id` int(11) unsigned NOT NULL,
`gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `idx_std_age` (`age`),
KEY `idx_std_name_age_class` (`std_name`,`age`,`class_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1127 DEFAULT CHARSET=utf8mb4;
DROP TABLE IF EXISTS `t_class`;
CREATE TABLE `t_class` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`class_name` varchar(30) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_class_class_name` (`class_name`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4;
INSERT INTO `t_student` VALUES (1, 'Li Lei', 18, 1, '2020-7-23 23:32:07');
INSERT INTO `t_student` VALUES (2, 'Han Mei', 17, 1, '2020-7-23 23:32:10');
INSERT INTO `t_student` VALUES (3, 'Poli', 18, 2, '2020-7-23 23:32:13');
INSERT INTO `t_student` VALUES (1125, 'Li Lei_997', 17, 1, '2020-7-24 07:17:02');
INSERT INTO `t_student` VALUES (1126, 'Han Mei_998', 16, 1, '2020-7-24 07:17:02');
INSERT INTO `t_class` VALUES (1, 'class 1');
INSERT INTO `t_class` VALUES (2, 'class 2');全值匹配
explain select * from t_student t where t.age = '18';

最左前缀法则
用组合索引的时候,从最左边的索引开始匹配,中间如果断了就不能生效。
建立 std_name,age,class_id 组合索引,该组合索引相当于建立了以下3个索引
1.std_name
2.std_name,age
3.std_name,age,class_id
例:
1.explain select * from t_student t where t.std_name='Li Lei';

可以看到索引生效,从key_len推算只走了std_name一个字段匹配索引。我的数据库编码为utf8mb4,每个字符占用4个字节,std_name长度为30,另外需要2个字节记录字符串长度,所以是30*4+2=122。
2.explain select * from t_student t where t.std_name='Li Lei' and t.age=18;

根据上面的推算方法,多了一个age的索引,age使用tinyint,占用1个字节,所以是(30*4+2)+1=123,由此推断走了std_name,age两个索引字段匹配。
3.explain select * from t_student t where t.std_name='Li Lei' and t.age=18 and class_id=1;

同上面的推算方法。这次多了一个class_id的字段走索引,class_id使用int类型占4个字节。所以是(30*4+2)+1+4=127。由此推算走了3个字段匹配索引。
4.如果组合索引中间断了就不符合最左前缀匹配原则。例:
explain select * from t_student t where t.std_name='Li Lei' and class_id=1;

5.使用范围查询同样不符合最左前缀匹配原则。例:
explain select * from t_student t where t.std_name='Li Lei' and age>20 and class_id=1;

6.最左前缀匹配原则同样适用于字符串的比较。
- 模糊查询的时候%放后面是可以走索引的。例:
explain select * from t_student t where t.std_name like 'Li%';

- 模糊查询%放前面就不能走索引查询
explain select * from t_student t where t.std_name like '%Li';

- 使用覆盖索引的时候会扫描整个索引树,比上面的全表扫描效率要高点。
explain select t.id,t.std_name from t_student t where t.std_name like '%Li%';
![]()
7.索引下推
like Li%其实就是用到了索引下推优化。
什么是索引下推?
对于例子中的组合索引(name_age_class),正常情况走最左匹配,explain select t.* from t_student t where t.std_name like 'Li Lei%' and age =17 and class_id=1;
正常情况下,这种sql只会模糊匹配std_name='Li Lei%'的条件,因为后面的age和class_id在索引树中已经无序了。
在mysql5.6之前,首先遍历组合索引,匹配 'Li Lei%' 找到主键id,然后拿主键id去主键索引里回表,回表的过程中匹配age和class_id字段。
在mysql5.6引入索引下推优化。首先遍历组合索引,在匹配 'Li Lei%' 的过程中过滤掉不符合条件的 age 和 class_id,拿着过滤后的索引和主键id去主键索引里回表,可以减少回表的次数
不要在索引字段上加任何操作,例如函数、计算、类型转换(包括隐式转换)
在索引字段加操作都会使索引失效。例:
1.EXPLAIN select * from t_student t where SUBSTR(t.std_name,1,2)='Li';

2.EXPLAIN select * from t_student t where t.age+1>17;

3.EXPLAIN select * from t_student t where DATE_FORMAT(t.gmt_create,'%Y-%m')='2020-07';

使用覆盖索引可以避免回表
覆盖索引:要查询的字段可以在一颗普通索引树上找到。
回表:当要查询的字段在一颗普通索引树上不满足时,需要普通索引树的叶子节点里找到主键索引值,然后带主键索引值到主键索引里找到其他数据。
1.EXPLAIN select t.id,t.std_name,t.age,t.class_id from t_student t where t.std_name='Li Lei' and t.age=18 and t.class_id=1;
![]()
这个查询在组合索引检索一次就能查出数据。这里查找四个字段:t.id,t.std_name,t.age,t.class_id ,其中t.std_name,t.age,t.class_id3个字段是组合索引,id值存储在子节点。所以可以走覆盖索引。
2.如果查询换成 select * from t_student t where t.std_name='Li Lei' and t.age=18 and t.class_id=1;
因为查询所有字段,组合索引不满足查询结果,所以这个sql查询需要两步。
第一步从组合索引找到主键索引的值,这里也就是id值。
第二步把id值从主键索引里匹配到整行数据的值。
所以实际开发要避免使用 select *
使用不等于(!=或<>)匹配的时候会导致不走索引
explain select * from t_student t where t.age<>18;

在索引字段上使用is null或者is not null会走索引吗?
很多人说不能走索引,也有些人说要看版本。
我这里把表字段std_name , age, class_id三个列临时改为允许为空。

1.EXPLAIN select * from t_student t where t.std_name is null and t.age=18 and t.class_id=2;

为啥key_len的值为130?
因为把字段的列改为了允许为空,这时候会用一个字节记录该字段值是否为空。
所以key_len:(30*4+1+2) + (1+1) + (4+1) = 130
所以推算是走了组合索引3个字段。
再来看is not null
EXPLAIN select * from t_student t where t.std_name is not null and t.age=18 and t.class_id=2;
![]()
这里没走std_name的索引了(那个key_len=2是走的age独立的索引,age类型tinyint占用1个字节,另外需要1个字字节记录是否为空,所以是2字节)。
2.我们再把三个字段值都设置为不允许为空

EXPLAIN select * from t_student t where t.std_name is null and t.age=18 and t.class_id=2;

索引设置为不允许为null后,使用is null条件不走索引
EXPLAIN select * from t_student t where t.std_name is not null and t.age=18 and t.class_id=2;

使用 is not null同样不走索引(那个key_len=1是走的age独立的索引,因为字段不为空,所以不需要多出1个字节记录是否为空,所以占用1字节)。
结论:1.使用is not null的时候是肯定不走索引的。
2.使用is null的时候,当索引列设置为允许为空的时候走索引,当索引列设置为不允许为空的时候不走索引。
字符串不加单引号索引失效

少用 or 或者 in
- 用or或者in的时候mysql不一定使用索引,优化器会根据索引比例、表大小等多个因素评估是否走索引。
in和or在表数据量比较大的情况会走索引,在表记录不多的情况下会选择全表扫描
例:explain select * from t_student t where t.std_name in ('Li Lei', 'Han Mei');
explain select * from t_student t where t.std_name='Li Lei' or t.std_name='Han Mei';
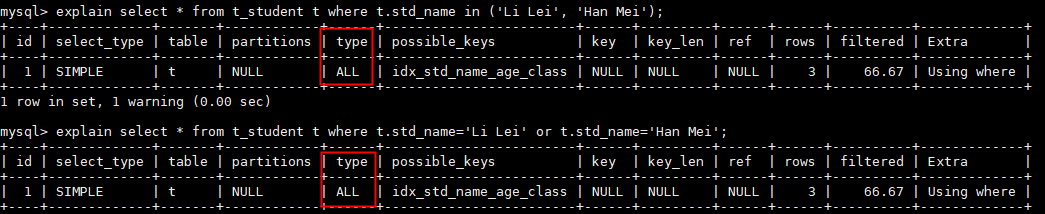
因为测试表数据量小,所以上面的in和or查询评估后进行了全表扫描,数据量小全表扫描也快。
现在我往表 t_student 里添加了1000条数据,再测试一下。

可以看到在在加大了数据量后,使用相同的sql,这次走了索引的。
强制走索引
我现在往表里添加了更多数据进行测试,脚本:
--添加测试数据的存储过程
drop procedure if exists proc_insert_student;
create procedure proc_insert_student()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into t_student(std_name,age,class_id) values(CONCAT('Li Lei',i), (i mod 120)+1 ,(i mod 3)+1);
set i=i+1;
end while;
end;
-- 执行存储过程
call proc_insert_student();explain select * from t_student t where t.std_name > 'Li Lei';

从看上图的possible_keys列可看到,优化器在分析的时候考虑过走 idx_std_name_age_class 的索引。但是考虑到第一点因为 std_name > 'Li Lei' 的扫描范围非常广,第二点因为走 idx_std_name_age_class 索引还需要回表, 不一定比全表扫描效率高,所以mysql最终选择了全表扫描,没有走索引。
接下来我们测试一下强制走索引的效果。在表后面加 force index 就能强制走索引。
explain select * from t_student t force index(idx_std_name_age_class) where t.std_name > 'Li Lei';
![]()
我们看到强制走索引后,现在走了索引范围扫描,并且返回的行比之前少了一半。
但是需要注意,虽然走了索引,但是查询效率不一定比全表扫描高,因为回表效率不高。我们一般还是按mysql默认的方案。
我们可以关闭查询缓存进行测试:
-- 关闭查询缓存
set global query_cache_size=0;
set global query_cache_type=0;
-- 执行时间:0.23s
select * from t_student t where t.std_name > 'Li Lei';
-- 执行时间:0.41s
select * from t_student t force index(idx_std_name_age_class) where t.std_name > 'Li Lei';总结:mysql默认为我们选择好了最佳方案,强制走索引一般情况下效率并不高,除非在自己能判定mysql分析不正确的情况下使用。
优化方案:使用覆盖索引,可以达到走索引的目的。例:
-- 执行时间:0.11S
select t.id,t.std_name,t.age,t.class_id from t_student t where t.std_name > 'Li Lei';![]()
索引优化总结
- 代码先行,索引后上。
先把主体业务代码开发完成,然后根据相关表的sql设计索引。 - 联合索引注意遵循最左前缀法则、尽量覆盖条件。
尽量少建单值索引,让联合索引的的每个字段尽量包含sql里的where、order by、group by字段,确保联合索引字段的顺序满足最左匹配原则。 - 索引不是越多越好。
索引多了会增加写数据的性能损耗,因为每次写数据都要调整索引。 - 模糊查询 % 不能写在最前面
- 不要在索引字段上加函数、计算、隐式转换
- 使用覆盖索引可以避免回表,提高效率
- 长字符串可以建立前缀索引
索引每个节点默认16k大小,如果一个索引字段占用太多空间,那么索引每个节点存的值就会更小。前缀索引例:index(name(20),age)。 - where与order by冲突时优先where
在设计索引顺序时遇到where和 order by 冲突时优先where,因为先执行where后排序。 - 数字类型索引效率比字符串索引高
因为字符类型方便比较大小,字符串类型需要转ascci码逐个字符比较大小。 - 推荐主键索引使用数字自增。
数字字段做主键便于排序,在更新索引树时只用在后面追加。字符串索引每次新增都需要调整索引树。 - 值分布稀少的字段不适合建立索引,比如“性别”字段。
- 不要建立外键约束,由程序约束。
- 有唯一值需求的要建立UNIQUE索引。